https://arxiv.org/abs/1502.03167
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Training Deep Neural Networks is complicated by the fact that the distribution of each layer's inputs changes during training, as the parameters of the previous layers change. This slows down the training by requiring lower learning rates and careful param
arxiv.org
노션에 정리해놓은 내용을 티스토리로 옮기며 다시 한 번 정리했다.
Abstract
DNN에서의 학습은 각 레이어 입력값의 분포가 학습 도중 이전 레이어의 변화에 따라서 바뀌기 때문에 복잡하다.
이로 인해 낮은 학습률과 조심스러운 파라미터 초기값을 요구하며, 이는 학습의 속도를 낮추곤 한다.
우리는 이러한 현상을 internal covariate shift라고 명명했으며, 레이어 입력을 정규화해서 문제를 해결해볼 것이다.
Batch Normalization은 각 미니배치 학습 시마다 정규화를 시도하며, 더 높은 학습률을 사용할 수 있게 해주고, 초기 파라미터에 덜 민감하도록 해준다. 또한 이는 regularizer로도 작동할 수 있으며, 몇몇 케이스에서는 dropout을 대체할 수 있기도 한다. Batch Normalization을 이용한 네트워크 앙상블에서 좋은 성과를 거두었다.
1. Introduction
SGD는 딥러닝을 학습시키는 효과적인 방법이라는 것이 입증되었으며 momentum, adagrad와 같은 변형 최신 기술도 발표되었다. SGD는 아래 손실함수 수식을 최소화하며 이루어진다.
$$ \Theta = argmin_{\Theta} \frac{1}{N} \sum^N_{i=1} l(x_i, \Theta) $$
- \(x_1,...N\) : 학습 데이터셋
- \(\Theta\) : 네트워크 파라미터
SGD에서 각 스텝은 미니 배치 사이즈인 m 크기에 따라 이루어지며, 파라미터에 대한 손실 함수의 gradient를 근사한다.
계산 수식은 아래와 같다.
$$\frac {1}{m} \sqrt{\delta l(x_i, \Theta)}{\delta\Theta}$$
미니배치를 사용하는 데에는 여러 이점이 있다.
- 미니 배치에 대한 gradient 계산은 전체 training set에 대한 gradient 계산이 된다. (추정치의 질은 batch size가 늘어날수록 올라간다.)
- 배치 단위로 계산하는 것이 각각의 예시를 계산하는 것보다 병렬로 계산할 수 있어서 더 효율적이다.
SGD가 간단하고 효과적이지만, 이는 모델 하이퍼파라미터의 섬세한 튜닝을 필요로 하며 특히 학습률, 모델 파라미터의 초기값을 정할 때 그러하다. 모델 학습은 더욱 복잡해지는데, 모든 레이어가 앞선 레이어 파라미터들의 영향을 받기 때문에 네트워크 파라미터의 작은 차이점도 네트워크가 깊은 것처럼 증폭시킨다.
레이어 입력 값의 분포 변화가 문제가 되는 이유는 레이어가 계속적으로 새로운 분포를 받아들여야 하기 때문이다.
이러한 현상을 우리는 covariate shift라 하고, 기존에는 이를 domain adaptation을 통해 다루었다.
covariate shift의 개념은 서브 네트워크나 레이어와 같은 전체 학습 시스템으로도 확장될 수 있다.
다음과 같은 네트워크 컴퓨팅이 있다고 가정해보자.
$$l = F_2(F_1(u, \Theta_1), \Theta_2)$$
- F1, F2 : 임의의 변환
- Theta1, Theta2 : loss func을 최소화하기 위해 학습된 파라미터
\(x = F_1(u, \Theta_1)\) 을 한 입력으로 가정하면, 위 수식은 다음과 같이 쓰일 수 있다.
$$l = F_2(x, \Theta_2)$$
즉, \(x = F_1(u, \Theta_1)\) 이 서브 네트워크인 \(F_2\)로 들어가게 되는 것이다.
위 네트워크의 gradient descent step을 살펴보자.
$$ \Theta_2 ← \Theta_2 - \sqrt{\alpha}{m}\sum^m_{i=1}\sqrt{\delta F_2(x_i, \Theta_2)}{\delta \Theta_2} $$
이는 \(F_2\)라는 독립적인 네트워크에 입력값 x가 들어가는 것과 정확히 동일하다.
따라서 학습을 더 효율적으로 만드는 입력 분포 속성은 서브 네트워크 학습도 효율적으로 만든다고 볼 수 있다.
\(\Theta_2)\) 가 입력 분포의 변화를 보정하기 위해 다시 조정될 필요가 없으므로, 입력값 x의 분포가 시간이 지나도 고정된 상태로 유지되는 것이 학습에 유리하다고 볼 수 있다.
