이번에 국립국어원 대회에 참여하다보니, 현재 쓰고 있는 model.generate()에 대해서 보다 깊이 알아보고 싶어졌다.
generate() 는 각 프레임워크에 따라 구현된 클래스가 다르다고 한다.
- PyTorch generate() is implemented in GenerationMixin.
- TensorFlow generate() is implemented in TFGenerationMixin.
- Flax/JAX generate() is implemented in FlaxGenerationMixin.
우리의 모델은 PyTorch 로 구현되었으니, GenerationMixin에 구현된 generate method와 그 인자를 살펴보자.
class | GenerationMixin
transformer 라이브러리에 구현되어 있는 클래스 중 하나로, auto-regressive text generation에 필요한 함수를 포함하며 PretrainedModel과 함께 쓰일 수 있다.
method | generate()
핵심 decoding 방법들과, 설정해야 할 arguments에 대해서 알아보자.
greedy decoding
num_beams=1, do_sample=False -> generate() default settings
greedy decoding은 단순하게 현재 timestep에서 가장 확률이 높은 토큰 후보를 선택하는 것이다.

<장점>
- 가장 기본적, 직관적
- 시간/공간복잡도가 뛰어남
<단점>
- 1등, 2등 토큰 후보 확률의 차이가 미미할지라도, 무조건 1등 토큰 후보만 택함
-> 한 번이라도 틀린 예측이 나온다면 치명적
from transformers import AutoModelForCausalLM, AutoTokenizer
prompt = "I look forward to"
checkpoint = "distilbert/distilgpt2"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(checkpoint)
outputs = model.generate(**inputs)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
multinomial sampling
num_beams=1, do_sample=True
greedy decoding은 다음 토큰을 항상 1등 확률 토큰만 택하는 반면, multinomial에서는 전체 어휘에 대한 확률 분포를 기반으로 다음 토큰을 무작위 선택한다.
즉, 확률이 0이 아닌 모든 토큰은 선택될 가능성이 있다.
<장점>
- greedy decoding의 시간 복잡도는 가져가면서, 토큰의 다양성을 늘림 (토큰 무한 반복 위험성 줄임)
<단점>
- 엉뚱한 토큰도 선택될 가능성이 있음
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
set_seed(0) # For reproducibility
checkpoint = "openai-community/gpt2-large"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
prompt = "Today was an amazing day because"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, do_sample=True, num_beams=1, max_new_tokens=100)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
top-p, top-k sampling
do_sample=True, top_p<1, top_k != None
multinomial sampling에 제약 조건을 걸어준 버전.
- top-k : 모델이 예측한 다음 토큰 확률분포에서 확률값이 가장 높은 k개 토큰 가운데 선택
<k=6에서의 예시>
출처 : https://ratsgo.github.io/nlpbook/docs/generation/inference1/ - top-p : 확률값이 높은 순서대로 내림차순 정렬을 한 다음 누적 확률 값이 p 이하인 단어들 가운데 선택
<p=0.94에서의 예시>출처 : https://ratsgo.github.io/nlpbook/docs/generation/inference1/
beam-search decoding
num_beams>1, do_sample=False
greedy decoding에서 시간복잡도를 조금 포기하고, 여러 개의 후보군을 두어 greedy decoding에서의 단점을 보완하기 위한 방법론이다.
해당 timestep에서 가능성이 높은 beam K개를 골라 진행한다. 당연히 K=1로 두면 greedy decoding이 된다.

<장점>
- greedy decoding에서 놓친 시퀀스를 탐색 가능
<단점>
- K를 직접 설정해주어야 함
- greedy 보다 탐색 시간이 느림
▼ 이해가 어렵다면?
https://huggingface.co/spaces/m-ric/beam_search_visualizer
Beam Search Visualizer - a Hugging Face Space by m-ric
Running on Zero
huggingface.co
직접 GPT2의 beam search decoding을 시각화해볼 수 있는 툴이 있다. 신기해~

이런 식으로 토큰, 확률이 표시되며 상단에서 빔 개수, 페널티 등이 설정 가능하다.
