페르소나의 특징을 유형화하고, 그 페르소나가 가질 수 있는 특징을 Knowledge Graph 형태로 연결하자
https://aclanthology.org/2023.acl-long.362/
PeaCoK: Persona Commonsense Knowledge for Consistent and Engaging Narratives
Silin Gao, Beatriz Borges, Soyoung Oh, Deniz Bayazit, Saya Kanno, Hiromi Wakaki, Yuki Mitsufuji, Antoine Bosselut. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023.
aclanthology.org
스캐터랩의 ACL 2023 Review 블로그 글을 통해 접하게 된 논문이다.
해당 논문 이외에도 dialogue model, persona에 대한 다양한 논문이 소개되어 있으니 참고해보면 좋을 것 같다.
Abstract
사용자와의 대화 중 일관된 페르소나를 유지하는 것은 챗봇 개발에 매우 중요한 요소이다. 그러나 페르소나는 다양하고 복잡한 world knowledge를 포함하고 있으므로 일반적인 내러티브 시스템으로는 구현하기 힘들 수 있다.
따라서 이번 연구에서는 새로운 대규모 persona common-sense knowledge graph인 PEACOK을 구축했다.
1. Introduction
페르소나를 가진 챗봇은 다양한 행동을 보이는데, 자신이 부여받은 페르소나 뿐만 아니라 상호작용하는 상대방의 페르소나에 영향을 받기도 한다.
예를 들어 챗봇의 페르소나가 '모험심이 강한 건축가' 라고 해보자.
이 페르소나는 친구들과 야외 탐험에 대해 얘기하는 것에도 관심을 가지지만, 직장 동료들과 함께 건축 설계 아이디어에 대해 논의하는 것에도 관심을 가질 수 있다.
이렇듯 챗봇은 가지고 있는 본인의 프로필을 기반으로 상대 / 상황에 따라서 적절하게 대답해야 한다.
다양한 페르소나 속성을 모델링하는 목표는 이전부터 연구되어 왔지만 풍부한 world knowledge와 무수히 많은 interaction을 포함해야 하기 때문에, 단순히 데이터만으로는 학습을 하기 어렵다.
이를 해결하기 위한 선행 연구들을 알아보자.
- Mazare et al., 2018
Reddit 에서 댓글을 수집하여 페르소나 프로필 규모를 확장시킴
그러나 수집된 정보가 파편화되어있다는 문제점이 존재하고, 페르소나 간의 상호작용까지는 구현하지 못함 - Majumder et al., 2020
Knowledge generator를 통해 commonsense inference를 수행하여 페르소나 프로필을 확장시킴
일반적인 상식 추론으로 제한되며 체계적인 페르소나 확장은 구현하지 못해서 일관성이 떨어짐
기존 연구들의 한계를 개선하고자, 이전에 제안된 페르소나의 개념과 인간 행동분석 문헌을 바탕으로 페르소나를 다섯 가지의 특성으로 나눠 프레임을 세분화한다.
- characteristics (고유 특성)
- routines and habits (루틴과 습관)
- goals and plans (목표 및 계획)
- experiences (경험)
- relationships (관계)
이 프레임을 사용해 기존의 knowledge frame에서 추출 & pre-trained LLM에서 persona knowledge를 생성하여 대규모의 persona KG를 만들었으며, 그 결과물인 PEACOK은 100K개의 commonsense inference를 포함하고 있다.
2. Related Work
Commonsense Knowledge Graphs
NLP 태스크에서 암시적으로 world knowledge를 반영하기 위해 ConceptNet, ATOMIC, ANION, Atomic 2020과 같은 Commonsense KG가 쓰이고 있었다.
Persona-Grounded Narratives
PERSONA-CHAT1 에서는 참여자에게 할당된 페르소나 프로필 (자기소개문 5개의 문장) 을 기반으로 대화를 수행하도록 요청해 크라우드 소싱 대화 데이터셋을 구축했다. 최근의 연구에서는 다음과 같은 연구를 통해 페르소나 모델링을 개선했다.
- 온라인 리소스를 통해 페르소나 프로필을 생성2
- 페르소나 Detector & Predictor를 훈련3 4
- Commonsense inference를 통해 Persona Knowledge를 추출5
해당 연구들은 페르소나 간의 상호작용을 암시적으로 모델링했는데, PEACOK에서는 페르소나 간 상호 연결을 명시적으로 표현해서 페르소나 상호 작용 모델링을 가능하게 했다.