입력 값의 고정된 분포는 서브 네트워크 밖에 있는 레이어에도 긍정적인 영향을 끼칠 수 있다.
$$ z = g(Wu + b) $$
- u : 레이어 입력
- W : 가중치 매트릭스
- b : 편향 벡터
- g(x) : sigmoid
|x|가 증가할수록, g'(x)는 0에 가까워질 것이다. 따라서 모든 차원의 x=Wu + b 절대값이 0에 가까워지며, Gradient Vanishing 현상을 발생시킬 것이다. 하지만 x는 W, b 및 하위 모든 레이어의 파라미터에 영향을 받기 때문에 훈련 중 파라미터를 변경하면 x의 많은 차원이 비선형성의 포화 영역으로 이동하며 수렴 속도를 느리게 할 수 있다.
이와 같은 문제점은 네트워크의 깊이가 증가할 수록 증폭된다. 이러한 문제를 해결하기 위해 ReLU, careful initialization, small learning rates가 방법으로 제시되었다. 하지만 ReLU 에서 가중치 합이 음수가 되면 0만 반환되는 현상 (Dying ReLU)이 발생하고, 학습률이 낮을 경우 수렴 속도가 그만큼 느려진다는 한계점을 가지고 있다.
만약 네트워크가 학습할 때 비선형성 입력 분포가 더 안정적으로 유지될 수 있도록 하면 학습을 가속화시킬 수 있을 것이다.
우리는 학습 과정에서 DNN의 내부 노드 분포를 변화하는 것을 "Internal Covariate Shift" 로 명명했다. 내부 분포를 제거하면 더 빠른 훈련속도를 얻을 수 있을 것이다. 여기서 Internal Covariate Shift를 줄여 DNN의 학습 속도를 비약적으로 향상시킬 수 있는 새로운 매커니즘 "Batch Normalization" 을 제안한다.
Batch Normalization은 레이어 입력값의 평균과 분산을 정규화하는 과정을 통해 이루어지며, 다음과 같은 부가 효과를 가지고 있다.
- 파라미터의 스케일이나 초기 값에 대한 의존성을 줄여 발산의 위험성 없이 더 높은 학습률 사용 가능
- 모델을 정규화하는 효과 (dropout의 필요성 줄임)
- saturating nonlinearities을 사용할 수 있게 해 Saturated modes 에서 네트워크가 멈추는 것을 방지
Saturating Nonlinearity?
- non-saturating : 어떤 입력 x가 무한대로 갈 때 함수 값이 무한대로 가는 것 (ex. ReLU)
- saturating : 어떤 입력 x가 무한대로 가더라도 함수 값은 특정 범위 내에서만 존재 (ex. sigmoid, tanh)
2. Towards Reducing Internal Covariate Shift
학습을 향상시키기 위해서는 앞에서 정의한 "Internal Covariate Shift"를 줄일 필요성이 있다. 레이어 입력값인 x의 분포를 학습 과정 중에 고치면 학습 속도가 더 빨라질 것이라고 예상한다.
이전 연구에서 이미 input이 whiten되면 수렴이 빨라진다는 사실은 밝혀진 바 있다. (평균 0, 정규 분산을 가지는 선형 변환)
각 레이어가 이전 레이어에 영향을 받는다면, 각 레이어의 입력값에 같은 whitening을 적용하면 좋을 것이다. 매 학습 스텝마다 whitening을 수행하는 방법과 interval을 두고 수행하는 방법이 있는데, 네트워크를 직접적으로 변경하거나 optimization algorithm의 parameter를 변경하는 것으로 변경을 수행할 수 있다.
그러나, 이러한 변경이 optimization steps에서 이루어지면 gradient descent 단계에서 정규화를 업데이트 하는 방식으로 파라미터를 업데이트하려고 시도하기에 gradient step의 효율성을 떨어뜨린다.
예를 들어, 다음과 같은 레이어를 가정해보자.
$$x = u + b$$
- u : 레이어 입력값
- b : 학습된 편향
- x : 학습 데이터
이 때 학습 데이터 x에서 평균 E[x] 를 뺀 \(\hat{x}) 로 결과를 정규화할 때, 만약 gradient descent step이 b에 대한 E(x)의 의존성을 무시한다면 \(b ← b + \Delta) 로 업데이트할 것이고, \(\Delta b)는 \(\sqrt{\partial l}{\partial \hat{x}}) 와 비례할 것이다. 따라서 다음과 같은 수식이 완성된다.
$$u + (b + \Delta b) - E[u + (b + \Delta b)] = u + b - E[u+b]$$
따라서 b의 연속적인 업데이트와 정규화가 레이어의 결과값이나 loss 에 영향을 미치지 못한다.
모델 학습이 지속될수록 loss가 고정된 상태에서 b는 무한대로 늘어날 것이며, 이러한 문제는 정규화가 중심 뿐 아니라 스케일을 조정하는 경우 더욱 악화될 수 있다.