from transformers import AutoModelForCausalLM, AutoTokenizer
prompt = "It is astonishing how one can"
checkpoint = "openai-community/gpt2-medium"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(checkpoint)
outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
beam-search multinomial sampling
num_beams>1, do_sample=True
beam search와 multinomial sampling을 결합
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
set_seed(0) # For reproducibility
prompt = "translate English to German: The house is wonderful."
checkpoint = "google-t5/t5-small"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
outputs = model.generate(**inputs, num_beams=5, do_sample=True)
tokenizer.decode(outputs[0], skip_special_tokens=True)
diverse beam-search decoding
num_beams>1, num_beam_groups>1
https://arxiv.org/pdf/1610.02424
-> 해당 논문에서 제안된 방식!
beam search의 확장으로, 더욱 다양한 빔 시퀀스 세트를 생성할 수 있다.
- 기존의 beam search는 여러 시퀀스를 병렬로 탐색 가능하지만, 생성된 시퀀스가 매우 유사하며 다양성이 부족함
- DBS는 probability 뿐만 아니라 다양성을 고려하는 항을 포함
- beam을 G개의 그룹으로 나눈 다음, 각 그룹에 대해 beam search를 수행하되 이전 그룹과의 불일치를 기반으로 다양성 페널티를 포함하도록 로그 확률을 수정

- number of groups (G) : 나눌 그룹 수 (= num_beam_groups)
- diversity strength (λ) : 다양성을 얼마나 강화할 지 (= diversity_penalty)
-> 높을수록 더 다양한 후보군을 생성하지만, 지나치게 높을 경우 모델 확률을 압도해 문법적으로 부정확해짐 - choice of diversity function (δ) : 어떤 식으로 다양성을 부여할 지
- 해밍 다양성 (Hamming Diversity): 이 형태는 이전 그룹에서 선택된 토큰의 선택을 이전에 선택된 횟수에 비례하여 페널티를 부과합니다.
- 누적 다양성 (Cumulative Diversity): 두 시퀀스가 충분히 다르게 분기된 후에는 동일한 단어를 동시에 사용할 수 없도록 제한하는 것이 불필요하고 해로울 수 있습니다. 다양성 페널티의 '백오프'를 인코딩하기 위해, 우리는 각 시간 단계에서 사용된 동일한 단어 수를 누적 다양성으로 도입합니다. 특히, δ(y[t], y^g_b,[t]) = exp{−( ∑_τ∈t ∑_b∈B′ I[y^h_b,τ ≠ y^g_b,τ])/Γ} 여기서 Γ는 누적 다양성 항목의 강도를 제어하는 온도 매개변수이고, I[·]는 지시자 함수입니다.
- n-그램 다양성 (n-gram Diversity): 현재 그룹은 이전 그룹과 동일한 n-그램을 생성하는 경우 페널티를 부과합니다. 이는 후보 시퀀스에서 각 n-그램이 이전 그룹에서 발생한 횟수에 비례합니다. 해밍 다양성과 달리 n-그램은 시퀀스의 높은 차수 구조를 포착합니다.
- 신경 임베딩 다양성 (Neural-embedding Diversity): 앞서 논의한 모든 다양성 함수는 정확한 일치를 수행하지만, Word2Vec과 같은 신경 임베딩은 동의어와 같은 의미론적으로 유사한 단어를 페널티 부과할 수 있습니다. 이는 해밍 또는 n-그램 메트릭의 소프트 버전을 사용하여 수행됩니다. n-그램 다양성과 함께 사용할 때 n-그램의 표현은 구성 단어의 벡터를 합산하여 얻습니다.
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
checkpoint = "google/pegasus-xsum"
prompt = (
"The Permaculture Design Principles are a set of universal design principles "
"that can be applied to any location, climate and culture, and they allow us to design "
"the most efficient and sustainable human habitation and food production systems. "
"Permaculture is a design system that encompasses a wide variety of disciplines, such "
"as ecology, landscape design, environmental science and energy conservation, and the "
"Permaculture design principles are drawn from these various disciplines. Each individual "
"design principle itself embodies a complete conceptual framework based on sound "
"scientific principles. When we bring all these separate principles together, we can "
"create a design system that both looks at whole systems, the parts that these systems "
"consist of, and how those parts interact with each other to create a complex, dynamic, "
"living system. Each design principle serves as a tool that allows us to integrate all "
"the separate parts of a design, referred to as elements, into a functional, synergistic, "
"whole system, where the elements harmoniously interact and work together in the most "
"efficient way possible."
