[논문 Review] 21. Deepseek LLM
각종 최신 기법 & 메모리 절약을 통해 OpenAI 성능을 따라잡자!
https://arxiv.org/abs/2401.02954
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
The rapid development of open-source large language models (LLMs) has been truly remarkable. However, the scaling law described in previous literature presents varying conclusions, which casts a dark cloud over scaling LLMs. We delve into the study of scal
arxiv.org
요즘 핫한 모델을 가져와봤다.
주식 시장에서는 '딥시크 쇼크'라고도 불린다던데 ... 확실히 GPT와 비교했을 때 놀랄만한 가격이긴 하다.
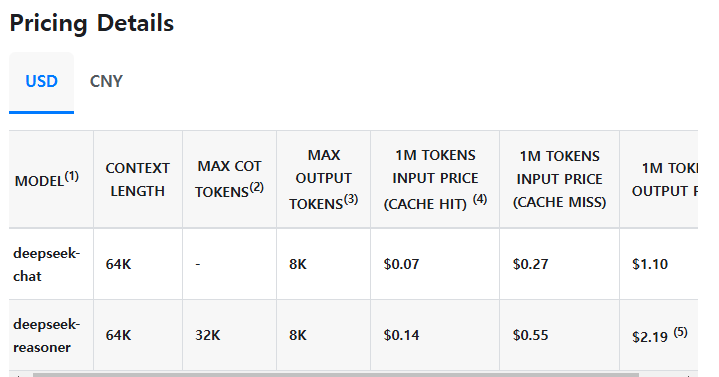

GPT batch처리를 하면 여기서 반값이 된다고 해도 상당한 가격차이이다.
특히 Realtime 처리를 한다고 가정하면... output에서 거의 5~10배의 가격차이이다.
이게 어떻게 가능했을지 궁금해서 논문을 잡게 되었다.
현재는 v2 버전까지 paper가 나온 것으로 알고 있는데, 너무 길어서 그 부분은 나중에...
0. Abstract
Scaling law에 따라 long-term perspective에서 오픈 소스 언어 모델을 발전시키는 프로젝트인 DeepSeek LLM을 소개한다.
Pre-training 을 위해 2T token 으로 이뤄진 데이터셋을 구축했고 확장 중에 있으며, DeepSeek LLM base model에 SFT (Supervised Fine-Tuning), DPO (Direct Preference Optimization) 을 적용하여 Deepseek-Chat 모델을 생성했다.
평가 결과, Deepseek-67B는 다양한 벤치마크 (특히 코드, 수학, 추론 영역) 에서 LLaMA2-70B를 능가했고 open-ended evaluation에서는 Deepseek-67B-chat 모델이 GPT-3.5를 능가했다.
1. Introduction
현재의 오픈소스 LLM 중 가장 뛰어난 성능을 보이는 LLaMA 시리즈 이후, 오픈 소스 커뮤니티는 주로 고정 크기 (7B, 13B, 34B, 70B) 의 모델을 훈련하는데 집중해왔다.
하지만 LLM Scaling Law에 대한 연구는 소홀히 되어왔는데, 현재의 LLM들이 AGI의 초기 단계에 불과하다는 점을 고려해봤을 때 *Scaling Law에 대한 향후 연구는 매우 중요하다.
여기서 Scaling Law를 다룬 이전 논문을 잠시 살펴보겠다.
About Scaling Law
인용된 논문은 2가지인데,
Scaling laws for neural language models (2020)
신경망 기반 LM의 성능이 모델 크기, 데이터셋 크기, 학습에 사용된 컴퓨팅 리소스에 따라 어떻게 스케일링 되는지에 대한 경험적 법칙에 대한 연구.
- 모델 성능은 Power-Law를 따르며, 다음과 같은 요인 관계가 존재한다.
- 모델 성능은 주로 스케일에 의해 결정됨
- 핵심 요인 : 모델 크기 (파라미터 수 N), 데이터 크기 (토큰 수 D), 연산량 (컴퓨팅 리소스 C)
- 특정한 아키텍처의 형태 (e.g. 넓은 네트워크 vs 깊은 네트워크) 는 상대적으로 영향이 적음
- 성능은 Power-Law를 따름
- 앞에서 언급한 핵심 요인 (N, D, C) 각각과의 관계에서 성능이 일정한 지수 법칙을 따름
(e.g. 모델 크기가 N배 증가하면 Loss가 $$N^{-\{alpha}N}$$ 의 형태로 감소)
- 앞에서 언급한 핵심 요인 (N, D, C) 각각과의 관계에서 성능이 일정한 지수 법칙을 따름
- 과적합의 일반적 특성
- N, D를 함께 증가시키면 일반적으로 성능이 계속 향상됨
- 그러나 D를 고정한 채 N만 증가시키면 일정 시점부터 성능 향상이 둔화됨
- 과적합 정도는 $$N^{0.73} / D$$ 로 예측 가능함
e.g. 모델 크기가 8배 증가하면 8^(0.73) = 4.65... 이기 때문에 D를 5배 정도 늘리면 과적합 방지 가능
- 학습 속도의 법칙
- 학습 곡선은 일정한 패턴을 따르며, 모델 크기와 관계 없이 초기 학습 과정을 보면 나중의 손실값을 예측할 수 있음
- 전이 학습 효과
- 훈련 데이터와 다른 분포의 데이터에서 평가할 때도 성능은 원래 학습 데이터에서의 성능과 일정한 offset을 가지고 있음
- 큰 모델이 작은 모델보다 데이터 효율성이 높음
- 더 큰 모델은 같은 성능을 달성하는 데 필요한 학습 스텝과 데이터 수가 적음
- 컴퓨팅 효율적 학습 전략
- 일정한 컴퓨팅 리소스가 주어지면, 큰 모델을 상대적으로 적은 데이터로 학습하고 Early stopping 하는 것이 최적의 전략 → 연산량 대비 성능이 더 좋음
- 모델 성능은 주로 스케일에 의해 결정됨
Training compute-optimal large language models (2022) [Chinchilla]
고정된 연산 자원(컴퓨팅 예산) 내에서 가장 최적의 언어 모델을 훈련하는 방법을 연구.