위 접근방식에서의 문제점은 GD optimization이 정규화를 고려하지 않는다는 것이다.
이 문제를 해결하기 위해 모든 파라미터 값에 대해서 네트워크가 항상 원하는 분포의 활성화를 생성하고자 한다.
이렇게 하면 모델 파라미터에 대한 gradient loss가 정규화와 모델 파라미터 Theta에 대한 의존성을 설명할 수 있다.
샘플 x에만 의존하지 않고 전체 샘플 X에 의존하는 정규화 수식은 다음과 같다.
$$\hat{x} = Norm(x, X)$$
- x : 레이어 입력값 벡터
- X : 훈련 데이터에서의 입력 집합
각각은 x가 다른 레이어에 의해 생성되었을 때 파라미터 Theta에 의존한다.
역전파를 위해 자코비안을 계산한다.
Jacobians?
다변수 벡터 함수의 도함수 행렬. Jacobian matrix를 통해 변수가 n개인 m개의 함수에 대해 편미분값을 모두 구할 수 있다.
$$\sqrt{\partial Norm(x, X)}{\partial x} and \sqrt{\partial Norm(x, X)}{\partial X}$$
뒤의 항 (전체 분포 분모로 갖는 항) 을 무시할 경우 앞서 설명한 gradient explosion이 발생할 수 있다.
이 프레임워크에서는 레이어 입력값을 whitening하기 위한 계산 비용이 많이 들어간다.
이로 인해 우리는 입력 정규화를 기존 방식과 다르게 진행하며 파라미터를 업데이트 할때마다 전체 훈련 데이터에 대한 analysis를 요구하지 않는 다른 방식을 찾고자 한다.
이전 접근 방식에서는 한 개의 샘플에서 계산된 통계들을 사용하거나, (이미지 네트워크와 같은 경우) 주어진 위치에 따른 다른 피처맵들을 사용하는 방식을 활용했다.그러나 이는 activations의 절대크기를 무시함으로써 네트워크의 표현 가능성을 바꿔버린다.
우리는 전체 훈련 데이터 대신 주어진 훈련 예제의 activations를 정규화해서 기존의 네트워크의 정보를 보존하며 정규화를 진행하고자 한다.
3. Normalization via Mini-batch Statistics
모든 레이어의 입력을 whitening하는 것은 공분산 행렬과 역행렬 계산이 필요하기 때문에 계산비용이 많이 들고, 모든 곳에서 차이점이 나타나지는 않기 때문에 두 가지를 단순화했다.
1. 레이어의 입출력 feature들을 공동으로 whitening하는 대신, 각각의 스칼라 feature를 평균을 0으로, 분산을 1로 만드는 독립적 정규화를 진행할 것이다. 이러한 정규화 방식은 수렴까지 도달하는 시간을 단축시키고, 이는 correlation이 없는 특징들에도 적용된다.
하지만 단순히 각 레이어의 입력값을 정규화하는 것은 레이어의 표현을 바꿀 수 있다는 점을 유의해야 한다.
예를 들어, 입력 값을 sigmoid로 정규화하는 것은 features의 비선형성을 선형으로 제한할 가능성이 있다. 이를 해결하기 위해서는 “네트워크에 삽입된 변환이 동일한 변환을 표현할 수 있어야 한다”는 것이 보장되어야 한다.
이를 위해서 다음과 같은 수식이 사용된다.
$$ y^{(k)} = \gamma ^{(k)} \hat{x}^{(k)} + \beta^{(k)} $$
- \(x^(k)\) : 각 activation
- \(\gamma ^{(k)}, \beta^{(k)}\) : 파라미터
이 파라미터들은 원래의 모델 파라미터들과 함께 학습되며, 네트워크의 표현력을 복구한다.
\(\gamma ^{(k)} = \sqrt{Var[x^{(k)}}, \beta^{(k)} = E[x^{(k)}]\) 로 설정해 원래의 활성화 상태를 복구할 수 있다.
Batch GD (BGD)에서 activations를 정규화하기 위해 모든 데이터를 활용하지만, 이는 Stochastic GD (SGD) 을 활용할때는 비실용적이다. 따라서, 우리는 두 번째 단순화 방법을 활용할 것이다.
2. Mini-batch GD (MGD) 에서 각 미니배치는 각 activation에 대한 추정 평균, 추정 분산을 생성해낸다. 이렇게 하면 정규화에 사용되는 통계가 gradient back-propagation에 완전히 쓰일 수 있다.
미니배치 사용은 공동 공분산이 아닌 차원별 분산 계산을 통해 가능하며, 공동의 경우 미니배치의 크기가 activation의 수보다 작아 단일 공분산 행렬을 생성하므로 정규화가 필요하다는 점에 유의해야 한다.
