이전 포스팅 ( https://ll2ll.tistory.com/117 ) 에 이어서, 선행 연구를 통해 얻은 인사이트를 토대로 Contrastive Learning을 위한 데이터셋을 설계하고 구축하는 방법에 대해 고민해보고자 한다.
한국어 NLI Dataset
Supervised Learning을 위함
가장 유명한 한국어 NLI Dataset인 KorNLU, KLUE부터 알아보자.
KorNLU (KorSTS / KorNLI)
Paper : https://arxiv.org/abs/2004.03289
Github : https://github.com/kakaobrain/kor-nlu-datasets
- KorNLI : SNLI, MNLI, XNLI로부터 수집 / KorSTS : STS-B로부터 수집
- KorNLI는 기계 번역을 거쳤기 때문에, 한국어에서 자주 쓰이지 않는 관사(그), 지시사(이것, 저것, 그것 등)가 많음
- MNLI : 기계 번역으로 △ 제대로 번역되지 않고 △ 정제되지 않은 값(n/a, 의성어, 의태어)이 많음.
- SNLI : 기계 번역이지만 제대로 번역된 값이 대다수임. 원본이 이미지 캡션에 기반한 문장 쌍이라서 대체로 장면 묘사가 많음.
구축 과정
영어권 데이터셋인 SNLI, MNLI, STS-B를 기계번역한 후 후편집 & 검토 과정을 거침
- SNLI ( https://arxiv.org/abs/1508.05326 )
- Premise : Flickr30k corpus에서 160k개의 caption (이미지 장면을 묘사한 비교적 간단한 문장)
-> 캡션은 작업자가 이미지를 보지 않고 작성하도록 하여 텍스트만으로 문장 관계를 추론할 수 있도록 함 - Hypothesis : 크라우드 소싱 작업자를 통해 생성
- SNLI 데이터 중 약 10%는 추가 검증 과정을 거쳤습니다.
- 각 문장 쌍에 대해 5명의 작업자가 레이블을 제공했고, 3명 이상의 작업자가 일치한 경우 이를 골드 레이블로 지정
- Premise : Flickr30k corpus에서 160k개의 caption (이미지 장면을 묘사한 비교적 간단한 문장)
- MNLI ( https://arxiv.org/abs/1704.05426 )
- Premise : 10개의 서로 다른 장르의 영어 텍스트에서 문장을 추출
-> 정부 문서, 소설, 전화 대화, 여행 가이드, 9/11 보고서, Slate 잡지 기사, Verbatim 아카이브 글, 교육 서적, 면대면 대화, 편지 등 - Hypothesis : 크라우드소싱 작업자를 통해 문장 생성
- 4명의 추가 작업자가 각 문장 쌍에 대해 다수결을 통해 골드 레이블을 결정
- SNLI와 유사하게 전제와 가설 간의 관계를 나타내는 세 가지 레이블(ENTAILMENT, CONTRADICTION, NEUTRAL)을 사용하지만, 문장의 길이와 장르적 다양성이 훨씬 큼
- 평균 전제 문장은 약 22.3 단어로, SNLI(14.1 단어)보다 길고, 다양한 복잡성을 포함
- Premise : 10개의 서로 다른 장르의 영어 텍스트에서 문장을 추출
KLUE-NLI
- 기계번역이 아니라 직접 구축해서 KLUE-NLI는 보다 자연스러움
- Premise : 6개의 다른 소스
- WIKITREE, POLICY, WIKINEWS, WIKIPEDIA (공식적 문체)
- NSMC, AIRBNB (구어체, 각각 영화 리뷰와 여행 리뷰)
- Hypothesis
- 각 문장 쌍에 대해 5명의 작업자(가설 작성자 포함)가 레이블을 제공합니다.
- 3명 이상의 다수결로 골드 레이블을 결정합니다.
- Premise : 6개의 다른 소스
→ 하지만 여전히 비금융 텍스트가 압도적으로 많음
→ 따라서, 학습 과정에 등장하지 않았기에 금융 도메인에서 문장의 의미를 제대로 이해하지 못할 가능성이 높음
도메인 전문 지식이 담겨있는 Dataset / Benchmark를 만들어야 할 필요성 존재
여기서 크게 2가지 방법을 생각했다.