- 이전 연구에서는 모델 크기를 늘리는데 집중했지만, 여기서는 모델 크기와 학습 데이터(토큰 수)를 균형 있게 증가시키는 것이 더 효과적이라는 발견을 제시
- 현재의 LLM은 Under fitting 되었음
- 기존에는 모델 크기를 증가시키는 것이 성능 향상의 핵심이라고 여겨졌으나, 훈련 데이터(토큰 수)의 증가가 부족했음
- 모델 크기와 학습 데이터는 같은 비율로 증가해야 함
- 모델 크기를 2배로 늘리면, 학습 데이터(토큰 수도) 2배로 늘려야 최적의 성능을 발휘
e.g. Gopher 모델 (280B) 는 300B 개 토큰으로 학습되었지만, 실제로는 4배 더 많은 데이터로 학습되어야 더 나은 성능을 보일 수 있음
- 모델 크기를 2배로 늘리면, 학습 데이터(토큰 수도) 2배로 늘려야 최적의 성능을 발휘
- Chinchilla (70B) 모델 제시
- 동일한 컴퓨팅 예산을 사용하여 Gopher(280B)보다 4배 작은 모델(Chinchilla, 70B)을 4배 더 많은 데이터(1.4T 토큰)로 학습
- 그랬더니 다른 모델들보다 모든 벤치마크에서 성능이 우수했음
- 모델 크기가 작아지면 추가적인 이점들이 존재
- 추론 및 파인튜닝 비용이 대폭 감소
- 더 작은 모델이므로 하드웨어 요구사항이 낮아짐
- 실제 응용 및 배포가 용이해짐
위 2개 논문은 시간 여유가 있을 때 추가적으로 포스팅해보도록 하겠다.
본 논문에서는 이전 연구에 이어 모델, 데이터에 대한 확장 뿐만 아니라 하이퍼파라미터에 대한 논의도 다루고, 최적의 모델/데이터 scale-up 전략을 설정한 후 대규모 모델의 예상 성능을 예측한다.
2. Pre-Training
2.1 Data
데이터셋의 풍부함과 다양성을 향상시키기 위해 deduplication, filtering, remixing 3가지 단계를 수행했다.
- Deduplication : 고유한 인스턴스를 샘플링하여 데이터의 다양한 표현 보장
- Filtering : 정보 밀도를 높여 보다 효율적이고 효과적인 모델 학습 보장
- Remixing : 데이터 불균형을 해결하기 위해 과소 대표되는 도메인의 존재감을 늘림
→ 다양한 관점과 정보가 대표되도록하여 균형잡힌 포괄적 데이터셋을 만들고자 함
이 때 Common Crawl corpus 데이터셋에서의 중복 제거를 더욱 효과적으로 하기 위해, single dump에서의 중복제거를 하는 것이 아니라 사용한 전체 dump에서의 중복 제거를 진행했다.

Dump는 Common Crawl이 특정 시점에 크롤링한 웹 데이터 모음
Tokenizer
- BBPE (Byte-level Byte-Pair) 기반 알고리즘
- Pre-tokenization : 특정 문자 유형이 합쳐지는 것을 방지
- \n, 구두점 (, . ? !) 등이 앞뒤 단어와 합쳐지는 것을 방지함 → 보다 일관된 토큰화 결과
- 중국어, 일본어, 한국어 (CJK) 를 독립적으로 유지 (GPT-2 방식과 유사)
- 띄어쓰기가 없거나 불규칙적이므로, CJK 문자를 따로 구분하여 BPE 적용하면 더욱 효율적인 토큰화 수행 가능
- 예를 들어, "学习人工智能" (인공지능을 배우다) 같은 문장을 토큰화할 때:
- 영어식 BPE: ["学习", "人工", "智能"] → 의미 단위가 깨질 가능성이 높음.
- CJK-aware BPE: ["学习", "人工智能"] → 더 자연스러운 단위로 유지 가능.