)
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
tokenizer.decode(outputs[0], skip_special_tokens=True)
contrastive search
penalty_alpha>0, top_k>1
https://arxiv.org/abs/2202.06417
A Contrastive Framework for Neural Text Generation
Text generation is of great importance to many natural language processing applications. However, maximization-based decoding methods (e.g. beam search) of neural language models often lead to degenerate solutions -- the generated text is unnatural and con
arxiv.org
해당 논문에서 제안된 방식!
- beam search와 같은 maximization-based methods는 바람직하지 못한 반복을 포함하는 경향이 있다.
ex. 나는 학교에 갔는데 갔는데 갔는데... - 논문에서는 이러한 현상이 anisotropic distribution of token representations 때문이라고 한다.
-> 사전 학습된 언어 모델들이 뱉는 token representation이 의미와 관계 없이 전반적으로 모두 유사하기 때문
-> 토큰 유사도가 높을 경우, 모델이 매 스텝마다 반복적으로 같은 토큰을 생성할 수 있어서 바람직하지 않음
-> token similarity matrix의 sparseness를 보존하자! - SimCTG (a Simple Contrastive framework for neural Text Generation)
loss function에 contrastive learning 항을 추가해, 같은 토큰과의 유사도는 높게 / 다른 토큰과의 유사성을 낮추도록 학습 (토큰 유사도 = 코사인 유사도)
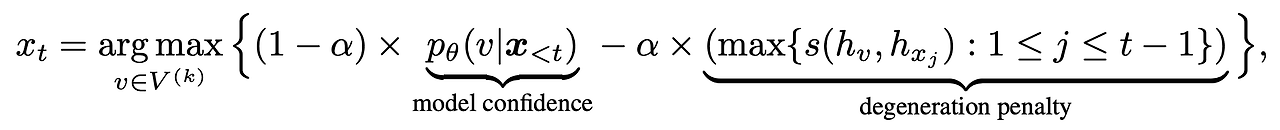
- v : k번째 스텝에서의 후보 토큰 집합
- model confidence : 이전 context가 주어졌을 때, 다음에 나올 토큰 확률
- degeneration penalty : 이전 step까지 나온 토큰의 유사도 중 최대값
-> 이전에 나온 토큰과 유사한 토큰이 나올 경우 패널티를 부여
greedy decoding과의 비교


- greedy decoding의 경우 비대각선에서 높은 유사도 나타남
-> 반복 생성된 토큰, 관련 없는 토큰끼리의 유사도 높음
- contrastive search의 경우 이러한 문제가 해결된 것을 볼 수 있음
<장점>
- 반복적이지 않고, 일관된 긴 출력을 생성하는 데 뛰어난 결과를 보여준다.
from transformers import AutoTokenizer, AutoModelForCausalLM
checkpoint = "openai-community/gpt2-large"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint)
prompt = "Hugging Face Company is"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, penalty_alpha=0.6, top_k=4, max_new_tokens=100)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
현재 우리 모델이 가지고 있는 문제점과 유사해서, 우선적으로 적용해보면 좋을 듯 합니다!
constrained beam-search decoding
constraints!=None or force_words_ids!=None
텍스트 생성 출력을 제어할 수 있게 해줌
-> 모델이 최종 출력에 포함해야 할 단어를 알려주자!
"is fast" 를 삽입하려 한다고 가정해보자.