3. PEACOK Knowledge Frame
페르소나 지식의 체계적인 표현을 구축하기 위해서 1개의 Main persona를 5개의 relations로 표현하였고, 각 relation에는 여러 가지 attributes 가 붙어있다.
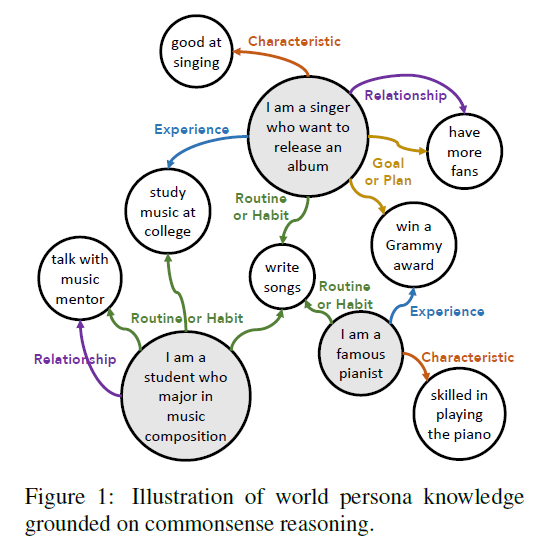
Relations
- Characteristics : 페르소나가 가지고 있는 본질적인 특성
ex. '앨범을 준비하는 가수' 페르소나가 노래를 잘하는 것 (Good at singing) - Routines or Habits : 페르소나가 정기적으로 하는 외적 행동
ex. '앨범을 준비하는 가수' 페르소나가 정기적으로 노래를 작곡하는 것 (Write songs) - Goals or Plans : 페르소나가 미래에 달성하거나 하고 싶은 외적 행동이나 결과
ex. '앨범을 준비하는 가수' 페르소나가 그래미상 수상을 목표로 하는 것 (Win a Grammy award) - Experiences : 페르소나가 과거에 했던 외적인 사건이나 활동을 설명
ex. '앨범을 준비하는 가수' 페르소나가 대학에서 음악을 전공한 것 (Study music at college) - Relationships : 다른 사람 또는 소셜 그룹과의 상호 작용 가능성을 포함함
ex. '앨범을 준비하는 가수' 페르소나가 더 많은 팬을 원하는 것 (Have more fans)
이 때 Relationship은 다른 Relations와 중복될 수 있다.
예를 들어 가수가 더 많은 팬을 원하는 것은 '가수 페르소나' - '팬 페르소나' 사이 관계를 의미하기도 하지만, 가수의 미래 목표 & 계획이 될수도 있다.
4. PEACOK Construction
- Persona : Head entity
- Relations : Edge
- Attributes : Tail entity
Persona knowledge Graph는 위의 요소를 가지는 (Head - Relation - Tail) 의 3단 구조로 이루어진다.
구성된 그래프를 바탕으로 아래 3단계 절차를 거쳐 PEACOK 전체 그래프를 구성한다.
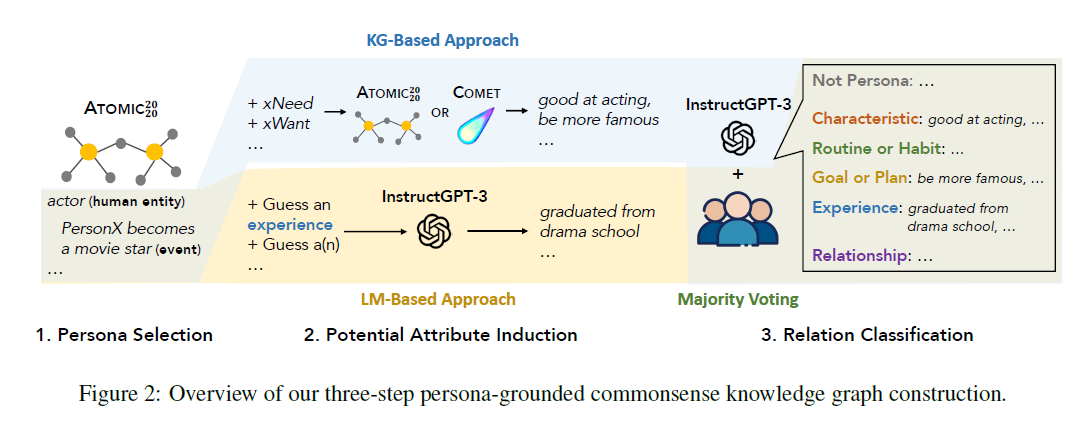
1. Persona Selection
기존 ATOMIC2020과 같은 commonsense KG 중에 head persona로 사용할 수 있는 entity를 찾는다.