- 숫자 토큰화 별도 처리
"2024"를 하나의 토큰으로 처리하는 것이 아니라, 개별 숫자("2", "0", "2", "4") 로 분리
→ LLaMA 모델에서도 적용된적 있음. 숫자 연산 처리에서 더 나은 성능을 기대
- 약 24GB의 Multilingual corpus에 의해 훈련됨
2.2 Architecture
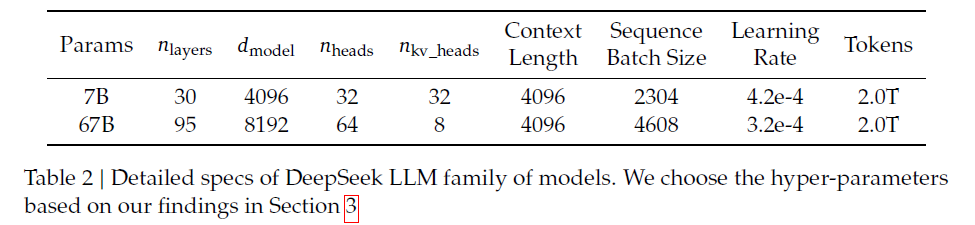
- LLaMA 구조를 따름
- Pre-Norm structure : RMSNorm
- FFN Activation : SwiGLU
- intermediate layer dimension : $$\frac{8}{3} d_{model}$$
- Positional Encoding : Rotary Position Embedding
- Grouped Query Attention
- Layer : 7B - 30개 / 67B : 95개
Rotary Embedding (RoPE)
https://arxiv.org/pdf/2104.09864
- Transformer 에서의 Positional Encoding을 개선하기 위함
기존의 절대적 위치 임베딩(Absolute Position Embedding) 및 상대적 위치 임베딩(Relative Position Embedding)의 한계를 보완하기 위해 개발
- 절대적 위치 임베딩
- Trainable : 위치 벡터 p_i를 학습 가능한 파라미터로 설정하여 모델이 최적의 위치 정보 표현을 학습하도록 함
→ 최대 시퀀스 길이 L에 따라 미리 정의된 위치 벡터가 필요하므로, 학습 시 설정된 L을 초과하는 시퀀스에 대해 일반화가 어려움
→ 사전 학습된 모델이 새로운 길이의 입력을 처리할 때 성능 저하 가능 - Sinusoidal : 각 차원에 대해 서로 다른 주파수의 사인/코사인 값을 사용하여 위치를 인코딩 (Transformer 원본 방식)
→ 위치 정보가 입력 임베딩에 직접 더해지는(additive) 방식이라, Attention Score 계산 시 상대적 위치 정보를 직접 반영하기 어려움
→ 상대적 거리(relative distance)에 대한 정보 부족 같은 단어라도 문장에서의 위치가 바뀌면 다른 값으로 표현
- Trainable : 위치 벡터 p_i를 학습 가능한 파라미터로 설정하여 모델이 최적의 위치 정보 표현을 학습하도록 함
- 상대적 위치 임베딩 : 토큰 간의 상대적 거리를 모델이 직접 학습하도록 유도하는 방식
- 상대적 위치 정보가 Attention Score에 추가되는 방식이므로, 여전히 선형 Self-Attention(Performer, Linformer 등)에 적용하기 어려움
- 여전히 추가적인 학습 가능한 파라미터가 필요하고, 최대 시퀀스 길이에 대한 제한이 존재
- 상대적 거리가 멀어질수록 정보가 급격히 감소하는 문제가 있음
- 절대적 위치 임베딩
- RoPE는 각 토큰의 임베딩을 특정 각도로 회전하는 방식으로 위치 정보를 부여
- 절대 위치 정보뿐만 아니라 상대적 거리 정보도 자연스럽게 반영되도록 설계
- 선형 Attention과도 호환 가능하여, 기존 상대적 위치 인코딩 방식의 단점을 보완
Grouped Query Attention
https://arxiv.org/abs/2305.13245
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Multi-query attention (MQA), which only uses a single key-value head, drastically speeds up decoder inference. However, MQA can lead to quality degradation, and moreover it may not be desirable to train a separate model just for faster inference. We (1) pr
arxiv.org
- 기존의 Multi-Head Attention (MHA)과 Multi-Query Attention (MQA) 사이의 절충안
- MHA
- 각 Query Head마다 별도의 Key-Value Head를 가짐
- 높은 품질을 유지하지만 메모리 대역폭과 연산량이 커서 디코딩 속도 느려짐
- MQA
- Query Head 여러 개가 하나의 Key-Value Head를 공유함
- 빠른 디코딩 속도를 제공하지만 모델 품질 저하 문제를 초래
- Grouped Query Attention (GQA)
- Query Heads를 G개의 그룹으로 나누고, 각 그룹이 하나의 Key Head, Value Head를 공유
- 그룹 개수 G에 따라 성능이 조절됨.
- G=1이면 MQA와 동일,
- G=H(전체 Query Head 개수)이면 MHA와 동일.
- MHA보다 빠르고, MQA보다 품질이 높음.
- MHA
2.3 Hyper parameter
- initialized: 표준편차 0.006
- Optimizer : AdamW (𝛽1 = 0.9, 𝛽2 = 0.95, and weight_decay = 0.1)
- LR Scheduler : multi-step learning rate scheduler
- warming-up : 2000 steps
- 워밍업 후 최대값 도달 → 80%의 토큰 처리 이후 최대값의 31.6%로 감소 → 90% 토큰 처리 이후 최대값의 10%로 더 감소
- warming-up : 2000 steps
- gradient cliping : 1.0
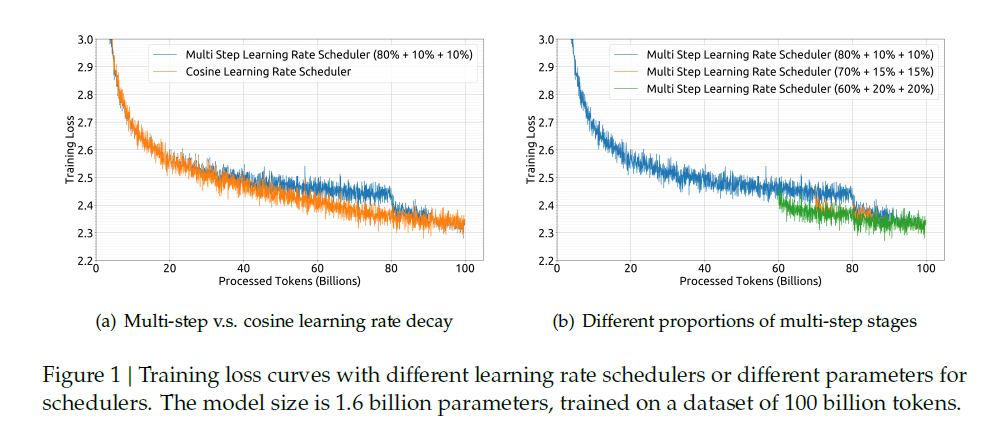
그림 (a)를 보면 최종 성능은 Cosine LR scheduler와 동일하다. 또한 그림 (b)에서 여러 단계의 비율 조정에 따라 더 나은 성능을 얻을 수 있다.
