서로 다른 3D 상용 게임에서 자연어 지시를 수행하는 범용 AI 에이전트
Abstract
임의의 3D 환경에서 자연어 지시를 따라 행동할 수 있는 embodied AI system을 구축하는 것은 general AI를 만들기 위한 핵심 과제이다.
* embodied AI : 인공지능이 물리적 세계와 상호작용 할 수 있도록 통합하는 것을 의미함
https://www.nvidia.com/en-us/glossary/embodied-ai/
이를 달성하기 위해서는, 복잡한 작업에서 "언어"를 "인지(perception)"와 "행동(embodied actions)"에 연결하는 학습이 필요하다.
이번 SIMA 프로젝트에서는 연구용 환경부터 상업용 비디오 게임까지, 다양한 3D 가상환경에서 자유형(free-form) 언어 지시를 따르도록 에이전트를 훈련하는 방식으로 이 문제에 접근한다. 즉 인간이 할 수 있는 어떤 행동이든, 어떤 시뮬레이션된 3D 환경에서도 수행할 수 있는 ‘지시 가능(instructable)’ 에이전트를 개발하는 것이다.
SIMA 에이전트는 이미지 + 언어 지시문을 입력으로 받고, 키보드 & 마우스 행동을 출력으로 사용하는 인간과 유사한 인터페이스를 통해 실시간으로 환경과 상호작용한다.
이는 시각적으로 복잡하고 의미적으로 풍부한 다양한 환경에서 언어 기반의 다양한 지시를 수행 가능하게 하며, 새로운 환경에서도 손쉽게 실행될 수 있도록 한다.
1. Introduction
연구 목적
LLM의 뛰어난 능력에도 불구하고, 이를 구체화된 세계와 연결하는 것은 여전히 어려운 과제다.
AI는 이미 컴퓨터 프로그램을 작성할 정도로 언어적 측면에서 발전해있지만, 정작 인간에게 자연스러운 지각과 행동의 융합은 AI에게 매우 어려운 태스크로 남아있다.
하지만 언어는 세계에 대한 추상화를 제공할 수 있다는 점에서 강력한 도구이다. 이 언어를 풍부한 환경에 연결한다면, 언어 자체의 이해 또한 더욱 체계적이고 일반화될 수 있을 것이다.
따라서 다음과 같은 핵심 연구주제를 중심으로 삼았다.
- 언어의 기호(symbol)와 실제 세계의 대상(referent)을 어떻게 연결할 것인가?
- 언어가 주는 추상성과 일반성을 지각·행동과 연결하려면, 어떤 방식으로 해야 할까?
- 모든 과정을 안전하고 확장 가능한 방식으로 수행할 수 있을까?
기존 연구와의 차이점
더불어 어떤 가상환경에서도 인간의 방식으로 행동할 수 있는 에이전트를 만드는 것이 목표이기에, 특정 게임에 특화된 정책이 아닌 범용 환경에서 적용 가능한 에이전트를 만드는 것이 목표이다.
이전에도 특정 게임 & 시뮬레이션 환경에서 에이전트를 학습하는 연구는 많이 있었지만, SIMA는 다음과 같은 점에서 선행 연구를 뛰어 넘는다 볼 수 있다.
- 가능한 한 적은 가정 (범용적 환경 적응을 위함)
- 다양한 환경을 아우르는 적용 범위
- 인간과 유사한 인터페이스 사용
이를 위해 SIMA는 기존 연구와 대비해, 다음과 같이 더 어려운 설계를 선택했다.
- 복잡하고 오픈월드인 상업 게임들을 포함
- 환경이 비동기적(asynchronous)이며, 에이전트를 기다려주지 않음
- 게임 인스턴스 하나당 GPU 하나가 필요해 RL처럼 수천 개 병렬 실행 X
- 화면(UI)만 보고 행동, 내부 게임 상태나 보상 신호 없음
- 고수준 API 대신 실제 키보드·마우스 입력 그대로 사용
- 단순한 문법이 아닌 자연어 자유형 지시 사용
초기 성과
현재까지 SIMA는 언어 지시에 기반한 단기 작업 (약 10초 이내 수행 가능한 조작) 를 여러 환경에서 수행할 수 있다.
연구환경에서는 ground-truth 평가가 가능하지만, 상업용 게임은 임의 언어 지시의 성공 여부를 보고하지 않도록 설계되어 있기에
- OCR 기반 자동 평가
- 사람 평가
- 연구환경의 ground-truth
등을 조합하여 새로운 평가 체계를 개발했다.


