Human - LM Interaction을 평가하기 위한 벤치마크 구축
HCI 분야에 관심을 가지게 된만큼 당분간 논문 리뷰는 해당 분야가 올라올 것 같다. 야호!
원래는 근본 논문이자 최근에 가장 흥미롭게 읽었던 Generative Agents 논문을 먼저 가져오려고 했으나, 그건 정리가 길어질 것 같아서 우선은 미뤘다.
이 논문을 보게 된 이유도 바로 Generative Agents 논문 때문이다.
실험 세팅이나 구성이 매우 흥미로워서 1저자분 블로그를 탐독했더니, 이러한 벤치마크 연구도 하셨더라.
Joon Sung Park
Joon Sung Park's personal site.
www.joonsungpark.com
지난 번 네부캠 프로젝트였던 "찐친이되어줘"에서도 대화에 대한 평가로 애를 먹었었는데, 그때는 GPT를 통한 Evaluation으로 평가를 진행했다.
- G-Eval 포스팅
https://ll2ll.tistory.com/51
[논문 Review] 11. G-EVAL : NLG Evaluation using GPT-4 with Better Human Alignmen
GPT-4를 사용해서 NLG system을 정량적 평가해보자!AbstractNLG는 정량적으로 측정하기 어렵다. 특히 창의성이나 다양성이 요구되는 작업의 경우 BLEU, ROUGE와 같은 기존의 지표는 사람의 판단과 상대적
ll2ll.tistory.com
참고로 G-EVAL은 2023년 3월에 나왔다
이 논문은 GPT 성능이 엄청 좋아지기 이전인 2022년 12월에 발행된 논문으로, 특히 대화형 Agent를 평가하기 위해서 기존에 어떠한 연구 방법론이 적용되었는지를 알아보는 것이 목적이다.
0. Abstract
구축되어있는 대부분의 벤치마크는 비대화형으로 이루어지며, 인간의 개입 없이 모델이 출력을 생성하는 방식이다.
(대표적인 벤치마크인 MTEB만 봐도 알 수 있다)
이에 따라 본 논문에서는 인간 - LM 사이의 상호작용을 평가하기 위한 새로운 프레임워크 Human-AI Language-based Interaction Evaluation, HALIE를 개발하였다.
HALIE는 대화형 시스템의 구성 요소를 정의하고 평가 지표를 설계할 때 고려해야 할 차원을 명확히 제시한다.
기존의 non-interactive 평가 지표과 비교했을 때, HALIE는 다음과 같은 특장점을 가진다.
- 최종 출력뿐만 아니라 상호작용 과정을 포착
- 제3자의 평가뿐만 아니라 1인칭 주관적 경험을 반영
- 생성 품질뿐만 아니라 선호도(e.g. enjoyment, ownership) 등의 개념을 포함
이를 위해 인간 - LM Interaction의 다양한 형태를 다루는 다섯 가지 태스크를 설계했다.
- 사회적 대화(social dialogue)
- 질문 답변(question answering)
- 크로스워드 퍼즐 풀이(crossword puzzles)
- 텍스트 요약(text summarization)
- 은유 생성(metaphor generation)
마지막으로 (당시) SOTA LM 4개를 평가하며, 비대화형 벤치마크에서의 성능이 항상 더 나은 Human - LM interaction으로 이어지지 않는다는 점을 발견했으며 이를 통해 대화형 벤치마크의 중요성을 보였다.
1. Introduction
현재까지 대부분의 LM은 non-interactive 방식으로 평가되었다.
즉 모델이 생성한 출력의 품질에만 맞춰 평가가 진행되고 있다는 뜻이다.
우리의 목표는 단순히 모델의 출력을 평가하는 게 아니라 Human - LM 상호작용 자체를 평가하는 것이다.
다양한 Interactive 환경에서 실제 활용되고 있는 태스크 (대화, 생성 요약, QA 등) 에 대한 성능을 잘 나타내기 위해서는 Human - LM Interaction을 체계적으로 평가하는 통합된 평가 프레임워크가 필요하다.
이걸 위해, Human-AI Language-based Interaction Evaluation (HALIE)라는 평가 프레임워크를 개발하여 인간-LM interactive 시스템의 구성 요소와 평가 지표를 정의하며, 평가에서 상호작용(interaction)을 중심 요소로 설정했다.
또한 유저가 최종적으로 상호작용하는 시스템과의 상호작용을 바탕으로 한다.
시스템은 단순히 LM 그 자체가 아니라, 사용자와 LM 사이에서의 glue 역할을 하는 존재이다.