그렇다면 왜 Cosine LR 대신 Multi-step LR을 사용했을까?
- Cosine Decay Scheduler는 학습이 끝날수록 Learning Rate가 너무 작아져서 다시 학습을 이어가기 어려움
→ 학습 후반부에 Learning Rate가 거의 0에 가까워짐 (수렴)
→ 너무 작은 Learning Rate 때문에 새로운 데이터에 대한 학습이 거의 진행되지 않고, 수렴 속도가 매우 느려짐 - 반면, Multi-step Scheduler는 특정 단계에서만 LR을 급격히 줄이므로, 학습을 재개할 때 적절한 LR에서 시작할 수 있음
→ 새로운 데이터를 추가 학습하거나 Continual Learning 수행할 때 효과적
2.4 Infra
- HAI-LLM 프레임워크 사용
- Flash-attention
- https://arxiv.org/abs/2205.14135
- Transformer 모델의 Self-Attention 연산을 보다 빠르고 메모리 효율적으로 수행하기 위해 고안된 알고리즘
- I/O 최적화를 활용하여 메모리 접근 비용을 줄이고 연산 속도를 획기적으로 향상
- 하드웨어 활용도를 높이기 위함
- 효율적인 데이터 병렬 처리 & 오버헤드 최소화를 위한 ZeRo-1 & GEMM computation parallelism
- ZeRo-1
- ZeRO (Zero Redundancy Optimizer)는 모델 병렬 학습에서 GPU 메모리를 최적화하는 기법
- ZeRO-1 : Optimizer state Partitioning
- ZeRO-2 : Gradient Partitioning
- ZeRO-3 : Parameter Partitioning
- ZeRO-1(Optimizer State Partitioning)
- 각 GPU가 서로 다른 파라미터의 Optimizer 상태를 저장하여 메모리를 줄이는 방식
- 각 GPU가 옵티마이저 상태의 일부만 저장하고, 학습 과정에서 필요할 때만 다른 GPU에서 데이터를 공유
- 공유 과정에서 Reduce-Scatter 연산이 필요 : 각 GPU가 가지고 있는 그래디언트 정보를 다른 GPU들과 공유하고 분배하는 과정
- 계산 - 통신 간의 오버랩을 최적화하여 추가적인 대기 오버헤드 최소화
- 대규모 모델(LLM) 학습에서는 병렬 연산이 필수적
- 각 GPU/TPU 노드 간의 통신이 계산을 방해하면 학습 속도가 느려짐
- 통신(데이터 전송)이 끝날 때까지 계산이 대기(waiting)하면, 전체 학습 시간이 비효율적
- 계산과 통신을 최대한 겹치게(Overlap) 설계하여 대기 시간을 최소화하는 것이 중요
- 일반적으로 Backward Pass(역전파) 시, 마지막 Micro-Batch가 끝난 후에야 모든 그래디언트 계산이 완료됨
→ 마지막 Micro-Batch의 Backward가 끝날 때까지 GPU가 대기 - 마지막 Micro-Batch의 Backward가 끝나기 전에 통신을 먼저 시작
→ 일부 그래디언트를 미리 전송하여 계산과 겹치도록(Overlap) 설계
- ZeRO (Zero Redundancy Optimizer)는 모델 병렬 학습에서 GPU 메모리를 최적화하는 기법
이 ZeRO 부분은 Deepspeed 하면서 좀 더 자세히 다뤄보겠다.
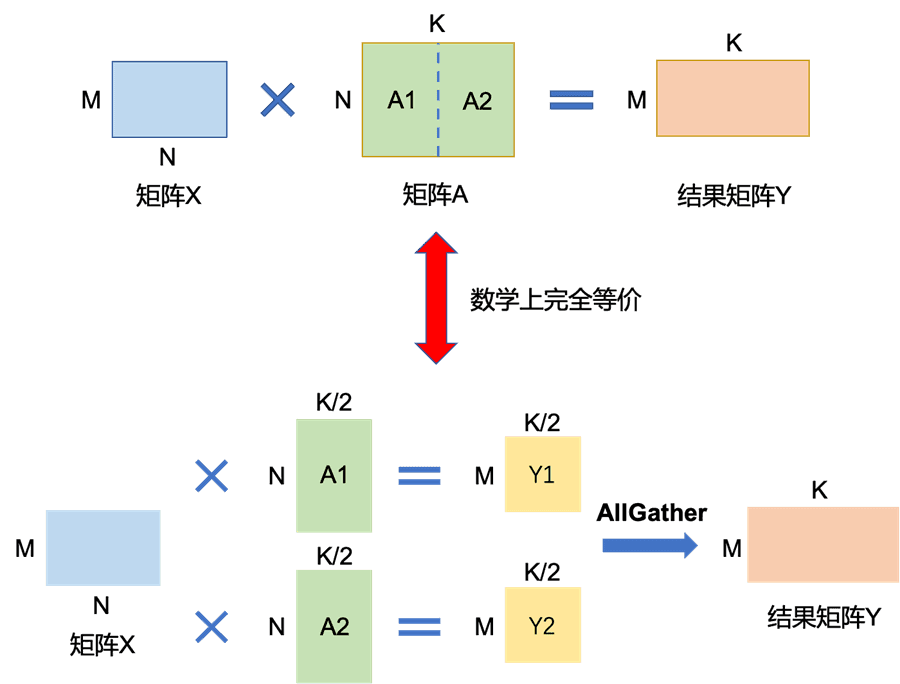
- GEMM (General Matrix-Matrix Multiplication)
- Self-Attention, Feed-Forward Network(FFN)에서 엄청난 행렬 연산(GEMM)이 발생
- 계산 부하를 줄이기 위해 Sequence Parallelism을 이용하여 입력 시퀀스를 여러 GPU에 나누어 연산
- 마찬가지로 All-Gather / Reduce-Scatter 같은 통신 연산이 필수적으로 발생 → 계산과 통신을 최대한 겹치게(Overlap) 설계하여 대기 시간을 최소화
- Training : bf16 / Accumulate gradient : fp32 precision
- In-place cross-entropy : GPU 메모리를 줄이기 위해 사용됨
3. Scaling Laws
스케일링 법칙에 대한 연구는 대규모 언어 모델이 등장하기 이전부터 진행되어 왔으나, 초기 연구에서는 최적의 모델 / 데이터 확장 할당 전략에 대해 다양한 결론을 보여 일반적인 적용 가능성에 의문이 제기되었다.