2. Related works
3. Approach
SIMA의 핵심 요소는 아래 네 가지이며, 각각이 상호 보완적으로 작동한다.
- 환경(Environments)
- 데이터(Data)
- 에이전트 구조(Agent)
- 평가 방법(Evaluation)
3.1 Environments
SIMA의 목표는 다양한 3D 환경 전반에서 언어를 embodied actions와 연결하는 것이다. 이를 위해 다음 기준에 부합하는 환경들을 선택했다.
- 광범위한 개방형 상호작용을 제공하는 3D 구현 환경
- 1인칭 시점 & 플레이어 어깨 너머 시점의 3인칭 환경에 포커싱

3.1.1 Commercial
상업용 게임은 높은 시각적 다양성과 복잡한 상호작용을 제공한다.
특히 세계관과 스토리의 폭넓은 다양성을 추구하는, 독특한 매커니즘과 도전과제를 가진 (우주선 제작, 광물 수집 등..) 게임에 중점을 두었다. 평가 진행 시에는 게임 개발사들과 협력하여 게임을 보안이 적용된 Google Cloud 상에서 실행하고, 스트리밍된 게임 화면은 인간에게 보여지고 에이전트에게 전송되는 방식으로 인간 플레이와 에이전트 행동 평가를 수행하였다.
[사용된 게임 예시]
- Goat Simulator 3: 물리 기반 상호작용, 장난스러운 목표, 폭넓은 행동 가능성
- Hydroneer: 자원 채굴/조합, 설비 구축 등 높은 조작 난이도
- No Man’s Sky: 매우 다양한 행성·생태계·자원 구조 제공
- Satisfactory: 공장 자동화, 복잡한 생산 체계
- Teardown: 파괴 가능한 세계, 경로 계획 및 도구 사용
- Valheim: 생존, 제작, 탐험
- Wobbly Life: 물리 기반 미니 게임, 직업 수행
3.1.2 Research Environments
연구환경은 더 정교한 평가/제어가 가능하므로 ground-truth 평가가 가능했다.
[사용된 환경 예시]
- Construction Lab
- 블록 조립, 구조물 제작, 물리 기반 조작 등 “직접적인 물리 조작” 요구
- SIMA 팀이 새로 개발한 환경
- Playhouse
- 절차적으로 생성된 집 내부, 오브젝트 상호작용, 요리·그림 그리기 등
- 이전 DeepMind 연구 기반 확장판
- ProcTHOR
- 사무실·도서관·방 등 절차적 생성
- 사용은 주로 데이터 수집
- WorldLab
- 직관적인 물리 조작과 센서 기반 인터랙션을 강조
3.2 Data
SIMA의 학습은 대규모 behavioral cloning(행동 모방 학습)에 기반하므로 사람이 게임을 플레이하며 제공하는 데이터에서 관찰을 행동에 매핑하는 지도학습에 기반하여 에이전트를 훈련한다.
인간 플레이어로부터 나오는 게임 플레이 데이터는 여러 가지 종류가 있는데, 다음과 같다.
[데이터 구성 요소]
- 게임 화면(video frames)
- 언어 지시(instructions)
- 인간 조작 행동(keyboard + mouse)
- 성공/실패 및 설명과 같은 부가 주석
[데이터 수집 방식]
- 자유 플레이(free play)
- 한 명의 플레이어가 게임을 자유롭게 진행
- 이후 행동 궤적 (trajectory) 에 따라 언어 지시를 사후에 추가
- Setter–Solver 방식1
- 플레이어 2명이 협력
- A가 지시(Setter), B가 수행(Solver)
- A가 특정 시나리오에서 다른 플레이어에게 무엇을 할지 지시
- B의 시점 공유 (자유 플레이와 동일)
- 단일 시점 화면을 공유하여 데이터 일관성 확보
[데이터 전처리 / 필터링]
대규모로 데이터를 수집하는 것만으로는 성공적인 훈련을 보장할 수 없으므로, 전처리 / 필터링을 통해 데이터 품질 관리를 진행하여 언어 - 행동 사이 정확한 매핑을 진행하고자 하였다.
- 에이전트 입력에 맞게 프레임·해상도 조정
- 다양한 휴리스틱을 사용해 품질이 낮거나 불명확한 행동 제거 (필터링)
- 환경과 수집 방식 간의 데이터를 재구성(remixing)하고 가중치를 조정하여, 가장 효과적인 학습 경험을 우선순위로 두도록 구성
3.3 Agent
SIMA 에이전트는 시각적 관찰(이미지) + 지시 사항(텍스트) → 키보드/마우스 행동으로 매핑한다.