시스템 로직은 state / action으로 나눌 수 있는데,
- state : UI 내의 텍스트 콘텐츠 (대화 기록, 사용자 입력 상자의 현재 텍스트 등)
- action : 사용자가 수행하는 조작 (send 버튼 클릭, 텍스트 입력 등)
사용자가 행동 (action) 을 수행하면 시스템은 이에 따라 상태 (state) 를 업데이트하고, 이렇게 state-action pair가 연속적으로 발생하는 과정을 상호작용 기록 (Interaction trace) 라고 정의한다.
따라서 시스템에 포함되는 프롬프트, UI 디자인도 상호작용에 상당한 영향을 미칠 수 있지만, 본 연구에서는 가장 표준적인 방식을 따르며 이에 대한 연구도 추후 이어져야 할 것이다.
HALIE에서는 기존 평가 방식에서 3가지 차원 확장을 통해 상호작용 기록 (Interaction trace) 기반의 평가 지표를 정의한다.
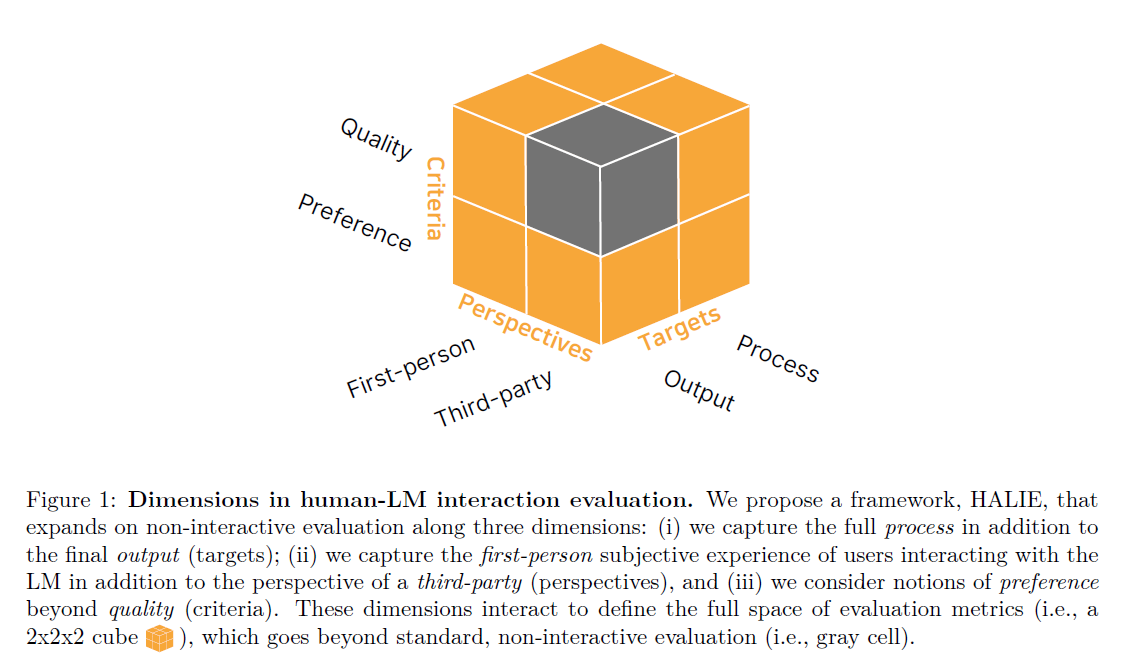
- 평가 대상 (targets) : 최종 출력 뿐만 아니라 상호작용 과정까지 포함
- 평가 관점 (Perspectives) : 제3자의 평가 뿐 아니라 사용자의 1인칭 주관적 경험까지 고려
- 평가 기준 (criteria) : 품질 (accuracy) 뿐만 아니라 선호도 요소(i.e., attitudinal measures of humans
such as enjoyment) 까지 포함
이는 제3자의 annotation을 활용하여 오직 출력의 품질만을 평가하는 Non-interactive benchmarking과는 확연한 차이가 있다.
회색으로 표시된 부분이 기존 비대화형 평가가 고려하던 조합인데,
- 출력(outputs)만을 평가 대상(targets)으로 삼고,
- 제3자(third-party)의 평가 관점(perspectives)만 반영하며,
- 품질(quality)만을 평가 기준(criteria)으로 적용하는 방식
평가는 당시 기준의 최신 LM 4개로 진행했다.