정규화는 각 activation에서 독립적으로 일어나므로, 특정 activation인 \(x^{(k)}\)에 대해서만 살펴보자.
$$B = {x_{1,...m}}$$
- B : 미니배치
- m : 미니배치 크기
다음과 같은 선형 변환을 Batch Normalization Transform으로 명명한다.
$$BN_{\gamma, \beta} : \hat{x}_{1...m} → y_{1..m}}$$
- \({x}_{1..m}\) : 입력값
- \(y_{1..m}\) : 입력값의 선형 변환
알고리즘을 정리하면 다음과 같다.

각 미니배치마다 평균, 분산을 계산한 후 정규화하고, 학습된 파라미터를 통해 입력분포를 맞춰주는 것을 볼 수 있다.
이 때 BN은 어느 activation에서나 적용될 수 있다.
또한 BN의 정의에서 파라미터 gamma와 beta는 학습되어야 하는 파라미터를 의미하지만, BN transform이 각 훈련 샘플에서 activation을 독립적으로 처리하지 않는다는 점에 유의해야 한다. (BN transform은 training example, 그리고 mini-batch 안의 다른 examples에도 영향을 받는다)
scale & shift 된 y값은 다른 네트워크 레이어로 전달된다. 정규화된 activation인 \(\hat{x}\)는 각 미니배치가 같은 분포로부터 샘플링되었다고 가정할 때, 평균 0과 분산 1 값을 가진다.
이를 통해 우리는 다음과 같은 수식을 도출할 수 있다.
$$\sum^m_{i=1}\hat{x_i}=0, \frac{1}{m}\sum^m_{i=1}\hat{x_i}^2=1$$
정규화된 각 activation \(\hat{x}^{(k)})는 서브 네트워크의 입력값이자 선형 변환 (\( y^{(k)} = \gamma ^{(k)} \hat{x}^{(k)} + \beta^{(k)})\) 을 구성하는 값으로 볼 수 있다.
서브 네트워크 입력값은 모두 고정된 평균값과 분산값을 가지며, 따라서 정규화된 \(\hat{x}^{(k)}\)의 결합확률분포가 학습 중에 바뀌더라도 정규화된 입력을 도입하면 서브 네트워크의 훈련이 가속화되고 결과적으로 네트워크 전체가 가속화될 것으로 예상된다.
학습 도중에 이 변환을 통해 손실 l의 gradient를 역전파해야 할 뿐만 아니라 BN 변환의 파라미터에 대한 gradient를 계산해야 한다. 아래와 같이 chain rule을 이용하여 역전파를 진행한다.
Chain rule?
미적분학에서 연쇄 법칙(連鎖法則, 영어: chain rule)은 함수의 합성의 도함수에 대한 공식이다.
출처 : 위키백과
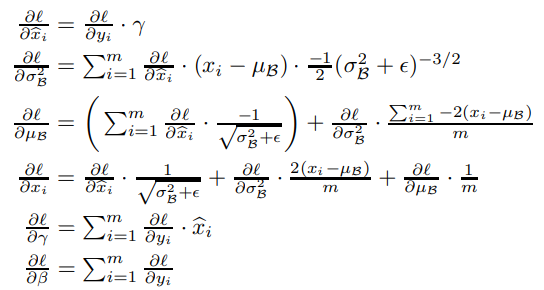
따라서 BN transform은 정규화된 activations를 네트워크에 포함시키는 차별화된 변환방법이다.
이것은 모델이 학습할 때, 레이어가 계속 입력값 분포에 대해서 배우고 적은 covariate shift를 보장해 학습 속도를 가속한다. 더 나아가서, 학습된 아핀 변환이 activation 정규화에 적용되면 BN transform이 고유한 표현 방법을 표현하고 네트워크 수용력을 보존할 수 있다.
Affine Transformation?
- 아핀 공간 : 유클리드 공간의 아핀 기하학적 성질을 일반화해서 만들어지는 구조
아핀 공간에서는 점에서 점을 빼서 벡터를 얻거나 점에 벡터를 더해 다른 점을 얻을 수는 있지만 원점이 없으므로 점과 점을 더할 수는 없다.
- 아핀 변환 : 아핀 기하학적 성질들을 보존하는 두 아핀 공간 사이의 함
3.1 Training and Inference with Batch-Normalized Networks
네트워크를 Batch normalize하기 위해서 activations의 부분 집합을 특정하고, BN transform (Alg 1)을 각각에 삽입해야 한다. Batch Normalization을 이용한 모델은 BGD나 MGD (mini batch size > 1)를 이용해 학습될 수 있고, 혹은 그의 변형들(Adagrad 등)도 활용 가능하다. 미니 배치에 의존하는 activations의 정규화는 효율적인 학습을 가능하게 하지만, 이는 추론 과정에서는 필요하지도, 바람직하지도 않다. 오직 입력 값에 따라 결과값을 산출하는 것을 목표로 한다.