또한 하이퍼파라미터 설정에 대한 설명이 부족한 경우가 많았기에, 모델이 최적의 성능에 도달했는지 여부가 불확실했다.
이를 재검토하여 실험한 결과 요약은 다음과 같다.
- 하이퍼파라미터에 대한 Scaling Law 확립
- 모델 파라미터 (N) 대신 Non-embedding FLOPs/Token (M) 을 채택해 보다 정확한 전략과 Loss/성능 예측을 이끌어냄
- 사전 학습 데이터의 품질은 Model-data Scale-up 할당 전략에 영향을 미침
3.1 Scaling Laws for Hyperparameters
먼저 하이퍼파라미터의 스케일링 법칙을 연구했다.
다양한 컴퓨팅 예산 하에서 실험해본 결과, 경험적으로 학습 중 대부분의 파라미터 최적값은 컴퓨팅 예산을 변경해도 변하지 않는 것으로 드러났다.
그러나 성능에 가장 큰 영향을 미치는 하이퍼파라미터인 Batch size, Learning Rate는 재검토되었다.
컴퓨팅 예산 C와 최적의 Batch Size, Learning Rate 사이의 power law relationship을 모델링하였고, 이 방법론을 통해 다양한 컴퓨팅 예산의 모델이 최적의 성능에 도달할 수 있도록 보장한다.
- 컴퓨팅 예산이 1e17인 소규모 실험에서 BS, LR에 대한 Grid Search 수행

컴퓨팅 예산이 작은 경우 비교적 넓은 파라미터 공간에서 최적 성능을 달성할 수 있음
컴퓨팅 예산을 늘려가면서 Model Fitting을 진행한 결과,

- BS는 C가 증가함에 따라 함께 증가
- LR은 C가 증가함에 따라 점차 감소

그러나 최적의 하이퍼파라미터에 대한 컴퓨팅 예산 (C) 이외의 요인들 영향은 고려되지 않았다.
또한 컴퓨팅 예산은 동일하지만, 모델/데이터 할당이 다른 실험에서는 최적의 파라미터 공간이 약간씩 달라졌다.
이는 하이퍼파라미터의 선택과 training dynamics를 이해하기 위한 추가 연구가 필요하다는 것을 시사한다.
3.2 Estimating Optimal Model and Data Scaling
또한 Model - Data Scale 간의 스케일링 법칙을 연구했다.
$$N_{opt} ∝ C^a$$, $$D_{opt} ∝ C^b$$
- a : 모델 스케일링 지수
- b : 데이터 스케일링 지수
모델 스케일을 보다 정확하게 표현하기 위해 기존에 쓰던 표현인 모델 파라미터(N) 대신 non-embedding FLOPs/token (M)을 사용한다.
이와 함께 기존 연구에서 쓰이던 공식인 C = 6ND formula를 더 정확한 C=MD로 교체했다.
모델 파라미터 N은 Attention 계산 비용 오버헤드가 고려되지 않고, vocab computation이 포함되어 있어 모델 용량과 정확히 일치하지 않기 때문에 근사치 오차가 발생한다.
반면 새로 제안한 모델 척도 non-embedding FLOPs/token (M)은 Attention 연산에 대한 계산을 포함하고, vocab computation은 포함하지 않기 때문에 이전보다 더 정확히 표현 가능하다.
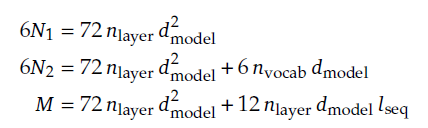
- n_layer : 레이어 수 / n_vocab : vocab 크기
- d : 모델 width
- l : 시퀀스 길이

분석 결과 N1, N2는 계산 비용을 과대 / 과소 평가하며 특히 소규모 모델에서 이러한 불일치가 두드러지게 나타났다.
이렇게 모델 척도를 M으로 정확히 추산한 다음, 컴퓨팅 예산 C = MD가 주어졌을 때 모델의 일반화 오차를 최소화하는 최적의 모델 / 데이터 규모를 찾는다.

실험 비용 등을 줄이기 위해 Chinichilla의 IsoFLOP profile approach를 사용하여 scaling curve를 fitting했다.
컴퓨팅 예산을 1e17 ~ 3e20 범위에서 세팅하고 각 예산에 대해 약 10개의 서로 다른 모델/데이터 스케일 할당을 줘봤다.