- 모델 사이즈의 영향 분석 : text-davinci-001 VS text-babbage-001
- 지시 기반 학습(Instruction tuning)의 효과를 평가 : text-davinci-001 vs davinci
- 훈련 데이터, 아키텍처 및 기타 구현 요소가 성능에 미치는 영향 평가 : davinci VS j1-jumbo
2. Framework
HALIE를 구성하기 위해 task, system을 정의하고, 상호작용 기록(interaction traces)을 사용해 상호작용 과정을 표현한다. 또한 interaction traces를 바탕으로 한 평가 차원 (dimensions)과 지표(metrics) 를 제안한다.
2.1 Solving Tasks Interactively
우선, 인간과 LM 간의 상호작용 방식을 명확히 정의하기 위해 5가지 task 문제 해결을 설계했다.

- 사회적 대화(Social Dialogue): 주어진 시나리오에 대해 시스템과 대화하기
- 질문 답변(Question Answering): 시스템을 통해 정보를 검색하여 질문에 답하기
- 크로스워드 퍼즐 풀이(Crossword Puzzles): 퍼즐을 풀기 위해 시스템에 질의하기
- 텍스트 요약(Text Summarization): 주어진 문서의 요약을 수정하기
- 은유 생성(Metaphor Generation): 주어진 은유에 대해 가능한 많은 문장 작성하기
실제 환경에서 존재하는 요소를 포함하면서도, 대규모 사용자 연구를 수행할 수 있도록 태스크를 구체적으로 정의함
2.2 Constructing an Interactive System
설계한 각 태스크의 상호작용을 위해 대화형 시스템을 구축했다.
앞에서 언급했듯 사용자는 단순히 LM 그 자체가 아니라 시스템과 상호작용을 하게 되며, 시스템의 구성 요소는 다음과 같다.
- LM – 주어진 텍스트 프롬프트와 디코딩 매개변수를 입력받아 확률적으로 텍스트 출력을 생성
- UI – 본 연구에서는 가장 표준적인 UI 디자인과 사용 방식을 따르며, 동일한 UI 환경에서 다양한 LM의 성능 차이를 비교하는 것에 초점을 맞춤
- System Logic – 상태(states), 사용자 행동(actions), 상태 전이 함수(transition function)를 정의하는 규칙 집합
- 시스템 로직은 MDP ( Markov Decision Process) 에서 영감을 받아 정의되었다.
- 상태(state) $$s_t$$ – 시스템이 현재 상호작용에서 알고 있는 모든 정보(e.g. 대화 기록, 사용자 입력 필드 내 텍스트, 이전 대화 기록)를 포함
- 행동(action) $$a_t$$ – 사용자가 수행할 수 있는 조작(e.g. 버튼 클릭, 텍스트 입력)
- 상태 전이 함수(Transition Function) – 특정 상태에서 사용자의 행동이 수행될 경우, 시스템이 다음 상태로 어떻게 업데이트되는지를 결정하는 함수 ($$s_t -> s_{t+1}$$)
- 사용자가 입력 텍스트를 수정하는 경우 : 해당 텍스트 변경 사항을 반영하여 UI를 업데이트
- 사용자가 LM에게 query를 날리는 경우
- 프롬프트 생성 (CreatePrompt) : 현재 상호작용 맥락에 맞는 프롬프트 구성
- 언어모델 호출 (QueryLM) : 프롬프트를 LM에 입력하여 출력을 생성
- 출력을 사용자에게 표시(ShowCompletions) : LM이 생성한 출력을 UI에 반영
- 상호작용 흔적(Interaction Trace) : 상호작용 과정에서 상태-행동 쌍(state-action pairs)의 연속적인 시퀀스
- 예를 들어 다음과 같이 Social Dialogue 에서 사용자가 "Thanks" 라고 입력 후 전송 버튼을 클릭하면, 시스템은 다음과 같은 과정을 수행한다.
- 현재 대화 기록과 사용자 입력을 결합하여 프롬프트를 생성
- LM을 호출하여 출력 생성
- LM이 생성한 출력을 사용자에게 표시
- 시스템 로직은 MDP ( Markov Decision Process) 에서 영감을 받아 정의되었다.


또한 시스템 로직을 어떻게 설계하느냐에 따라 상호작용에 직접적인 영향을 미칠 수 있다.