1. KorNLI/KorSTS처럼 기계번역을 돌린다
- 장점
- 가장 빠르게 구축 가능 -> 이미 구축되어 있는 금융 도메인 영어 데이터셋이 충분히 많기 때문
- 크라우드 소싱 / 직접 데이터 구축에 비해 인력, 시간 비용 절감
- 단점
- 번역 퀄리티 -> 다소 LLM 의존적...
- 다만 LLM이 발전한 만큼, 이전 세대의 KorNLI / KorSTS 보다는 좋은 번역 품질일 것으로 예상
2. 원천 데이터로부터 직접 데이터 구축
- 장점
- 원하는 데이터 소스로부터 다양하게 수집 가능
- 사람의 검수 -> 고품질의 데이터셋 구축 가능
- 단점
- 인력, 시간 비용 높음
현재 뉴스 크롤링 등을 통해서 많은 양의 원천 데이터가 수집되어 있으므로, 이를 가공하는 방향을 택하기로 했다.
더불어, Bi-lingual model 구축을 위해서 쓸만한 영어 오픈소스 데이터를 조사해보았다.
<수집 기준>
1. 평가 데이터셋 벤치마크 (FinMTEB) 에 포함되어 있지 않으며
2. 가공이 쉽고
3. 여러 곳에서 쓰이는 (=신뢰도 높은)
4. 비교적 최신의 데이터
→ 조건을 토대로 가공 우선순위 정하기
FinMTEB (Finance Massive Text Embedding Benchmark)
64개의 financial domain-specific text datasets으로 이루어진, Finance Embedding Benchmark
https://arxiv.org/abs/2409.18511
Do We Need Domain-Specific Embedding Models? An Empirical Investigation
Embedding models play a crucial role in representing and retrieving information across various NLP applications. Recent advancements in Large Language Models (LLMs) have further enhanced the performance of embedding models, which are trained on massive amo
arxiv.org
https://github.com/yixuantt/finmteb?tab=readme-ov-file
속해있는 하위 데이터셋은 다음과 같다.




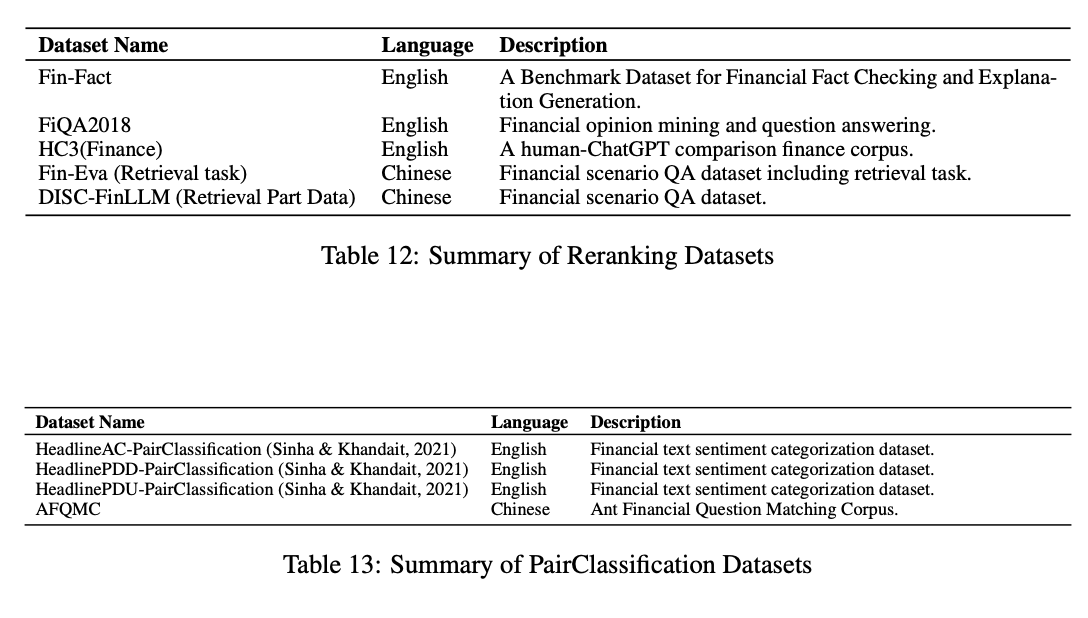
여기 속해있는 하위 데이터셋들은 평가용으로 활용해야 하므로, 학습에는 사용하지 않는다.