(이 때 하이퍼파라미터 세팅은 앞의 하이퍼파라미터 섹션에서 나온 공식에 따른다)
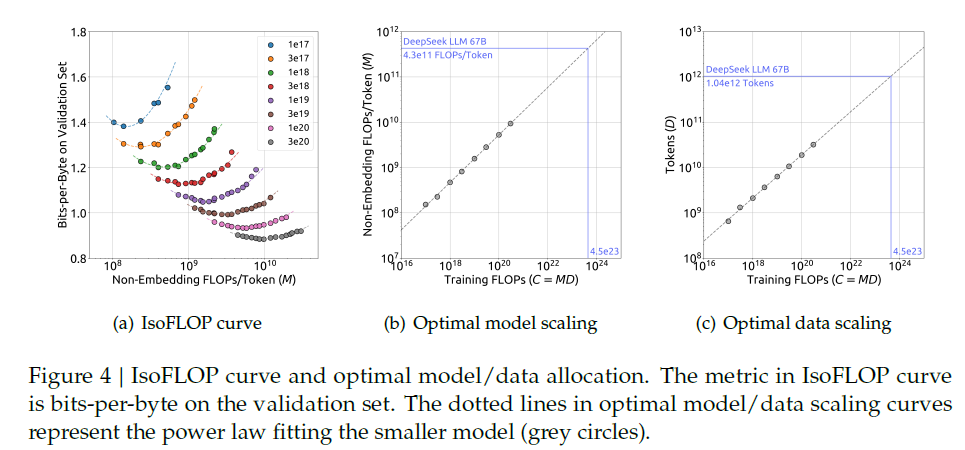
실험 결과에 따른 경험적 Optimal 공식은 다음과 같다.

컴퓨팅 예산 C와 일반화 오차에 따라 loss scaling curve를 fitting한 결과 Deepseek LLM 7B와 67B의 Loss 값을 예측할 수 있엇다.

3.3 Scaling Laws with Different Data
또한 여러 번의 실험을 거치며 데이터 품질이 Model - Data Scale-up 전략에 큰 영향을 미친다는 사실을 발견했다.
데이터 품질은 Early < Current < OpenWebText2 순서이다.
(참고로 평가 방식은 내부 데이터 평가 결과 - 라고만 서술되어 있다... OpenWebText2는 규모가 작아서 세심한 처리가 가능하기 때문에 품질이 더 좋다고 주장)
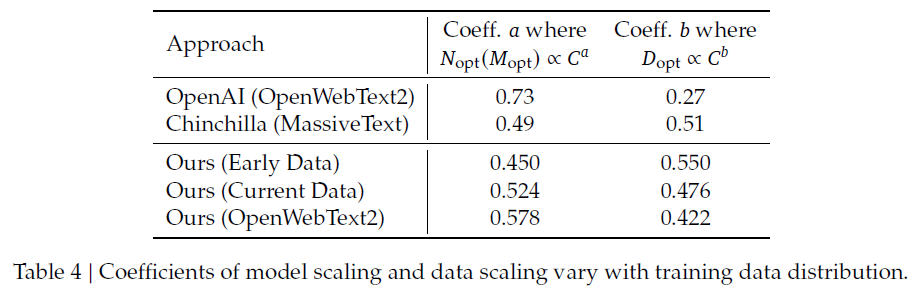
데이터의 품질이 좋다면 동일한 데이터 규모에서도 더 큰 규모의 모델을 학습시킬 수 있어 컴퓨팅 예산을 더 할당할 수 있는데, 실험 결과 값을 토대로 보면 데이터보다 모델에 컴퓨팅 예산을 더 많이 할당해야 한다는 것을 알 수 있다.
정리하면 다음과 같다.
- Early Data(품질 낮음)
- 모델 크기보다는 데이터 크기를 더 많이 증가시키는 것이 효과적.
- 즉, 데이터 품질이 낮으면 많은 데이터를 투입해야 학습 효과를 극대화 가능
- Current Data (품질 중간)
- 데이터 품질이 개선되자, 모델 크기 증가율이 더 커지고, 데이터 크기 증가율은 감소
- OpenWebText2(품질 높음)
- 데이터 품질이 가장 높은 경우, Compute Budget의 대부분을 모델 크기(MM) 증가에 사용하는 것이 최적
- 데이터가 깨끗할수록, 모델을 더 크게 만들면 성능이 더 많이 향상됨
즉 데이터 품질이 좋아지면, 모델을 키우는 것이 학습에 더 효과적이라는 의미이다.
4. Alignment
대략 1.5M 개의 영어, 중국어 instruction data instances를 수집했다.
1.2M의 helpful data / 3K의 safety data로 나뉘는데,
helpful data에는 General Language tasks (31.2%), Mathematical problems (46.6%), Coding exercise (22.2%) 태스크가 포함되어 있고 safety data는 300K개의 sensitive topic을 담은 instances가 존재한다.
파이프라인은 2가지 단계를 포함한다.
SFT (Supervised Fine-Tuning)
- 7B 모델에서는 4 epoch 학습을 진행했으나, 67B 모델에서는 overfitting 문제가 관찰되었기에 2 epoch만 학습
- LR : 7B 1e-5 / 67B 5e-6
벤치마크 정확도 모니터링 이외에도 Fine-tuning 과정에서 채팅 모델의 *반복 비율도 평가했다.
*반복 비율 : 응답 텍스트가 종료되지 않고 끝없이 반복 응답 생성되는 비율
- 수학 SFT 데이터 양이 증가함에 따라 반복 비율이 증가
→ 데이터셋 자체가 추론에서 유사한 패턴을 포함하기 때문
→ 작은 모델은 추론 패턴 파악에 어려움을 겪고 반복 응답을 뱉음 - 이 문제를 해결하기 위해 two-stage fine-tuning과 DPO를 적용했더니 문제가 개선되었음
DPO (Directed Preference Optimization)
https://arxiv.org/abs/2305.18290
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
While large-scale unsupervised language models (LMs) learn broad world knowledge and some reasoning skills, achieving precise control of their behavior is difficult due to the completely unsupervised nature of their training. Existing methods for gaining s
arxiv.org
- DPO는 기존 RLHF를 간소화한 방법으로, 기존의 강화학습을 사용하지 않고도 언어 모델을 인간의 선호도에 맞게 최적화할 수 있는 알고리즘
- 기존 RLHF 방식에서는 reward model을 학습한 후, 이를 이용해 강화학습을 수행하여 모델을 최적화
→ RL 과정은 보상 모델 학습, 샘플링, 하이퍼파라미터 조정 등이 필요해 계산적으로 부담이 크고 불안정 - DPO는 RL을 사용하지 않고, 간단한 분류(classification) 손실 함수만으로 RLHF 문제를 해결하는 방식
- 보상 모델을 명시적으로 학습하지 않고, 모델 자체가 암묵적인 보상 함수를 학습하도록 유도하는 것
- 보상 함수(reward function)와 최적 정책(optimal policy) 간의 관계식을 유도
- 보상 모델을 따로 학습할 필요 없이, 언어 모델 자체를 직접 최적화할 수 있도록 변경
- 기본 언어 모델(π_ref)의 확률과 새로운 모델(π_θ)의 확률 차이를 이용한 로지스틱 회귀(binary cross-entropy loss)를 통해 학습
- DPO 학습을 위한 선호도 데이터는 helpfulness / harmlessness 2가지 측면을 통해 구성되었는데,
helpfulness data는 창의적 글쓰기, 질문 답변, instruction following 등의 카테고리를 포함하는 다국어 프롬프트로 구성되어 있고 Deepseek-chat 모델을 통해 응답을 생성했다.