1. CreatePrompt – 사용자의 프롬프트 제어 수준
- CreatePrompt는 사용자가 프롬프트를 얼마나 직접 제어할 수 있는지를 결정
- 예를 들어, 사용자의 입력 내용을 그대로 사용할 수도 있고, 미리 정의된 프롬프트(pre-defined prompt)를 강제 적용할 수도 있음
- 또한, 이전 상호작용을 프롬프트에 포함시킬지 여부를 결정할 수 있음
2. QueryLM – 디코딩 매개변수(Decoding Parameters)의 영향
- QueryLM의 디코딩 매개변수는 LM의 출력 특성을 결정합니다 (e.g. temperature 파라미터)
- temperature 값이 높으면 더 창의적이고 다양한 응답이 생성되지만, 정확성이 떨어질 수 있음
반대로, 값이 낮으면 더 일관되고 정확한 응답이 생성되지만, 다양성이 감소할 수 있음
3. ShowCompletions – 모델 출력을 사용자에게 표시하는 방식
- ShowCompletions는 LM이 생성한 출력을 사용자에게 어떻게 보여줄지를 결정
- 예를 들어, 한 번에 몇 개의 출력을 표시할 것인지, 출력이 사용자에게 얼마나 적극적으로(interruptively) 개입할 것인지 등을 조정
- 이러한 설계 결정은 사용자의 인지 부하(cognitive load)를 증가시키거나 주의를 산만하게 만들 수 있음
2.3 Evaluating Human-LM Interaction
기존에 수행되던 non-interactive 평가 방식을 확장하여, 인간-LM 상호작용을 평가하는 세 가지 차원(dimensions)을 제안한다.
- Dimension 1 - 평가 대상 (targets) : 최종 출력 (completion c) 뿐만 아니라 전체 상호작용 과정까지 포함
-> 전체 상호작용 과정은 Interaction trace [(s₁, a₁), (s₂, a₂), ...] 로 표현됨 - Dimension 2 - 평가 관점 (Perspectives) : 제3자의 평가 뿐 아니라 사용자의 1인칭 주관적 경험까지 고려
-> 즉, 사용자가 시스템을 통해 LM과 상호작용하면서 경험한 내용을 중심으로 평가 - Dimension 3 - 평가 기준 (criteria) : 품질 (accuracy, fluency) 뿐만 아니라 선호도 요소(enjoyment, satisfaction) 까지 포함
- 예를 들어, 창의적 글쓰기(creative story writing)의 경우,
- 일부 독자들은 특정 유형의 스토리를 선호하지 않을 수도 있지만(낮은 선호도)
- 해당 스토리가 질적으로 뛰어나다고 평가할 수 있음(높은 품질)
- 예를 들어, 창의적 글쓰기(creative story writing)의 경우,
각 태스크별로 세 가지 평가차원 (targets, perspectives, criteria) 을 반영하는 다양한 평가 지표를 정의
- 일부 지표는 상호작용 흔적(interaction traces)을 기반으로 측정
e.g. 사용자가 수행한 쿼리 개수 - 일부 지표는 출력 (output) 을 기반으로 측정
e.g. crossword puzzle 풀이 정확도 - 일부 지표는 사용자 설문, 제3자 평가를 기반으로 함
e.g. 사용자의 최종 출력에 대한 만족도, 문서 요약의 일관성
아래 표는 5가지 태스크에서 평가 차원 - 평가 지표 간의 매핑을 보여준다.

전체 metric - dimensions 목록

2.4 Guidelines
새로운 태스크에서 HALIE 프레임워크를 적용하는 방법과 적용이 어려운 경우를 다룬다.
2.4.1 How to apply the framework to a new task
HALIE 프레임워크를 활용하려면, 다음 세 단계를 거쳐야 한다.
대화형 태스크 정의(Defining an Interactive Task)
사용자와 LM 간의 상호작용 방식을 명확하게 기술해야 한다.
- 사용자와 LM이 주고받는 입력(input)과 출력(output)의 범위를 정의하고,
- 중간 과정(intermediate steps)이나 상호작용 방식을 설계
e.g. 대화형 이야기 생성 : 사용자와 LM이 한 문장씩 번갈아 가며 이야기를 생성하는 방식
- Task: 총 10문장 길이의 이야기 작성
- 방식:
- 사용자와 LM이 문장을 번갈아 가며 작성함(turn-taking 방식)
- LM이 작성한 문장은 사용자가 수정 가능
- 한 문장씩 진행되며, 이미 작성된 문장은 수정 불가능
대화형 시스템 구축(Constructing an Interactive System)
태스크가 정의되었다면, 이를 수행할 대화형 시스템을 설계해야 한다.