[Input] : 상태 표현
- 현재 화면 이미지
- 언어 지시
- 과거 상태 메모리(Transformer-XL 기반)
[Output]
- 키보드/마우스 8개 행동 시퀀스
태스크 자체가 입력 공간과 출력 공간의 높은 차원성, 그리고 장기간에 걸친 매우 다양한 지시의 폭 등으로 인해 매우 복잡하므로, 주로 10초 이내에 완료할 수 있는 지시를 수행하도록 에이전트를 훈련하는 데 중점을 두었다.
실제 범용 태스크에서 더 단순한 하위 태스크로 나누면, 적절한 지시 시퀀스가 주어졌을 때 서로 다른 설정이나 완전히 다른 환경에서도 이 하위 태스크들을 재사용할 수 있다.

모델 구성 요소
SIMA는 여러 종류의 pretrained-model을 조합하여 만들어졌다.
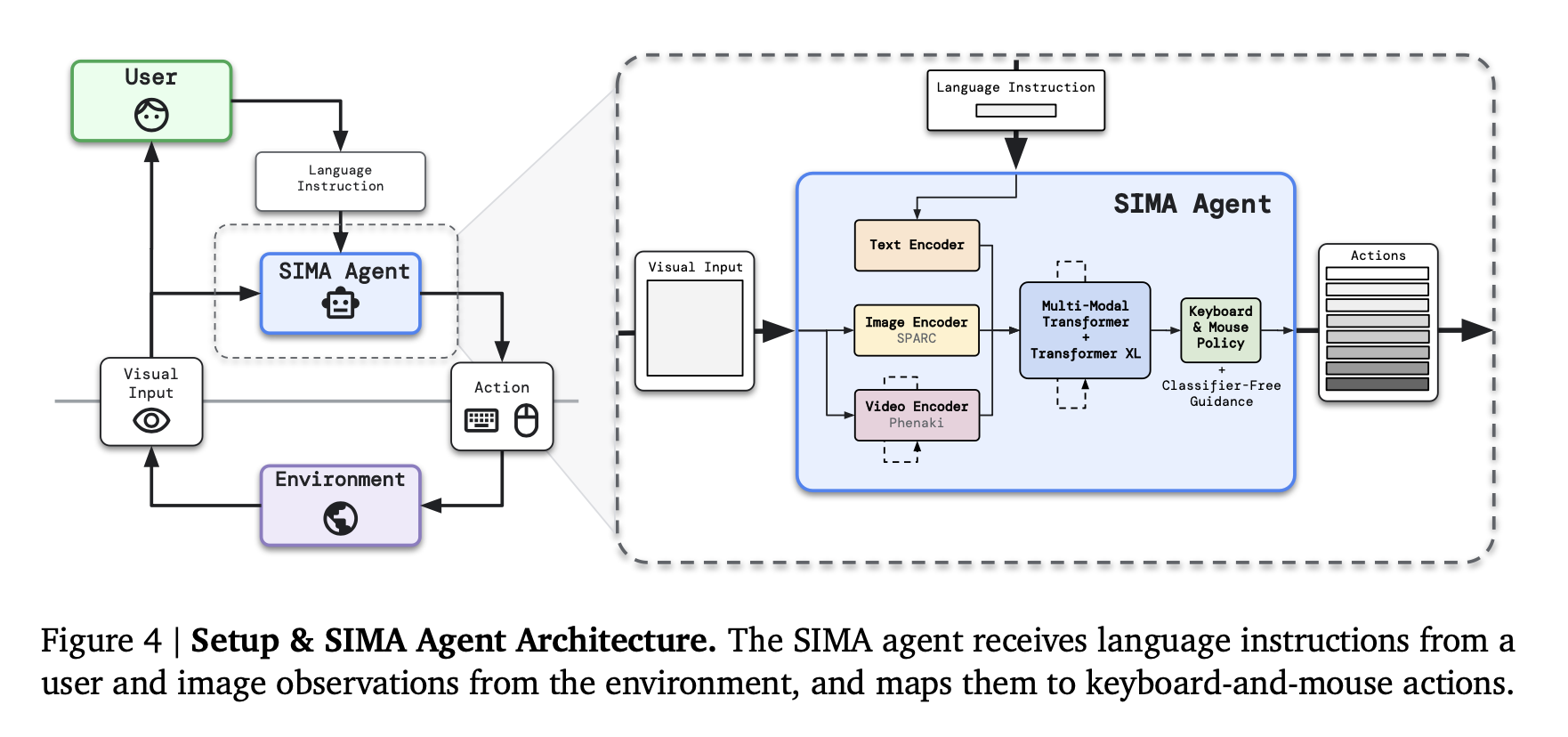
1. SPARC (fine-grained vision-language alignment model)
- 이미지와 텍스트의 정교한 대응 관계를 제공
- 화면 속 ‘작은 빨간 상자’ 같은 디테일을 문장과 정확히 연결함
- 자시문에 등장한 대상을 정확히 시각적으로 찾는 데 강함
- 정밀한 시각-언어 의미 처리에 도움
2. Phenaki (video prediction model)
- 시점 t의 프레임들을 보고 t+1 이후의 영상을 예측하는 모델
- “내가 여기서 앞으로 1초 걷으면 화면이 이렇게 변하겠네?"