이를 위해 한 번 네트워크가 학습되면 미니 배치 통계치를 이용하는 것이 아니라, 모집단을 사용하여 정규화한다. 모집단을 사용해 정규화할 경우, 학습할 때와 동일한 평균 0, 분산 1을 가진다.
편향되지 않은 분산 추정치 (\(Var[x] = \sqrt{m}{m-1} \times E_{\Beta} [\sigma_\Beta^2])\) 를 사용하며, 여기서의 평균은 크기 m의 미니배치에 대한 평균이고 sigma는 해당 샘플의 분산이다.
평균 이동법을 사용하는 대신, 우리는 모델이 학습되는 동안 정확도를 추적할 수 있다. 추론 과정 동안 평균과 분산은 고정되어있기 때문에, 정규화는 간단한 선형 변환으로 각 activation에 적용된다.이는 나중에 gamma에 의해 scaling되고, beta에 의해 shift되며 BN(x)에서 대체될 수도 있다.
아래 그림은 Batch-normalized 네트워크를 학습하는 과정을 요약한 것이다.

3.2 Batch-Normalized Convolutional Networks
Batch Normalization은 네트워크의 어느 activation 집합에도 적용될 수 있다. 아핀 변환으로 이루어진 Transformation 수식을 살펴보자.
$$z = g(Wu + b)$$
- W, b : 모델이 학습한 파라미터
- g : 비선형함수 (ex. sigmoid, ReLU)
위 공식은 fully-connected layer, convolutional layer에 모두 적용될 수 있다.
이 때, 비선형함수를 거치기 이전 X = Wu + b를 정규화하는 BN 변환을 수행한다.
레이어 입력값인 u 또한 정규화할 수 있지만 u는 다른 비선형함수의 결과값 형태이므로 분포의 형태는 학습 와중에 바뀔 수 있으며 첫 번째와 두 번째 moments를 제한해도 covariate shift는 제거되지 않는다.
이와는 대조적으로 Wu + b는 비교적 대칭적이고 non-sparse한 분포를 가지기에 "more Gaussian" 하다고 볼 수 있다. 가우시안에 가까운 분포를 정규화하는 것이 안정적인 분포의 activation을 생성할 수 있다.
Wu + b를 정규화할 때, 편향 b는 뒤의 평균 차감에 의해 그 효과가 상쇄되므로 무시할 수 있다.
(정확히는 Alg 1에서 편향이 beta에 포함된다)
따라서 최종 식은 다음과 같이 다시 쓸 수 있다.
$$z=g(BN(Wu))$$
BN transform은 x = Wu의 각 차원에 독립적으로 적용되며, 각 차원 당 학습가능한 파라미터 gamma, beta를 가진다.
convolutional layer를 위해서는 convolutional property에 따르는 정규화를 필요로 한다.
convolutional property에 따르기 위해 같은 피처맵에서 다른 위치에 있는 서로 다른 요소들은 같은 방식으로 정규화된다. 이를 달성하기 위해서 우리는 미니 배치 안에 있는 모든 activation을 jointly normalize해야 한다.
Alg 1. 에서, 우리는 beta를 피처맵 안의 모든 값의 조합이라고 가정했다. 따라서 효율적인 미니 배치의 크기를 다음과 같이 설정했다.
$$m' = |\Beta| = m \times pq$$
- m : 미니 배치 크기
- pq : 피처맵의 크기
Alg 2도 비슷하게 수정되는데, 추론하는 동안 BN 변환이 주어진 피처맵의 각 activation에 동일한 선형 변환을 적용한다.
3.3 Batch Normalization enables higher learning rates
전통적인 딥러닝에서는 너무 높은 학습률은 gradient explode / vanishing 현상을 불러올 위험성이나 local minima에서 학습이 멈추는 위험성을 가지고 있었으나, Batch Normalization은 이를 해결해줄 수 있다.
네트워크 전반을 거쳐 activation을 정규화하며 이는 파라미터의 작은 변화가 증폭되어 gradient에 따른 activation이 최적이 아닌 큰 변화로 이어지는 것을 방지한다. 예를 들어, 학습이 saturated 비선형성 영역에 갇히는 것을 방지한다.
또한 Batch Normalizatino를 사용하면 학습이 파라미터 스케일에 더 탄력적으로 대응할 수 있다. 보통 큰 학습률은 레이어의 파라미터 스케일까지 키우는데, 이는 역전파 과정 중 gradient를 증폭시키고 model explosion을 불러온다. 그러나 batch normalization을 이용하면 역전파가 파라미터의 스케일에 영향을 받지 않는다.