- 시스템 상태(states) 정의
- 사용자 행동(actions) 정의
- 상태 전이 함수(transition function) 설계
e.g. 대화형 이야기 생성
- 상태(state)
- UI에서 이전 대화 내역과 사용자 입력 필드를 표시
- 시스템이 기억해야 할 요소(사용자의 수정 이력 등) 포함
- 사용자 행동(action)
- "문장 추가(Add Line to Story)" 버튼 클릭
- "이야기 제출(Submit Story)" 버튼 클릭
- 상태 전이 함수(Transition Function) 설계
- 사용자가 "문장 추가" 버튼을 클릭하면, 시스템은 사용자가 작성한 문장을 기존 이야기 기록에 추가하고,
- 입력 필드를 비워 새로운 문장을 작성할 수 있도록 유도
평가 지표 설계(Designing Evaluation Metrics)
HALIE 프레임워크에서 제시한 세 가지 평가 차원(targets, perspectives, criteria)을 고려해야 한다.
- 무엇을 평가할 것인지(targets)
- 누구의 관점을 반영할 것인지(perspectives)
- 어떤 기준으로 평가할 것인지(criteria)
e.g. 대화형 이야기 생성
- 사용자가 LM의 출력을 "유용하다(useful)"고 평가하는 정도를 측정
- 인터뷰를 통해 열린 질문 형식의 사용자 피드백을 수집
- 또는 각 문장마다 "유용성(likert scale)"을 평가하도록 설문 설계
2.4.2 When not to apply the framework
HALIE 프레임워크는 Human-LM 상호작용을 평가하기 위해 설계되었기 때문에, 다음과 같은 경우에는 적용이 어렵거나 적절하지 않을 수 있음
1) LM이 인간 평가의 대리(proxy)로 사용되는 경우
HALIE는 "실제 사용자(human user)"와의 상호작용을 중심으로 평가하도록 설계되었기 때문에, LM을 활용하여 또 다른 LM을 평가하는 태스크의 경우 이 프레임 워크가 적절하지 않음
2) 사용자가 LM과 직접 상호작용하지 않는 경우
예를 들어, 사용자가 LM의 출력을 단순히 읽고 평가만 하는 경우, HALIE 프레임워크를 적용하기 어려움
HALIE는 사용자가 LM의 출력을 수정하거나, 질의를 수행하며 적극적으로 개입하는 시나리오를 전제로 함
3) 다중 사용자(multiple users) 또는 다중 LM(multiple LMs) 환경
- HALIE는 "단일 사용자(single user) - 단일 LM(single LM)" 상호작용을 평가하는 데 초점을 맞추고 있음
- 따라서 여러 사용자가 동시에 LM과 협업하는 환경(e.g. 협업형 AI 도구)이나 여러 개의 LM이 동시에 활용되는 환경에서는 프레임워크를 확장해야 할 필요가 있다
3. Experiments
3.1 Summary of Findings
3.1.1 Targets: Output vs. Process
비대화형(non-interactive) 성능이 향상되면, 대화형(interactive) 성능도 향상될까?
기존 비대화형 벤치마크에서 최고 성능을 보인 모델이, 실제 사용자와 상호작용할 때도 최상의 성능을 낼 것이라고 가정할 수 있을까?
실험을 통해 그렇지 않다는 결론을 얻을 수 있었다.
예를 들어 QA 태스크 (Goal-oriented) 에서,
- 비대화형 평가(accuracy)와 대화형 평가(사용자의 만족도, ease of use) 결과가 일치하지 않는 사례가 발견됨
- 특히, 비대화형 성능이 가장 낮은 모델이 대화형 환경에서는 더 우수한 성능을 보이는 경우도 있었음
- TextBabbage 모델은 비대화형 평가에서 최악의 정확도를 보였으나,
"영양(Nutrition)" 카테고리에서는 사용자 보조 도구(interactive assistant)로 활용될 때 가장 좋은 성능을 보였다 - 또한 US Foreign Policy 카테고리에서 Jumbo는 가장 낮은 성능을 보였고 Davinci가 가장 높은 성능을 보였지만, LM 어시스턴트로서는 Jumbo가 Davinci보다 더 뛰어난 성능을 보였다
또한 은유 생성 (creative task) 에서,
- 모델이 생성한 출력이 얼마나 도움이 되는지를 평가하는 방식에 따라 성능 결과가 달라졌음
- 예를 들어, TextDavinci 모델은 편집 거리(edit distance) 기준으로는 가장 적은 수정을 필요로 하는 출력을 생성했지만, 사용자의 실제 편집 시간(total time spent)과 질의 횟수(number of queries) 기준으로 보면, Davinci 모델이 더 효과적이었다
- 이는 출력 품질만이 아니라, 상호작용 과정 전체를 평가하는 것이 중요함을 시사
이러한 결과는 소수 케이스지만, 만약 우리가 비대화형 성능만을 기준으로 모델을 선택한다면 최상의 대화형 성능을 달성하지 못할 수도 있음을 시사한다.