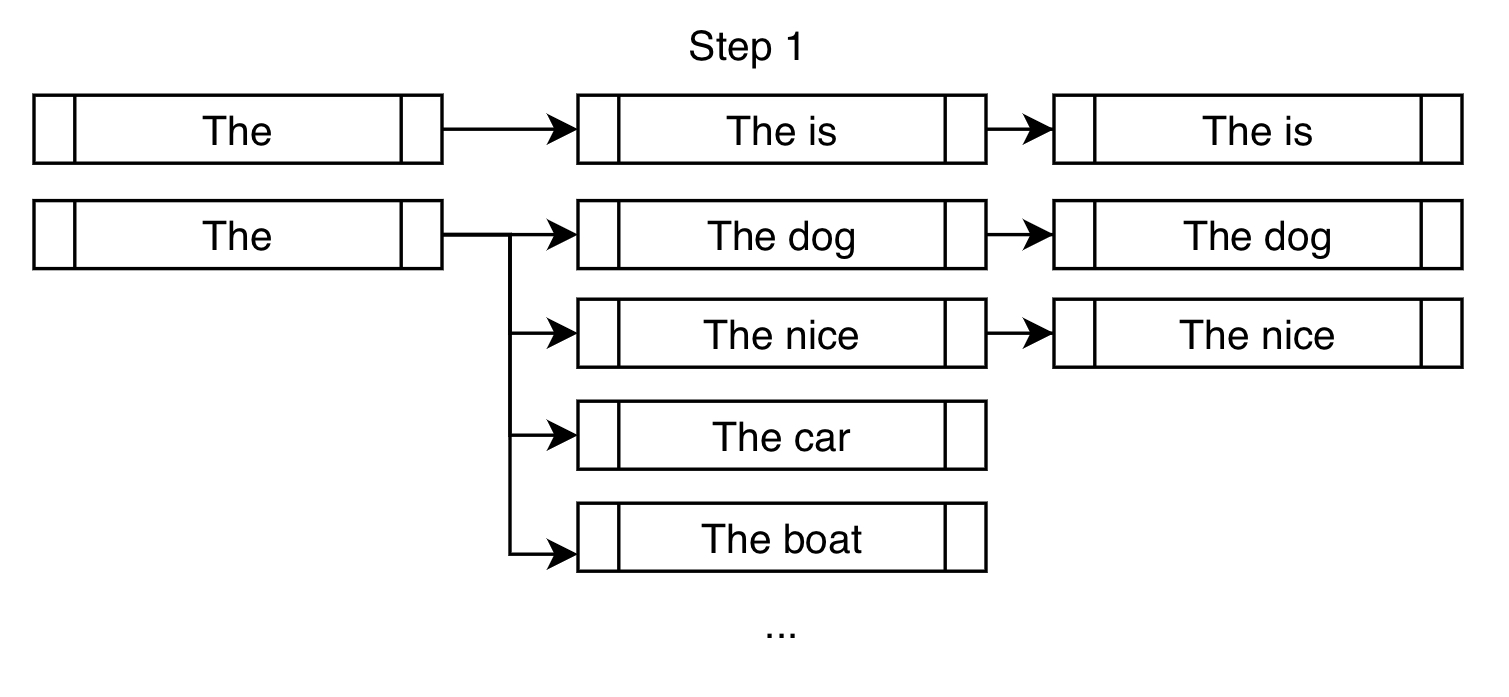
- 기존 빔 서치와 비슷하지만, 제약 조건을 충족하는 데에 더 가까워질 토큰을 추가한다
- 일반적으로 확률이 높은 dog, nice 가 beam search에서 선택된다
- 또한, constraint인 "is fast"에 가까워질 수 있도록 "is"를 다음 토큰으로 강제한다
- 그러나 무조건 다음 토큰을 강제할 경우, 이상한 문장이 출력된다
위에 있는 The is만 해도 문법적으로 이상하다!

- 따라서 모든 가능한 빔을 각각의 bank로 분류한 다음, round-robin selection을 이용해 가장 가능성 있는 출력을 선택하도록 한다
- bank2에서 첫 번째로 확률 높은 출력 선택
- bank1에서 첫 번째로 확률 높은 출력 선택
- bank0에서 첫 번째로 확률 높은 출력 선택
- bank2에서 두 번째로 확률 높은 출력 선택
...