(Harmlessness data도 유사한 작업을 통해 구축되었다) - LR : 5e-6
- batch size : 512
- learning rate warmup
- cosine learning rate scheduler
DPO 훈련을 통해 모델의 open-ended generation skill을 향상시키면서도, 기존 벤치마크에 대한 성능 역시 거의 변화가 없음을 확인할 수 있었다.
5. Evaluation
5.1 Public Benchmark Evaluation
다음과 같은 공개 벤치마크(영어, 중국어)로 성능을 평가했다.
| Task | Dataset |
| Multi-subject multiple-choice | MMLU, C-Eval, CMMLU |
| Language understanding and reasoning | HellaSwag, PIQA, ARC, OpenBookQA, BBH |
| Closed-book question answering | TriviaQA, NaturalQuestions |
| Reading comprehension | RACE, DROP, C3 |
| Reference disambiguation | WinoGrande, CLUEWSC |
| Language modeling | Pile |
| Chinese understanding and culture | CHID, CCPM |
| Math | GSM8K, MATH, CMath |
| Code | HumanEval, MBPP |
| Standardized exams | AGIEval |
- perplexity-based evaluation
- 주어진 option 중에 답을 선택하는 태스크에 적용 (HellaSwag, PIQA, WinoGrande, ...)
- 모델이 다음 단어를 예측하는데 얼마나 확신이 있는지 평가
- generation-based evaluation
- 생성 태스크에 적용 (TriviaQA, GSM8K ...)
- Greedy-Decoding
- language-modeling-based evaluation
- 단순한 PPL 계산을 넘어 모델이 전체적인 언어 패턴을 얼마나 잘 학습했는지 평가 (Pile-test)
- Pile-test : 뉴스, 과학 논문, 코드, 위키피디아, 인터넷 포럼 등 다양한 도메인에서 수집된 텍스트를 포함
→ 모델이 특정 도메인에 편향되지 않고, 다양한 언어 패턴을 얼마나 잘 학습했는지를 평가
- Pile-test : 뉴스, 과학 논문, 코드, 위키피디아, 인터넷 포럼 등 다양한 도메인에서 수집된 텍스트를 포함