3.1.2 Perspectives: Third-party vs. First-person
1인칭 사용자 경험(first-person perspective)과 제3자 평가(third-party evaluation) 결과는 일치하는가?
실험에서 1인칭 사용자 경험과 제3자 평가가 다르게 나타나는 사례가 있었다.
- 텍스트 요약(Text Summarization)에서 제3자 평가자(평가자의 요약 정확도 평가), 실제 사용자(사용자의 만족도 평가) 간의 차이가 관찰되었으며,
- 크로스워드 퍼즐(Crossword Puzzles) 에서 사용자는 TextDavinci 모델을 가장 선호했지만 객관적인 정확도 평가에서는 TextDavinci가 항상 최적의 성능을 보이지 않았다.
이는 모델이 유창한(fluent) 출력을 생성하면, 사용자가 이를 정확한 정보로 오해할 가능성이 높음을 시사한다.
3.1.3 Criteria: Quality vs. Preference
품질 평가(quality)와 사용자의 선호도(preference)는 일치하는가?
실험에서 사용자가 "품질이 높은 모델"을 항상 선호하는 것은 아님을 발견했다.
사회적 대화(Social Dialogue)에서,
- TextDavinci 모델은 문장의 유창성(fluency), 자연스러움(sensibleness), 인간 유사성(humanness) 등 대부분의 평가 항목에서 최고 점수를 기록했지만 사용자는 특정 맥락에서 Davinci 모델과의 상호작용을 더 선호하는 경향을 보였다
- Davinci 모델은 사용자의 발화에 가장 구체적으로 응답했으며,
- 사용자는 보다 구체적인 응답을 제공하는 모델과의 상호작용을 지속하고자 하는 경향을 보였다
이 결과는 "모델이 얼마나 자연스러운가"보다, "사용자가 원하는 방식으로 응답하는가"가 더 중요할 수 있음을 시사한다
이후 각각의 섹션에서는 아래의 실험 설계 및 세부 결과를 다룬다
- 사회적 대화(Social Dialogue, Section 3.2)
- 사용자와 LM이 특정한 시나리오를 기반으로 대화
- 평가 항목: 유창성, 자연스러움, 인간 유사성, 대화 지속 의향 등
- 질문 답변(Question Answering, Section 3.3)
- 다중 선택형 질문(multiple-choice question) 형식의 질의 응답
- 평가 항목: 정확도(accuracy), 사용자의 질의 전략 변화(query reformulation) 등
- 크로스워드 퍼즐 풀이(Crossword Puzzles, Section 3.4)
- 사용자가 퍼즐을 풀기 위해 LM에 질의
- 평가 항목: 퍼즐 해결 정확도, 사용자의 인식된 도움의 정도
- 텍스트 요약(Text Summarization, Section 3.5)
- 사용자가 LM이 생성한 요약을 편집
- 평가 항목: 요약의 정확성, 일관성, 사용자 만족도
- 은유 생성(Metaphor Generation, Section 3.6)
- 주어진 은유를 기반으로 문장 생성
- 평가 항목: 생성된 문장의 창의성, 사용자 편집 노력
5. Discussion
대화형 환경에서 인간 사용자와 함께 LM을 벤치마킹하는 과정은 기존의 평가 방식과는 다른 새로운 도전과제와 한계를 제시한다.
이 섹션에서는 task, system을 설계하는 과정에서 직면했던 한계를 공유하고, 이를 해결할 수 있는 잠재적 해결책과 향후 연구 방향을 논의한다.