페르소나와 관련된 entity는 동물이나 무생물이 아닌 인간에 관한 것이어야 한다고 가정하고, 우선적으로 CapableOf relation을 가진 Head entity를 추출한다. 이후 추출된 entity에서 인간이 아니거나, 너무 일반적이거나 비현실적인 (ex. human, devil) 존재를 수동으로 필터링한다.
이 과정에서 큰 분류의 페르소나를 얻을 수 있다. (ex. actor, singer)
보다 세분화된 페르소나 (ex. actor -> actor who acts in movies, actor who acts in plays) 로 확대하기 위해서 initial persona set에서 파생된 3가지 유형의 event-based entity를 사용해 추가 페르소나 후보를 수집한다.
- 초기 페르소나보다 복합적인 문맥을 가진 엔티티
ex. 배우로써의 엔티티보다는 배우가 되는 과정과 연관된 엔티티 - ATOMIC 2020 에서 CapableOf relation을 통해 초기 페르소나와 연결될 수 있는 엔티티
ex. "X acts in play" 에서 entity X는 "actor"와 연결될 수 있다 - SBERT에 의해 retrieval되는 엔티티
ATOMIC2020?
ATOMIC 2020 Dataset — Allen Institute for AI
최종적으로 InstructGPT-3를 통해 확장된 페르소나 문장 중 초기 페르소나에 해당되지 않는 것을 필터링하여 3.8K 개의 페르소나를 추출했고, 이를 Persona statements로 변환해 PEACOK에 통합했다.

2. Potential Attribute Induction
수집된 head persona set과 사전에 설정한 5개의 Relations를 바탕으로, hand-crafted KG & langugage corpora에서 pre-trained LLM을 통해 attribute를 얻어내는 과정이다.
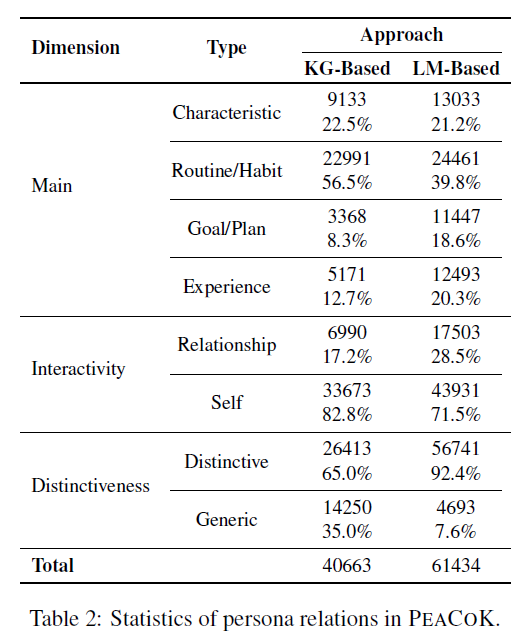
KG-Based Approach
KG-Based Approach에서는 기존 KG를 활용하여 페르소나의 속성을 추출한다.