- test corpus에서 bits-per-byte (BPB) 를 측정
- BPB 값이 낮을수록 모델이 더 효율적으로 텍스트를 압축하고 학습하고 있음을 의미
- 단순한 PPL 계산을 넘어 모델이 전체적인 언어 패턴을 얼마나 잘 학습했는지 평가 (Pile-test)
5.1.1 Base Model
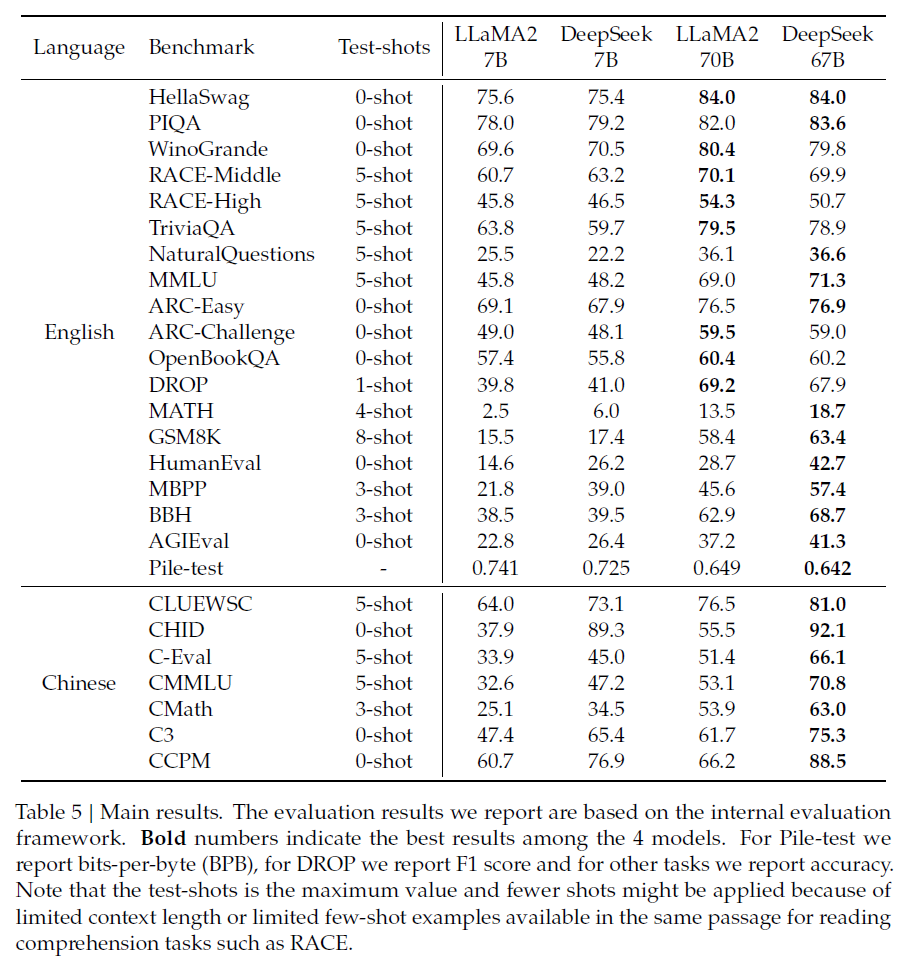
- 영어 이해 벤치마크에서 LLaMA2와 비슷한 성능을 보임
- MATH, GSM8K, HumanEval, MBPP, BBH, 중국어 벤치마크에서 LLaMA2보다 더 좋은 성능을 보임
- 모델 크기 확장에 따라 일부 성능 향상 → 대규모 모델의 강력한 few-shot 학습 능력에 기인
- 그러나 수학 데이터 비율이 증가하면 소규모 - 대규모 모델 간의 격차가 줄어들 수 있음
- LLaMA2 70B - Deepseek 67B 사이 성능 격차가 LLaMA2 7B - Deepseek 7B 보다 두드러짐
→ 소규모 모델일수록 언어 충돌 (Multilingual-based 학습) 의 영향력이 더 큼 - LLaMA2는 중국어 데이터에 대해 특별히 훈련되지 않았음에도 불구하고 CMath에서 안정적인 성능을 보임
→ 수학적 추론과 같은 기본 능력이 언어간에 효과적으로 전달될 수 있음 - 그러나 중국어 도메인 지식이 필요한 - 중국어 관용구 사용법을 평가하는 - CHID와 같은 태스크는 성능이 현저하게 떨어지는 것을 볼 수 있음
5.1.2 Chat Model
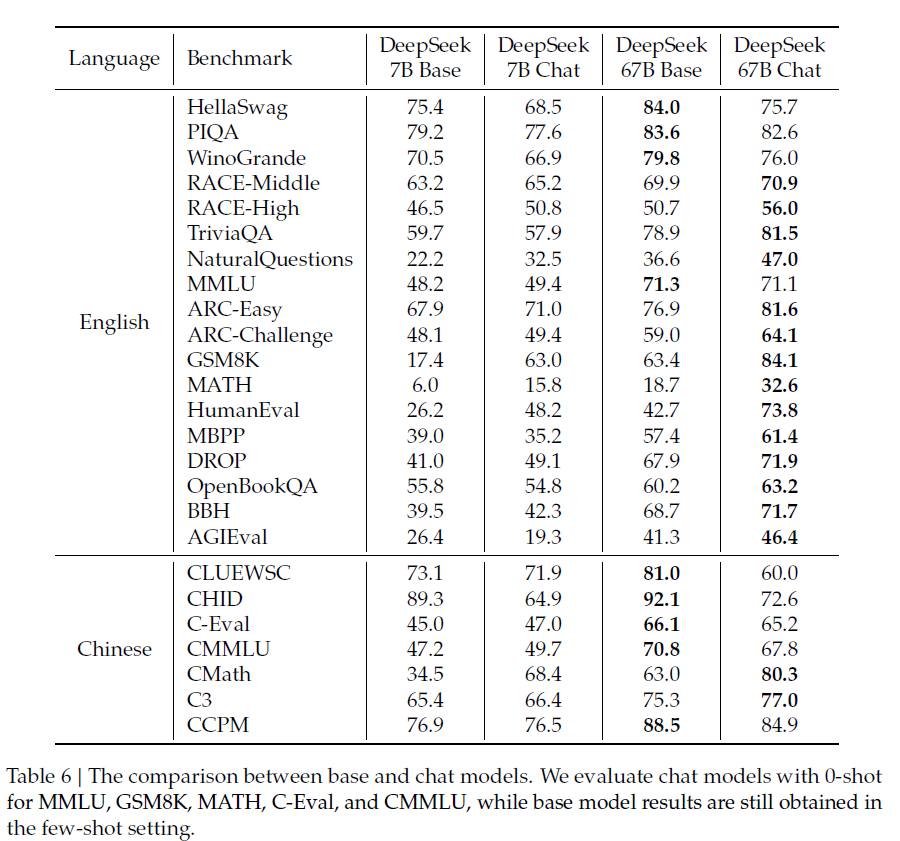
- 전반적인 성능 향상을 보였으나, 일부 태스크에서는 성능 저하가 일어남
- SFT 인스턴스 상당 부분이 CoT 형식이기 때문에, 추론 작업 (BBH, NQ) 에서 약간의 개선을 보임
- cloze task, 문장 완성 태스크 (E.g. HellaSwag) 는 오히려 SFT 이후 성능이 저하. 해당 태스크들은 순수 언어 모델이 더 잘 처리할 수 있음
- SFT 이후 Math & Coding task에서 상당한 개선을 보였는데, 이는 기본 모델이 처음에는 이러한 태스크에 적합하지 않았다가 SFT를 통해 코딩과 수학에 대한 추가 지식을 학습했기 때문이라고 추측
- 7B SFT는 2-stage로 이뤄짐
- 1 : 모든 데이터를 사용하여 모델 Fine tuning
- 2 : Math & Code를 제외한 나머지로 학습 → 반복 비율을 낮추기 위함
- 67B에서는 이미 1단계 SFT 이후 반복률이 1% 미만이므로 1-stage만 수행함
Appendix 부분에도 더 자세한 내용이 있으나 너무 길어져서 다음에 따로 다뤄보겠다.