역전파 수식을 살펴보면 그 사실을 알 수 있다. (a는 스칼라)
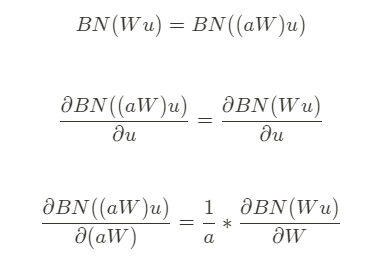
스케일은 레이어의 jacobian 행렬에 영향을 주지 않고, 따라서 gradient propagation에도 영향을 주지 않는다.
더 나아가 큰 가중치는 작은 gradients를 유도하고, Batch normalization이 파라미터 크기가 커지는 것을 안정화시켜줄 것이다. 또한 batch normalization은 레이어의 jacobian 행의 특이값을 1에 가깝게 하며, 이는 학습에 도움을 준다고 알려져있다.
정규화된 입력이 있는 두 개의 연속된 레이어와 정규화된 벡터(\(\hat{z} = F(\hat{x})\) 사이의 변환을 고려해보자.
만약 x hat과 z hat이 가우시안이며 연관성이 없고, \(F(\hat{x}) \sim J\hat{x}\)가 주어진 모델 파라미터에 대한 선형 변환이라 하면 x hat과 z hat은 동일한 unit covariances를 갖는다.
$$I = Cov|\hat{z}| = JCov|\hat{x}|J^T = JJ^T$$
$$JJ^T = I$$
따라서 J의 모든 특잇값은 1과 같으므로 역전파를 하는동안 gradient의 규모는 보존된다.
현실에서 선형변환이 아니고, 정규화된 값이 가우시안이나 독립일 것이라는 보장은 없지만 Batch Normalization이 gradient propagation이 더 잘 동작하도록 도움을 줄 것이라고 예상한다.
gradient propagation에서 Batch Normalization의 정확한 효과는 이후 연구에 맡긴다.
3.4 Batch Normalization regularizes the model
Batch Normalization을 사용하여 학습할 때 학습 예제는 미니 배치의 다른 예제와 함께 표시되며, 네트워크는 더 이상 주어진 학습 예제에 대해 결정론적 값을 생성하지 않는다.
실험해본 결과, 이 효과가 네트워크의 일반화에 유리한 것으로 나타났다. 따라서 과적합을 줄이기 위해 기존에 쓰였던 기법인 Dropout에 대한 의존도를 줄일 수 있다.
4. Experiments
4.1 Activations over time
internal covariate shift의 효과를 확인하고, batch normalization의 가능성을 확인하기 위해서 우리는 MNIST dataset을 이용하기로 했다.
- input : 28*28 binary image
- 3개의 fully-connected 은닉층이 각각 100 activations 가짐
- 각 은닉층은 \(y = g(Wu+b)\)를 sigmoid로 계산
- weight W는 작은 랜덤 gaussian values로 초기화
- 마지막 은닉층은 10개의 activation을 가진 fully-connected layer
- 50000 steps with 60 examples per mini-batch
섹션 3.1에 나온 것처럼 네트워크의 각 은닉층에 Batch Normalization을 추가했다.
MNIST에서 SOTA를 달성하기 보다는 베이스라인과 Batch Normalization이 적용된 네트워크를 비교하는 것에 초점을 맞추고 실험을 진행했다.

- (a) : test data 안에서 학습 과정에 따른 정답 비율 비교 → Batch Normalized 네트워크의 높은 정확도
- (b), (c) : 각 네트워크의 마지막 은닉층의 전형적인 activation에 대해 그 분포가 어떻게 변화하는지 보여
베이스라인 네트워크의 분포 (평균, 분산값) 는 학습이 진행될때마다 많이 바뀌어서 서브 레이어의 학습을 복잡하게 만들었지만, Batch Normalization이 적용된 네트워크에서는 훨씬 안정적인 학습 진행을 보여 BN이 학습을 돕는다는 사실을 입증하였다.
4.2 ImageNet classification
ImageNet classification task로 훈련된 새로운 변형의 Inception Network(Szegedy et al., 2014)에 BN을 적용해보았다. 이 네트워크에는 1000개의 가능성 중 이미지 클래스를 예측하는 softmax 레이어와 함께 다수의 convolution, pooling 레이어가 존재한다.
- Convolution layer는 non-linearity function으로 ReLU 사용
- 원문 (Szegedy et al., 2014) 과 다르게 5*5 convolution layer를 128개의 필터를 가진 3*3 convolution layer로 수정
- 네트워크는 총 13.6 * (10^6) 파라미터를 가짐
- 최상위 softmax layer를 제외하면 fully-connected layer가 존재하지 않음
우리는 이 변형된 모델을 "Inception" 으로 명명할 것이다. 모델은 모멘텀을 사용한 미니배치 SGD로 학습되었고 미니배치 사이즈는 32이다. 모든 네트워크는 훈련이 진행됨에 따라 이미지 당 단일 크롭을 사용하여 holdout set에서 유효성 검사 정확도 @1, 즉 1000개의 가능성 중 올바른 레이블을 예측할 확률을 계산하여 평가한다.