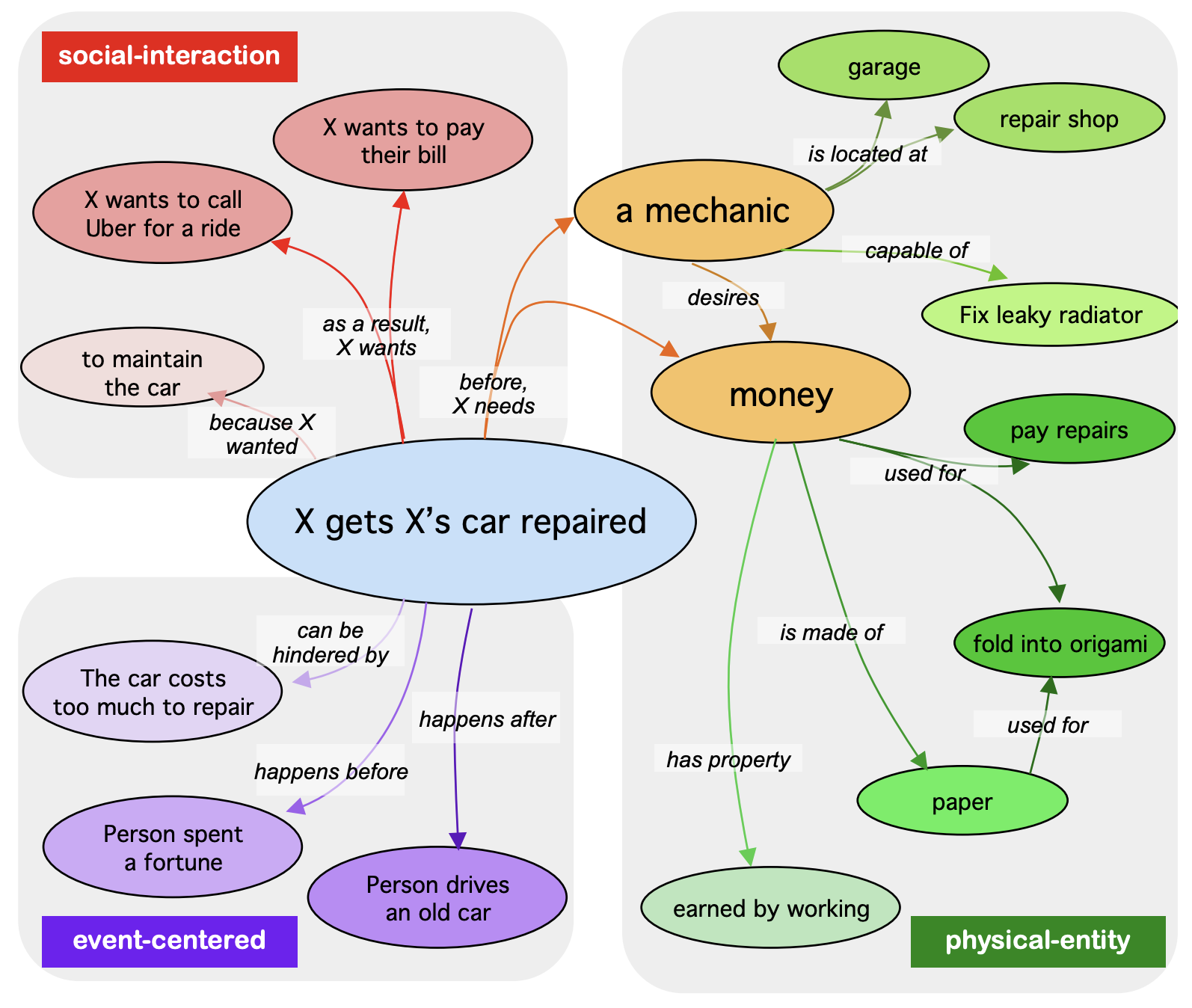
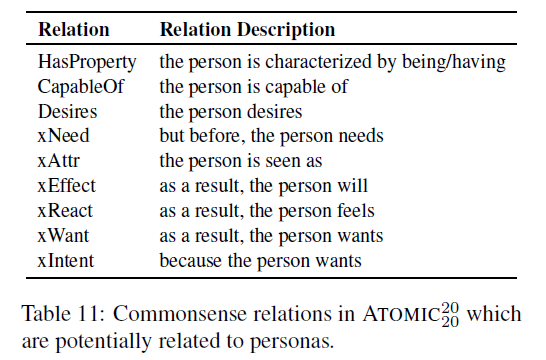
ATOMIC2020에서 각 persona knowledge와 잠재적으로 연관성이 있는 10개의 commonsense relation을 선택하고, 1-hop inference를 수행해서 속성을 추출한다.
"CapableOf" Relation을 통해 특정 페르소나가 수행할 수 있는 행동 (ex. "Singer" - "Song") 을 추출

이 때 ATOMIC 2020만 활용하면 지식 범위가 제한적이기 때문에, ATOIMIC 2020에 대해 사전학습된 knowledge model COMET을 사용해 추가적으로 각 페르소나에 대한 잠재적 속성을 생성한다.