- 이를 통해 constraint 문구를 최종 출력에 넣으면서도, 가장 그럴듯한 출력을 선택할 수 있다
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, PhrasalConstraint
tokenizer = AutoTokenizer.from_pretrained("t5-base")
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
encoder_input_str = "translate English to German: How old are you?"
constraints = [
PhrasalConstraint(
tokenizer("Sie", add_special_tokens=False).input_ids
)
]
input_ids = tokenizer(encoder_input_str, return_tensors="pt").input_ids
outputs = model.generate(
input_ids,
constraints=constraints,
num_beams=10,
num_return_sequences=1,
no_repeat_ngram_size=1,
remove_invalid_values=True,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
assisted decoding (=speculative decoding)
assistant_model != None or prompt_lookup_num_tokens != None
https://arxiv.org/pdf/2211.17192
-> 해당 논문에서 나온 방법론!
- 동일한 토크나이저를 사용하는 보조 모델 (보통 원래 모델보다 훨씬 작은 모델) 을 사용해 몇 개의 후보 토큰을 생성한다.
- main model이 forward pass에서 후보 토큰을 검증해 decoding process를 가속화
- 현재 greedy search, sampling만 지원 가능
- batch input을 지원하지 않음
from transformers import AutoModelForCausalLM, AutoTokenizer
prompt = "Alice and Bob"
checkpoint = "EleutherAI/pythia-1.4b-deduped"
assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(checkpoint)
assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
outputs = model.generate(**inputs, assistant_model=assistant_model)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
temperature 사용해서 randomness를 제어할 수 있음
-> latency를 위해 temperature를 낮추는 것을 권장
from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
set_seed(42) # For reproducibility
prompt = "Alice and Bob"
checkpoint = "EleutherAI/pythia-1.4b-deduped"
assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
inputs = tokenizer(prompt, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(checkpoint)
assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.5)
tokenizer.batch_decode(outputs, skip_special_tokens=True)
자세한 정보는 이 블로그 글을 참고하면 좋을 것 같다.
DoLa decoding
https://arxiv.org/abs/2309.03883
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models
Despite their impressive capabilities, large language models (LLMs) are prone to hallucinations, i.e., generating content that deviates from facts seen during pretraining. We propose a simple decoding strategy for reducing hallucinations with pretrained LL
arxiv.org
-> 해당 논문에서 나온 방법론!
LLM의 사실성을 개선, hallucination을 줄이는 contrastive decoding 방식
- final layer, final-1 layer의 logit을 비교해 transformer layer 에 존재하는 사실적 지식을 증폭시킨다
from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
import torch
tokenizer = AutoTokenizer.from_pretrained("huggyllama/llama-7b")
model = AutoModelForCausalLM.from_pretrained("huggyllama/llama-7b", torch_dtype=torch.float16)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model.to(device)
set_seed(42)
text = "On what date was the Declaration of Independence officially signed?"
inputs = tokenizer(text, return_tensors="pt").to(device)
vanilla_output = model.generate(**inputs, do_sample=False, max_new_tokens=50)
tokenizer.batch_decode(vanilla_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)
dola_high_output = model.generate(**inputs, do_sample=False, max_new_tokens=50, dola_layers='high')
tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)
dola_custom_output = model.generate(**inputs, do_sample=False, max_new_tokens=50, dola_layers=[28,30], repetition_penalty=1.2)
tokenizer.batch_decode(dola_custom_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)
참고 자료
- Huggingface Generation
https://huggingface.co/docs/transformers/v4.44.0/en/main_classes/text_generation#transformers.GenerationMixin.generate - Decoding Figure
https://sooftware.io/generate/ - top-p, top-k
https://ratsgo.github.io/nlpbook/docs/generation/inference1/ - contrastive search
https://huggingface.co/blog/introducing-csearch - contrastive search 논문 리뷰
https://velog.io/@lm_minjin/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-A-Contrastive-Framework-for-Neural-Text-Generation - constrained beam search
https://huggingface.co/blog/constrained-beam-search
'NLP > AI 이론' 카테고리의 다른 글
| [AI Math] 기본 확률론 정리 (0) | 2024.04.16 |
|---|---|
| [AI Math] 딥러닝 수식 뽀개기 (0) | 2024.04.16 |
| [AI Math] 경사하강법 (1) | 2024.01.28 |
| [AI Math] 벡터와 행렬의 개념 (1) | 2024.01.28 |
| [Python] NumPy & Pandas (1) | 2024.01.28 |