실험에서 모델에 batch normalization을 넣어 변경한 여러가지 모델을 실험해보았는데, 섹션 3.2에서 서술한 것처럼 모든 경우에서 batch normalization은 각 non-linearity의 입력값에 적용되었고, 나머지 아키텍처는 유지했다.
4.2.1 Accelerating BN Networks
그저 네트워크에 BN을 추가하는 것만으로는 이점을 온전히 누릴 수 없다. 따라서 우리는 네트워크와 그의 학습 파라미터를 변경했다.
- 학습률 높이기 : batch normalization을 통해 우리는 학습률을 부작용없이 늘릴 수 있었고, 이는 다른 부작용없이 학습 속도를 높일 수 있게 한다.
- Dropout 없애기 : 섹션 3.4에서 설명한 것처럼 Batch Normalization은 dropout의 목표 (모델의 일반화 성능을 높이기 위한 규제) 와 동일한 작업을 수행한다. dropout을 없애며 overfitting을 늘리는 일 없이 속도를 빠르게 할 수 있었다.
- L2 가중치 규제 줄이기 : L2 규제는 overfitting을 줄이기 위해 존재하는데, 변경한 네트워크에서 이 loss 값 가중치를 5로 나누어 줄인 다음 적용했더니 검증 데이터에서 더 나은 정확도를 보였다.
- learning rate decay 가속 : 기존 학습에서는 학습률이 지수적으로 감소했지만, 변경 네트워크에서는 베이스라인보다 학습이 빠르므로 6배 빠르게 감소하도록 설정했다.
- Local Response 정규화 없애기 : 원본 논문에서는 여기서 성능 향상을 얻었다고 하나, Batch Normalization이 있으면 불필요하기에 제거했다.
- 학습 예제 좀 더 철저히 섞기 : 학습 데이터의 shard shuffling 이 가능하도록 해 미니배치에서 같은 예시가 나타나는 것을 방지했으며 이는 1%의 정확도 향상을 가져왔다.
- photometric distortions (광도 왜곡) 줄이기 : Batch Normalized 네트워크는 더 학습을 빠르게하며 각 학습 예제를 적게 보기 때문에 모델이 "진짜 이미지"에 더 집중할 수 있도록 했다.
Learning rate decay?
기존의 학습률이 높은 경우 loss 값을 빠르게 내리지만 최적값을 벗어날 수 있고, 학습률이 낮은 경우 시간이 너무 오래 걸린다는 단점을 해결하기 위해 도입됨
처음 시작 시 학습률 값을 크게 준 후 일정 epoch마다 값을 감소시켜 최적 학습까지 더 빠르게 도달할 수 있게 하는 방법
Photometric distortion?
이미지 데이터 증강을 위해 광도를 왜곡한 이미지를 생성하는 것을 말함
밝기, 대비, 색조, 채도, 노이즈 조정을 통해 이루어짐
4.2.2 Single-Network Classifcation
LSVRC2012 데이터로 학습하고 validation data를 통해 이를 평가했다.
- Inception : 위에서 서술한 기존 네트워크. 초기 학습률 = 0.0015
- BN_baseline : Inception과 동일하나 각 nonlinearity 전에 Batch Normalization 적용
- BN-x5 : Inception에 Batch Normalization 적용 및 섹션 4.2.1에서의 변경 사항 (학습률 높이기, dropout 없애기 등) 적용. 초기 학습률은 5의 배수로 0.0075까지 증가. 기존 Inception 모델에 증가를 적용할 경우 model explode 발생
- BN-x30 : BN-x5와 같으나 ReLU대신 sigmoid nonlinearity 적용
각 변형 네트워크의 학습 진행에 따른 정확도는 아래 그래프와 같다.


각 네트워크에 대해 동일한 72.2%의 정확도에 도달하는 데 필요한 훈련 단계 수와 네트워크가 도달한 최대 유효성 검사 정확도 및 이에 도달하기 위한 step 수를 보여준다.
- Batch Normalization만 사용하여 (BN-baseline) 학습 step 수를 절반 이하로 줄이면서 Inception의 정확도에 도달
- 4.2.1절의 수정 사항을 적용해 네트워크의 학습 속도를 크게 높임
- BN-x5는 Inception보다 14배 적은 학습 step
- 학습률을 더 늘리면 (BN-x30) 모델의 초기 학습 속도는 다소 느려지지만 최종 정확도는 더 높아짐
또한 internal convariate shift를 줄임으로써 일반적으로 어렵다고 알려져있던 sigmoid를 nonlinearity로 사용하는 학습도 가능하다는 것을 확인했다. 실제로 BN-x5-sigmoid는 69.8%의 정확도를 달성했으며, Batch Normalization을 사용하지 않을 경우 (Inception with sigmoid) 1/1000 이상의 정확도를 달성하지 못한다.