COMET
https://github.com/allenai/comet-atomic-2020
GitHub - allenai/comet-atomic-2020
Contribute to allenai/comet-atomic-2020 development by creating an account on GitHub.
github.com
https://www.semanticscholar.org/paper/COMET-ATOMIC-2020%3A-On-Symbolic-and-Neural-Knowledge-Hwang-Bhagavatula/f8a22859230e0ccafefc020dccc66b5a646fe0ac
www.semanticscholar.org
GPT 혹은 BART 모델로 ATOMIC 2020 학습한 knowledge model
LM-Based Approach
자연어 말뭉치에 존재하는 더 많은 persona knowledge를 추출하기 위해 InsturctGPT-3로 하여금 새로운 페르소나 속성을 생성하도록 한다.
InsturctGPT-3에 persona statements를 프롬프트로 넣어주고, 이전에 정의한 5개의 Relation에 대해 5개의 새로운 속성을 생성하도록 지시한다.
"Experience" : 페르소나에 맞게 과거에 수행했을 특정 활동을 추론하도록 지시

KG-Based Approach는 페르소나에 대한 구조화된 상식을 제공하는 반면, LM-Based Approach는 더 넓은 범위의 자연어 데이터에서 페르소나 정보를 발굴하여 페르소나 프로필을 더 풍부하게 만드는 데 기여한다.
3. Relation Classification
LLM이 포함된 크라우드소싱을 사용해 페르소나 추론이 유효한지 여부를 분류한다.
이 때 Labeling schema를 세분화해서 작업자들이 서로 다른 관계를 더 잘 구분하고 정확하게 평가할 수 있도록 했다.
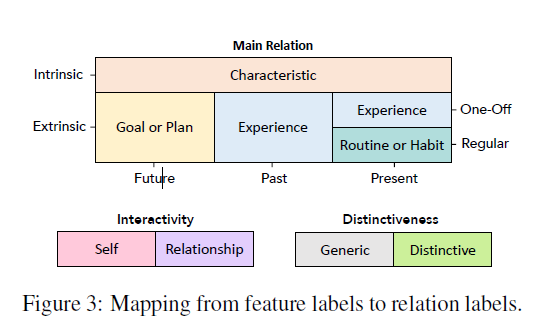
각 attribute에 대해 2명의 작업자에게 다음과 같은 사항에 대한 평가를 요청했다.
- 페르소나의 내재적 / 외재적 특징
- 페르소나의 일회성 / 정기적 속성
- 페르소나의 과거, 현재, 미래 속성
- 페르소나 그 자체만의 속성 / 다른 페르소나와의 관계를 설명하는지 (interactivity)
- 페르소나와 고유하게 연관되어 있는지 / 여러 잠재적 페르소나와 일반적으로 연관되어 있는지 (distinctiveness)
ex. '고객으로부터 팁 받기'는 '웨이터' 페르소나와 고유하게 연관되어 있다고 볼 수 있으나, '더 나아지기' 는 여러 페르소나의 잠재적 목표가 될 수 있으므로 고유 연관성이 떨어진다고 볼 수 있다.