영어 평가 데이터셋은 아마 그대로 사용할 것 같고, 한국어 평가 데이터셋은... 번역해서 직접 구축해야 하나?
KRX-Bench를 사용해보는 것도 좋을 것 같다.
금융 도메인 오픈 소스 데이터 (영어)
FinLang
https://huggingface.co/FinLang/finance-embeddings-investopedia
FinLang/finance-embeddings-investopedia · Hugging Face
FinLang/finance-embeddings-investopedia This is the Investopedia embedding for finance application by the FinLang team. The model is trained using our open-sourced finance dataset from https://huggingface.co/datasets/FinLang/investopedia-embedding-dataset
huggingface.co
https://huggingface.co/datasets/FinLang/investopedia-instruction-tuning-dataset
FinLang/investopedia-instruction-tuning-dataset · Datasets at Hugging Face
Question: What factors are considered when applying for a HECM, and what are some things to consider when choosing a reverse mortgage loan? Answer: When applying for a HECM, the lender will verify your income, assets, monthly living expenses, credit histor
huggingface.co

- Eval dataset (FinMTEB) 에 포함되지 않으며, QA 형태로 되어있어 활용에 가장 적합하다고 판단
- License : Since non-commercial datasets are used for fine-tuning, we release this model as cc-by-nc-4.0.
- 데이터 예시
| Topic | mortgage |
| Title | '<title>Residual Standard Deviation: Definition, Formula, and Examples</title>’ |
| Context | '\nStart by calculating residual values. For example, assuming you have a set of four observed values for an unnamed experiment, the table below shows y values observed and recorded for given values of x:\nx\ny\n1\n1\n2\n4\n3\n6\n4\n7\nIf the linear equation or slope of the line predicted by the data in the model is given as yest = 1x + 2 where yest = predicted y value, the residual for each observation can be found’ |
| Question | ' In the given passage, how are residual values calculated for an unnamed experiment with a linear equation yest = 1x + 2? \n’ |
| Answer | ' Residual values for an unnamed experiment are calculated by using the given linear equation yest = 1x + 2 with the observed data provided in the table. For each observation, the residual can be found by comparing the predicted y value (yest) with the observed y value.’ |
학습용 데이터셋 구성 방안
- Supervised - QA set
- positive example : QA pair를 하나의 positive example 쌍으로 두기
https://huggingface.co/blog/1b-sentence-embeddings - negative example
in-batch Answer
- positive example : QA pair를 하나의 positive example 쌍으로 두기
<예시>
Anchor: "주어진 지문에서, yest = 1x + 2라는 선형 방정식을 사용한 익명의 실험에서 잔차 값은 어떻게 계산됩니까?"
Positive Example: "각 관측치에 대해 잔차는 예측된 yy 값과 관측된 yy 값을 비교하여 계산된다."
Negative Example: "대출 계산에서는 주어진 금액과 연간 이율을 사용하여 월 납부액을 계산한다."
- Unsupervised - QA set & Context
- positive example : Question / Answer / Context 문장에 dropout / paraphrasing / augmentation 등의 가공을 거쳐 이것을 positive example로 가정
- negative example : in-batch negative
<예시 1> - Question
Anchor: "AWS는 우주 역량을 확장하기 위해 어떤 기업들과 협력했습니까?"
Positive Example: "AWS가 우주 기술 개발을 위해 협력한 기업들에는 어떤 것이 있습니까?"
Negative Example: "Virgin Galactic Holdings, Inc.는 어떤 기술을 사용합니까?"
<예시 2> - Context
Anchor: "AWS는 올해 Capella Space와 Maxar Technologies Inc.(MAXR)와의 협력을 통해 우주 관련 역량을 확장해오고 있습니다. MAXR은 미국 국립해양대기청(NOAA)의 슈퍼컴퓨터보다 58% 빠른 기상 예보를 제공한다고 주장합니다. Capella의 지구 관측 솔루션은 AWS의 "컴퓨팅, 스토리지, 데이터베이스, 머신 러닝, 분석 서비스를 활용하여" 다양한 산업 및 애플리케이션에서 데이터를 처리합니다. 최근 우주 탐사 기술의 최신 물결은 주로 민간 기업이 주도하고 있지만, Virgin Galactic Holdings, Inc와 같은 몇몇 공공 기업도 새롭게 등장했습니다."