5.1 General Challenges in Human Evaluation
비용(Cost)
- 자동 평가(automatic evaluation)에 비해 인간 평가(human evaluation)는 높은 비용이 소요
- 연구자들이 인간 중심 평가(human-centric evaluation)를 채택하는 데 있어 가장 큰 장애물이 될 수 있다
- 최근에는 LM을 활용하여 인간 판단을 모방하거나, 더 일반적으로 인간 행동을 시뮬레이션하려는 연구가 진행되고 있다
- 이는 비용 효율적인 평가 방법을 제공할 수 있지만, 궁극적으로 LM 평가의 ground truth을 설정하기 위해 인간 사용자 평가를 최소 한 번은 수행해야 하며 실제 인간 평가와 자동화된 평가 지표 간의 상관관계를 분석하여 평가 방법의 신뢰성을 확보해야 한다
재현성(Reproducibility)
- 많은 연구들이 실험에 사용된 사용자 수, 학습 과정, 지침, 모델 출력 등 핵심 정보를 명확하게 명시하지 않는데, 이는 연구의 재현성(reproducibility)을 심각하게 저해합니다.
- 본 연구에서는 3장(Section 3)과 부록 C(Appendix C)에서 실험 설계, 데이터 수집 과정, 실험 방법론을 상세히 기술하며, 코드와 데이터는 공개 저장소(https://github.com/stanford-crfm/halie)에서 제공하여 연구 재현성을 높였다
- 이를 통해 다른 연구자들이 본 연구를 반복적으로 검증하고, 후속 연구를 진행할 수 있도록 지원한다
주관성(Subjectivity)
- 인간 평가(human judgment)는 본질적으로 주관적이므로, 평가자 간의 편차가 발생할 수 있습니다.
- 이러한 변동성을 줄이기 위해서는 동일한 평가자가 여러 모델을 비교하는 "within-subject" 연구 디자인이 이상적
- 하지만, 모델이 4개일 경우, 각 사용자가 동일한 실험을 4번 반복해야 하므로, 실험 참가자의 부담이 크게 증가한다
- 예를 들어, 텍스트 요약 실험에서 각 사용자는 10개의 요약을 평가하고 수정해야 했으며, 4개의 모델을 평가하려면 40번 반복해야 함 → 30분이 아닌 2시간 이상 소요
- 현실적인 이유로, 우리는 between-subject 연구 디자인을 채택하였으며,
- 대규모 사용자 모집을 통해 개인 차이를 줄이는 방식을 적용
- 통계적 분석을 활용하여 연구 결과의 신뢰도를 보장
5.2 General Challenges in Interactive Evaluation
연구 설계(Study Design)
- 사용자의 개인차에 따라 LM과의 상호작용 방식이 매우 다를 수 있음
-> 이러한 개인차를 고려하지 않으면, 실험 결과가 왜곡될 가능성이 있다 - 따라서 가능하다면 모든 사용자가 동일한 모델과 상호작용하는 within-subject 연구 설계가 바람직하지만,
- 각 사용자가 여러 모델을 평가할 경우 실험 순서 효과를 제어할 필요가 있음
- 예를 들어, 사용자가 처음 접하는 모델은 "신기함(novelty effect)" 때문에 초기 성능이 과대평가될 가능성이 있음.
- 또한, 시간이 지나면서 사용자가 특정 모델에 적응하여 성능이 향상될 수도 있음.
- 이러한 효과를 줄이기 위해, 본 연구에서는 사용자 모집단을 늘려 모델 간 비교의 신뢰성을 확보하는 전략을 사용했다
(역시 돈이 짱이다)
응답 지연(Latency)
- LM의 응답 속도(latency)는 Human-LM 상호작용 경험에 큰 영향을 미칠 수 있음.
- HCI 연구에서는 인터랙티브 시스템이 0.1초 이내에 응답해야 즉각적인 반응으로 인식되며, 1초 이내에는 사용자 흐름을 방해하지 않는다고 권장
- 본 연구에서 실험한 4개 모델의 응답 속도는 수용 가능한 범위였음.
- TextDavinci: 0.12초
- TextBabbage: 0.12초
- Davinci: 0.36초
- Jumbo: 0.48초
- 그러나, 실험 당시 응답 시간이 Davinci보다 50배 이상 느린 일부 모델은 제외해야 했음
- 이러한 결과는 대규모 LM이 빠른 응답을 제공하는 것이 실제 배포 환경에서 중요한 요소임을 시사
해로운 출력(Harmful Outputs)
- LM은 유해한(toxic) 또는 편향된(biased) 텍스트를 생성할 가능성이 있음
- 본 연구에서는 크로스워드 퍼즐 실험에서 일부 모델이 의도치 않은 인종차별적(output) 또는 불쾌한 발언을 생성하는 사례를 발견했음
- 예를 들어, 한 사용자가 "어린 비둘기를 무엇이라고 부르나요?"라고 입력했을 때,
- TextBabbage가 인종차별적인 단어를 응답으로 생성하는 심각한 사례가 발생
- 이는 사용자의 프롬프트가 악의적인 의도를 가지지 않았음에도 불구하고, LM이 학습된 데이터 내의 편향을 반영할 수 있음을 보여준다
- 향후 연구에서는 더 강력한 필터링 기법과 안전장치를 추가하여 이러한 문제를 방지할 필요가 있습니다.