Majority Voting with LM in the Loop
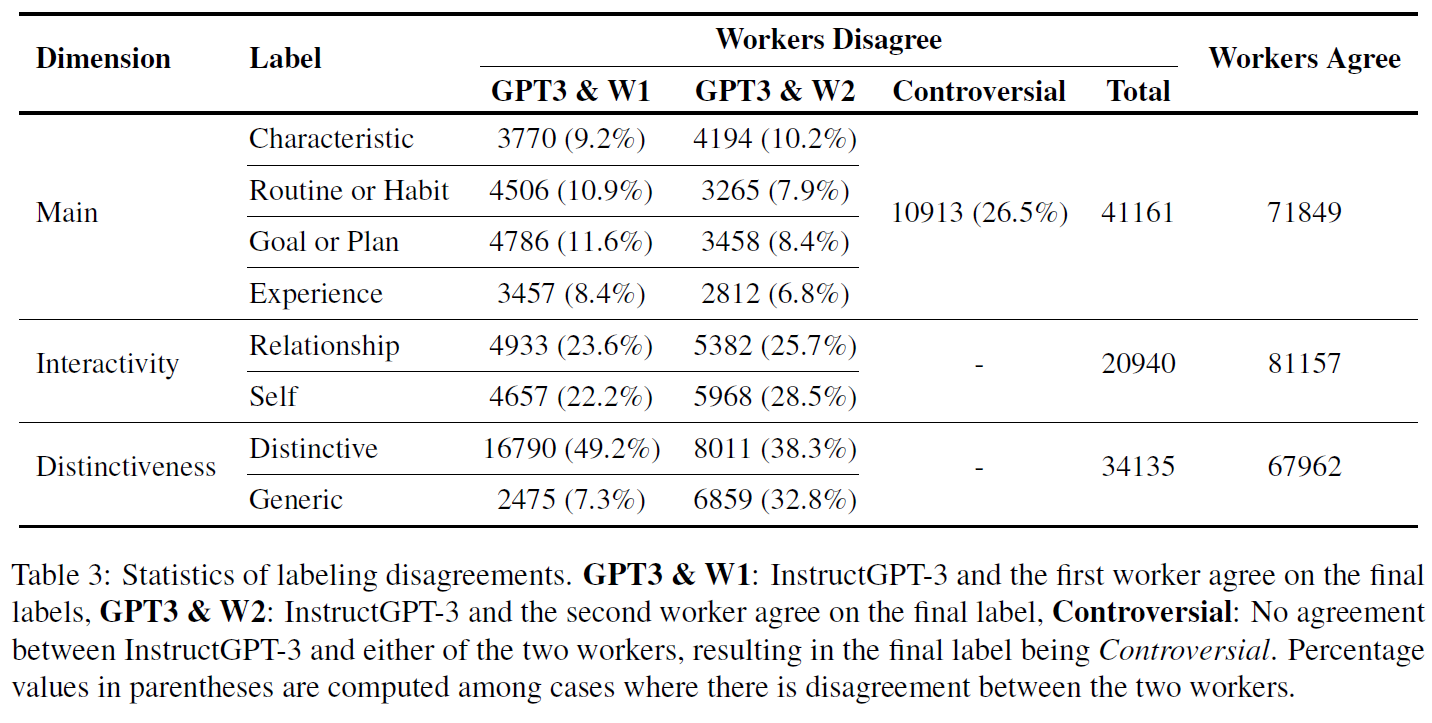
2명의 작업자 이외에 InstructGPT-3가 주어진 attribute에 대해 label을 생성하도록 하고, 다수결 투표 방식으로 최종 라벨을 결정하도록 했다.
5. PEACOK Analysis
최종적으로 구축한 데이터는 다음과 같다.
Persona Interconnectivity
PEACOK에서는 다양한 지식 습득 뿐만 아니라, 페르소나 간의 상호 연결성도 포함되어 있다.
PEACOK의 40,665 distinctive attributes 중 9,242개의 attributes는 2개 이상의 페르소나에 연결되어서 총 239,812개의 연결된 페르소나 조합을 형성한다.
Attribute Disagreements
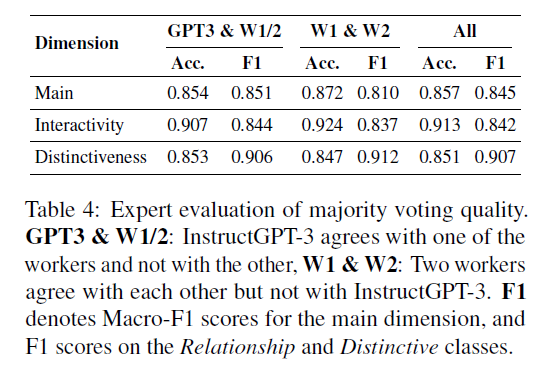
InstructGPT-3를 도입해서 의견 불일치를 효과적으로 해결할 수 있었고, 정확성을 다시 한 번 검증하기 위해 연구 그룹의 전문가가 825개의 persona fact relations를 다시 평가했고, 실험의 유효성을 입증할 수 있었다.
6. Generalizing Persona Knowledge
PEACOK이 inference generator를 훈련하는 데 쓰일 수 있는지를 평가했다.
BART-based COMET knowledge generator (COMET-BART)를 65K개의 PEACOK training set으로 훈련했고, 3030개의 test set으로 평가를 진행했다.