Positive Example: "AWS는 올해 Capella Space와 Maxar Technologies Inc.(MAXR)와의 협력을 통해 우주 관련 역량을 확장해오고 있습니다. MAXR은 미국 국립해양대기청의 슈퍼컴퓨터보다 58% 빠른 기상 예보를 제공한다고 주장합니다. Capella의 지구 관측 솔루션은 AWS의 컴퓨팅, 스토리지, 데이터베이스, 머신 러닝, 분석 서비스를 활용하여"다양한 산업 및 애플리케이션에서 데이터를 처리합니다. 최근 Virgin Galactic Holdings, Inc와 같은 몇몇 공공 기업도 새롭게 등장했습니다."
Negative Example (Another context) : "게임이 혼란에 빠지자, NLRB(전미노동관계위원회)는 당시 지방법원 판사였던 소니아 소토마요르에게 구 단체협약 조항을 팀 소유주들이 복원하도록 명령하는 금지명령을 발부하도록 설득했다. 전직 대통령 버락 오바마는 이 조치가 "야구를 구했다"고 언급한 바 있다. NLRB는 여전히 뉴스에서 자주 언급되고 있다. 2021년 11월, 이 기관은 알라바마의 아마존 물류창고 노동자들에게 첫 번째 선거에서 이커머스 거대 기업이 개입했다고 판단하고, 노조 결성을 위한 두 번째 기회를 부여했다. 이는 NLRB가 가진 막강한 권한을 보여주는 여러 사례 중 하나일 뿐이다. 그리고 2022년 12월 14일, NLRB의 로스앤젤레스 사무소는 서던캘리포니아 대학교 미식축구 및 농구팀을 대신해 부당노동행위를 주장하는 전미대학선수협회(NCPA)의 사건을 조사하기로 동의했다."
How to Build domain-specific Embedding model - (1) : 선행 연구 조사
도메인에 특화된 임베딩 모델을 만들기 위해서는 어떻게 데이터셋을 구축하고 학습을 진행해야 하는지, 선행 연구를 통하여 알아보도록 한다.도메인 특화 임베딩 모델 구축의 의미상용 도메인
ll2ll.tistory.com
Dataset Statistics
- tokenizer: Qwen/Qwen2.5-1.5B 기준
- unique text를 대상으로 집계
- Context
| subset | rows | total_tokens | mean_tokens | std_tokens |
| total | 196.5k | 24,674,818 | 125.53645 | 47.42068 |
- Question
| subset | rows | total_tokens | mean_tokens | std_tokens |
| total | 191.9k | 4,210,465 | 21.93327 | 6.85898 |
- Answer
| subset | rows | total_tokens | mean_tokens | std_tokens |
| total | 190.7k | 8,143,941 | 42.69364 | 27.32430 |
FinGPT
https://arxiv.org/abs/2306.06031
FinGPT: Open-Source Financial Large Language Models
Large language models (LLMs) have shown the potential of revolutionizing natural language processing tasks in diverse domains, sparking great interest in finance. Accessing high-quality financial data is the first challenge for financial LLMs (FinLLMs). Wh
arxiv.org
https://github.com/AI4Finance-Foundation/FinGPT
GitHub - AI4Finance-Foundation/FinGPT: FinGPT: Open-Source Financial Large Language Models! Revolutionize 🔥 We release th
FinGPT: Open-Source Financial Large Language Models! Revolutionize 🔥 We release the trained model on HuggingFace. - AI4Finance-Foundation/FinGPT
github.com
FinGPT (FinGPT)
FinGPT is deeply committed to fostering an open-source ecosystem dedicated to Financial Large Language Models (FinLLMs). FinGPT envisions democratizing access to both financial data and FinLLMs. It stands as an emblem of untapped potential within open fina
huggingface.co
- 평균적으로 토큰 수가 짧음
- QA pair 존재 X -> Unsupervised Learning에만 활용 가능
sentiment-train

https://huggingface.co/datasets/FinGPT/fingpt-sentiment-train
FinGPT/fingpt-sentiment-train · Datasets at Hugging Face
The Helsinki-based company , which also owns the Salomon , Atomic and Suunto brands , said net profit rose 15 percent in the three months through Dec. 31 to ( x20ac ) 47 million ( $ 61US million ) , from ( x20ac ) 40.8 million a year earlier .