5.3 Limitations Specific to Our Experiment Design
- Task Selection: 연구에서 5개의 Task를 선정했으나, LM이 활용될 수 있는 모든 가능성을 포괄하지 못함
- UI Design: UI가 상호작용 경험에 미치는 영향을 심층적으로 연구하지 못함
- Model Selection: 연구 후 최신 모델이 등장했으며, 새로운 모델이 실험 결과에 어떤 영향을 미칠지 추가 연구가 필요
5.4 Future Work
Accomodation
Human-AI 상호작용에서 중요한 요소 중 하나는 사용자의 적응이며, 이는 사용자가 시스템과 해당 모델의 강점과 약점을 학습하면서 자신의 행동을 조정하는 능력을 의미한다.
QA, Crossword puzzle 실험에서 사용자들에게 "AI와 상호작용하는 방식이 시간이 지나면서 변화했냐"고 물었을 때 대부분의 경우는 변화했다.
예를 들어, QA 실험에서 질문 형태의 프롬프트는 TextBabbage와 TextDavinci 모델에서 더 성공적인 출력을 생성했으며, 이에 따라 Davinci 또는 Jumbo 모델을 사용하는 사용자들은 점점 더 질문 형태가 아닌 "빈칸 채우기" 스타일의 선언문 프롬프트로 전환하는 경향을 보였다.
즉 사용자는 LM이 특정 유형의 질문에 약하다는 것을 인지하면, 질의 방식을 변경하거나 추가적인 컨텍스트를 제공할 가능성이 높다.
이러한 결과를 바탕으로, 우리는 장기적인 interactive 시나리오에 대한 연구가 필요하다고 본다. 사용자가 도구에 익숙해지는 데 걸리는 시간이 전체 상호작용 기간보다 중요하지 않다고 판단되는 경우, 이러한 장기적 적응 과정이 더 큰 영향을 미칠 수 있기 때문이다.
Lasting Impact
본 연구는 사용자와 언어 모델(LM)의 단기적인 상호작용(short-term interaction)에 초점을 맞추고 평가한다.
그러나 Human-LM 상호작용 및 더 넓은 의미에서 Human-AI 상호작용은 사용자에게 장기적이고 지속적인 영향을 미칠 가능성이 크다.
예를 들어 AI 기반 글쓰기 도구를 사용하면 사용자의 문장 스타일이 특정 패턴을 따르게 될 가능성이 있으며, 최근 연구에서는 AI 챗봇과 장기간 대화할 경우, 사용자의 언어 습관(language habits)이나 의견 형성(opinion formation)에 영향을 미칠 수 있음이 보고되었다.
Expanding System Design and Evaluation Frameworks
본 연구에서는 보편적인 UI 및 평가 환경을 고정해두고실험을 수행했지만, UI 디자인과 상호작용 방식에 따라 Human-LM 상호작용의 결과가 달라질 가능성이 큽니다.
향후 연구에서는 보다 다양한 시스템 디자인을 실험하여, 평가 프레임워크를 확장할 필요가 있다.
- UI 요소(e.g. 응답 제안 방식, 피드백 메커니즘)가 상호작용 경험에 미치는 영향을 분석
- 다양한 프롬프트 전략(prompting strategies) 및 상호작용 모델(interaction models)을 실험
- 대화형 AI를 활용한 협업 환경(collaborative AI environments)에서 인간-인공지능 협업 방식을 연구
이를 통해, 보다 실용적이고 사용자 친화적인 AI 시스템을 설계할 수 있는 지침을 도출할 수 있을 것이다.
참고 문헌
'NLP > 논문리뷰' 카테고리의 다른 글
| [논문 Review] 24. ClueCart (0) | 2025.11.03 |
|---|---|
| [논문 Review] 23. Generative Agents (3) | 2025.04.10 |
| [논문 Review] 21. Deepseek LLM (1) | 2025.02.13 |
| [논문 Review] 20. NV-Retriever: Improving text embedding models with effective hard-negative mining (3) | 2024.12.22 |
| [논문 Review] 19. Mixed Precision Training (1) | 2024.07.25 |