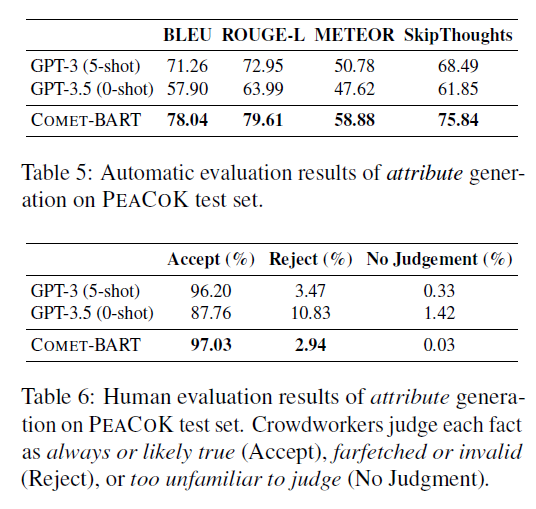
few-shot GPT와 비교했을 때 PEACOK으로 훈련된 COMET-BART는 훨씬 작은 모델임에도 불구하고 다양한 NLG 지표에서 더 나은 성능을 보였고, Human Evaluation에서도 마찬가지였다.
7. Enhancing Dialogue Systems
dialogue system 성능 향상에도 도움이 되는지 검증하기 위해 PEACOK을 사용하여 현재 SOTA인 페르소나 기반 dialogue model인 P^2 bot을 보강했다.
PEACOK에 존재하는 fact를 dialogue에 연결해서 P^2 bot의 persona perception을 확장하고, 대화 생성 응답 능력을 강화했는데, 세부적인 과정은 아래와 같다.
상대방의 PERSONA-CHAT 프로필과 dialogue내의 발언을 기반으로 PEACOK 지식을 대화 상대방에게 연결
- 각 대화 상대방에 대해 프로필의 모든 문장 + dialogue내의 발언에서 일인칭 문장을 추출
- 임베딩 유사도를 비교 후 각 문장과 관련된 PEACOK의 candidate fact sentence를 linking ( -> 이 과정에서 고유성이 낮은 사실들은 제거)
- ComFact 데이터셋에서 훈련한 DeBERTa Entity linker를 사용해 candidate fact 중 관련성 높은 fact들을 선별
- 이후에는 원래의 P^2 모델과 동일한 세팅으로 학습 진행
ConvAI2 PERSONA-CHAT 데이터셋을 기반으로 모델을 평가하였으며, 평가지표는 PPL, F1, 4-gram BLEU, Hits@1 (=실제 응답이 가장 높은 순위를 차지할 확률) 을 사용했다.
ConvAI2 PERSONA-CHAT?
https://paperswithcode.com/dataset/convai2
Papers with Code - ConvAI2 Dataset
The ConvAI2 NeurIPS competition aimed at finding approaches to creating high-quality dialogue agents capable of meaningful open domain conversation. The ConvAI2 dataset for training models is based on the PERSONA-CHAT dataset. The speaker pairs each have a
paperswithcode.com
데이터셋에는 각각 17,878개와 1,000개의 대화가 train & validation을 위해 제공되고, 1,015개의 test set은 공개되지 않았다.
데이터셋 예시
{ "dialog_id": "0x648cc5b7", "dialog": [ { "id": 0, "sender": "participant2", "text": "Hi! How is your day? \ud83d\ude09", "sender_class": "Bot" }, { "id": 1, "sender": "participant1", "text": "Hi! Great!", "sender_class": "Human" }, { "id": 2, "sender": "participant2", "text": "I am good thanks for asking are you currently in high school?", "sender_class": "Bot" } ], "bot_profile": [ "my current goal is to run a k.", "when i grow up i want to be a physical therapist.", "i'm currently in high school.", "i make straight as in school.", "i won homecoming queen this year." ], "user_profile": [ "my favorite color is red.", "i enjoy listening to classical music.", "i'm a christian.", "i can drive a tractor." ], "eval_score": 4, "profile_match": 1 }
정량적 지표 뿐만 아니라 Human-evaluation도 진행했는데, 총 4가지 항목 (유창성, 일관성, 참여도, 페르소나 표현) 으로 세분화하여 평가를 진행했다.