huggingface.co
Dataset Statistics
| subset | rows | total_tokens | mean_tokens | std_tokens |
| total | 30.2k | 957,492 | 31.66833 | 19.27631 |
finred
https://huggingface.co/datasets/FinGPT/fingpt-finred
FinGPT/fingpt-finred · Datasets at Hugging Face
Given phrases that describe the relationship between two words/phrases as options, extract the word/phrase pair and the corresponding lexical relationship between them from the input text. The output format should be "relation1: word1, word2; relation2: wo
huggingface.co

Dataset Statistics
| subset | rows | total_tokens | mean_tokens | std_tokens |
| total | 5.7k | 284,909 | 49.98403 | 49.79135 |
finner
https://huggingface.co/datasets/FinGPT/fingpt-ner-cls
FinGPT/fingpt-ner-cls · Datasets at Hugging Face
This LOAN AND SECURITY AGREEMENT dated January 27 , 1999 , between SILICON VALLEY BANK (" Bank "), a California - chartered bank with its principal place of business at 3003 Tasman Drive , Santa Clara , California 95054 with a loan production office locate
huggingface.co

Dataset Statistics
| subset | rows | total_tokens | mean_tokens | std_tokens |
| total | 0.5k | 29,456 | 57.98425 | 55.09969 |
headline
https://huggingface.co/datasets/FinGPT/fingpt-headline
FinGPT/fingpt-headline · Datasets at Hugging Face
april gold holds slight gain, up $2.50, or 0.2%, at $1320.20/oz.
huggingface.co
Dataset Statistics
| subset | rows | total_tokens | mean_tokens | std_tokens |
| total | 8.7k | 126,280 | 14.35815 | 6.48421 |
헤드라인인 만큼 토큰 수가 많이 짧은 편
FNSPID
https://github.com/Zdong104/FNSPID_Financial_News_Dataset
GitHub - Zdong104/FNSPID_Financial_News_Dataset: FNSPID: A Comprehensive Financial News Dataset in Time Series
FNSPID: A Comprehensive Financial News Dataset in Time Series - Zdong104/FNSPID_Financial_News_Dataset
github.com
https://huggingface.co/datasets/Zihan1004/FNSPID
Zihan1004/FNSPID · Datasets at Hugging Face
The dataset generation failed Error code: DatasetGenerationError Exception: ArrowInvalid Message: Failed to parse string: 'Интернет и СМИ' as a scalar of type double Traceback: Traceback (most recent call last): File "/src/services/worker/.venv
huggingface.co
4개의 주식 시장 뉴스 웹사이트에서 수집한 1999년부터 2023년까지 4,775개 S&P500 기업의 2,970만 주가와 1,570만 개의 금융 뉴스 기록이 포함
- Stock News dataset 활용
- all_external.csv : English Article 존재하는 경우가 2006~2013년 밖에 없음 → 아래 nasdaq_exteral_data가 최신 버전인 듯
- nasdaq_exteral_data.csv : 2006 ~ 2024/01/09 까지의 데이터 존재
- 러시아어 등 다국어 데이터 섞여있으므로 언어 필터링 필요
Dataset Statistics (nasdaq_exteral_data)
| subset | rows | total_tokens | mean_tokens | std_tokens |
| total | 1630k | 723,629,644 | 443.84926 | 119.09121 |
- 2019 ~ 2024 (최근 5년)
| subset | rows | total_tokens | mean_tokens | std_tokens |
| total | 697.8k | 322,887,960 | 462.69095 | 101.94276 |
영문 데이터 개수에 따라서 연도 범위 확장할 수도 있음
'NLP > 프로젝트' 카테고리의 다른 글
| GPT Batch API 활용법 (1) - Batch request (0) | 2025.02.06 |
|---|---|
| 좋은 프로젝트란 무엇인가? - 기획편 (0) | 2025.01.16 |
| Azure Function - Mac setting (1) | 2024.12.09 |
| Azure Function - Windows setting (3) | 2024.12.09 |
| How to Build domain-specific Embedding model - (1) : 선행 연구 조사 (2) | 2024.12.04 |