4.2.3 Ensemble Classification
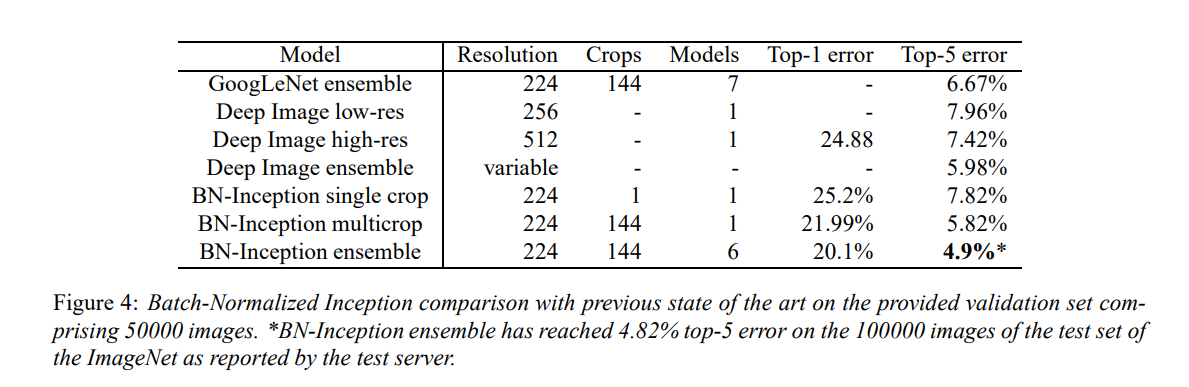
현재 ImageNet Large Scale Visual Recognition Competition에서 가장 좋은 결과는 앙상블 모델에 의해 달성되었다. 최근에 top-5 validation error 4.94%까지 달성했는데, 우리는 top-5 validation error를 4.9%, test error를 4.82% 까지 달성했다. 이는 최고 결과이고 심지어 사람의 성능까지 초월한 결과이다.
앙상블을 위해서 6개의 네트워크를 사용했고, 각각 BN-x30을 기반으로 하며 다음과 같은 몇 가지 변경점을 추가했다.
- convolutional layer의 초기 가중치 증가
- dropout 사용 (5%, 10%)
- non-convolutional, per-activation Batch Normalization 을 모델의 마지막 은닉층에 사용
각 네트워크는 6*(10^6) 학습 step이후 최고 정확도를 달성했고 앙상블 예측 시에는 산술평균을 사용했다.
앙상블 모델 성능은 다음과 같다.
5. Conclusion
본 논문에서는 covariate shift가 존재하고 이것을 제거하는 것이 학습에 도움을 준다는 가정하에 깊은 신경망의 학습을 빠르게 해줄 수 있는 방법을 개발했다.
Batch normalization은 actication을 정규화하고 이를 네트워크 아키텍처 자체에 통합하는 형태로 적용된다. 이렇게 하면 네트워크 학습에 사용되는 모든 최적화 방법에 의해 정규화가 적절하게 처리된다.
네트워크에 단순히 적용하는 것 뿐 아니라 장점을 제대로 활용하기 위해서는 초기 학습률을 늘리고, dropout을 제거하는 등의 변경점을 같이 적용할 경우 성능을 극대화할 수 있다는 사실을 알 수 있었다. 신경망 학습에 일반적으로 사용되는 mini-batch SGD를 활용하기 위해 각 mini-batch에 대해 정규화를 수행하고 파라미터를 통해 gradient 를 역전파한다.
Batch Normalization은 activation 당 두 개의 파라미터만 추가하며 이를 통해 네트워크의 표현 능력을 보존할 수 있다.
본 논문에서 Batch Normalization이 잠재적으로 구현할 수 있는 모든 가능성을 탐구하지는 않았다. RNN에서도 internal covariate shift와 vanishing & exploding gradient 문제가 심각할 수 있으며, Batch Normalziation이 이를 개선할 수 있다는 가설을 철저히 테스트해볼 수 있다. 또한 알고리즘에 대한 추가적 이론 분석을 통해 더 많은 개선과 응용이 이후 연구에서 이루어질 것이라고 생각한다.
'NLP > 논문리뷰' 카테고리의 다른 글
| [논문 Review] 05. (GPT-2) Language Models are Unsupervised Multitask Learners (2) | 2023.12.06 |
|---|---|
| [논문 Review] 04. Overview of Gradient Descent algorithms (2) | 2023.11.29 |
| [논문 Review] 03. (GPT-1) Improving Language Understanding by Generative Pre-Training (1) | 2023.03.26 |
| [논문 Review] 02. Attention is All you need (0) | 2023.03.26 |
| [논문 Review] 00. 개요 & 로드맵 (0) | 2022.12.31 |