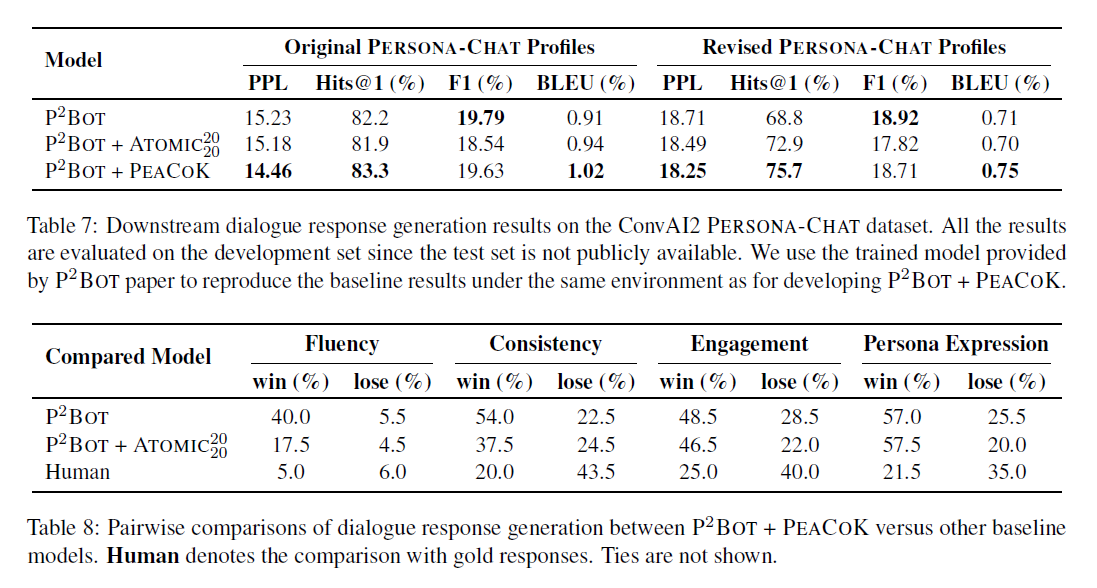

흥미로운 점은 두 페르소나 간 공유 속성 (=interconnection) 이 많을수록 더 높은 Consistency와 Engagement 수치를 기록했다는 점이다.
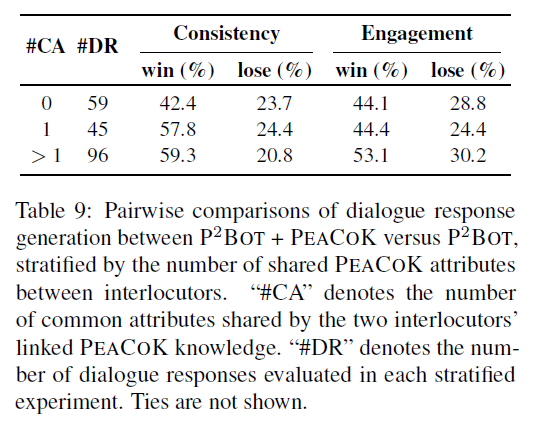
이를 통해 대화자와의 interconnection이 많아질수록 더 일관되고 매력적인 대화를 할 수 있으며, interconnected world persona knowledge를 습득하는 것이 매우 중요하다는 사실을 알 수 있었다.
참고 문헌
- Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston. 2018. Personalizing dialogue agents: I have a dog, do you have pets too? In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2204–2213. [본문으로]
- Pierre-Emmanuel Mazare, Samuel Humeau, Martin Raison, and Antoine Bordes. 2018. Training millions of personalized dialogue agents. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2775–2779. [본문으로]
- Jia-Chen Gu, Zhenhua Ling, YuWu, Quan Liu, Zhigang
Chen, and Xiaodan Zhu. 2021. Detecting speaker personas from conversational texts. In Proceedings
of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 1126–1136. [본문으로] - Wangchunshu Zhou, Qifei Li, and Chenle Li. 2021. Learning to predict persona information for dialogue
personalization without explicit persona description. arXiv preprint arXiv:2111.15093. [본문으로] - Bodhisattwa Prasad Majumder, Harsh Jhamtani, Taylor Berg-Kirkpatrick, and Julian McAuley. 2020. Like hiking? you probably enjoy nature: Personagrounded dialog with commonsense expansions. In Proceedings of the 2020 Conference on Empirical
Methods in Natural Language Processing (EMNLP), pages 9194–9206. [본문으로]