- 환경의 물리적 변화·시간적 패턴 이해에 기여
3. Transformer 기반 멀티모달 통합기
- 일반 Transformer는 context 길이 고정
- Transformer-XL은 segment-aware recurrence 덕분에 장기 기억 유지가 가능
- SIMA에서는 “최근 몇 초 동안의 행동 + 관찰”을 기억하려고 사용됨
pre-trained model들을 데이터에 맞춰서 fine-tuning 했으며, 이 여러 모듈을 통합한 representation을 policy network (=행동을 결정하는 신경망, 실제 행동 생성기)가 받아 output behavior를 생성한다.
학습 방식
- 메인 학습: Behavioral Cloning (BC)
- 보조 학습: goal completion prediction(목표 달성 예측)
- Classifier-Free Guidance (CFG) : 추론 시 언어 조건성을 강화하기 위해 CFG를 적용
- 언어조건성 : 모델이 언어 지시를 얼마나 신경쓰는가
- 원래 diffusion에서 쓰이는 텍스트 조건 강화 기법
- “open the door”라고 시켰는데 모델이 문이 안 보인다거나 혼란스러우면 언어 조건성이 약하면 엉뚱한 행동을 해버림
- “언어 지시가 없는 행동 분포” 와 "언어 지시가 있는 행동 분포”의 차이를 강조해서 지시어의 영향력을 강제로 키움
- π_CFG = π(image, lang) + λ [π(image, lang) − π(image, null)]
- π(img, null) : 지시가 없었을 때 모델이 하려는 기본 행동 패턴
- λ를 키우면: 언어의 영향 ↑, 지시 무시하는 행동 ↓, 행동의 일관성 ↑
3.4 Evaluation
SIMA는 환경마다 평가 방식이 다르기 때문에, 여러 평가 방법을 조합한다.
연구용 환경에서는 자연어 지시에 따른 수행 여부를 "성공/실패"로 평가 자동화할 수 있지만, 상업용 게임에서는 자유로운 명령에 대해 성공 여부를 확실히 알려주지 않는다.
또한 행동이 진정으로 언어 조건부에 의한 것인지를 평가할 수 있어야 한다.
예를 들어 작업 환경에 칼, 도마, 당근이 있는 경우, 에이전트는 언어 지시에 의존하지 않고도 목표("도마 위의 당근을 잘라라")를 알아낼 수도 있다. 따라서 에이전트의 행동이 언어에 의해 주도되는지 올바르게 평가하려면, 단일 초기 상태에서 여러 지시를 테스트하는 등 다양한 행동이 가능한 작업 설정이 필요하다.
이에 따라 연구진은 효율성, 비용, 정확성, 커버리지 측면에서 서로 다른 장단점을 가진 다양한 평가 유형을 사용하여 평가를 진행했다.
1. Action log-probabilities (행동 로그 확률)
- 평가 데이터에 대한 행동 예측을 기반으로 에이전트 평가
- 하지만 에이전트의 행동 로그 확률이 가장 기본적인 기술을 제외하고는 에이전트의 성능과 약한 상관관계만 보임
- 실제 환경과 상호작용하는 온라인 평가가 필요
2. Static visual input (정적 시각 입력)
- 에이전트에게 정적 시각 입력과 언어 지시를 제공하여 특정 유효 행동(예: "점프")을 수행하는지 평가
- 특정 키보드 및/또는 마우스 동작에 직접 매핑되는 단순한 반응을 평가 가능
- 게임을 실제로 로딩할 핅요가 없어서 상업용 비디오 게임 환경에 해당 평가 방식 사용
- 빠르지만 장기 행동 평가에는 부적합
-> 1, 2번은 평가 방식에서 제외됨
3. Ground-truth 평가 (연구환경)
- 환경이 직접 “정답”을 제공 (연구 환경)
- 매우 정밀한 평가 가능
- 환경에 방해물 객체를 포함하여, 에이전트가 지시 대상 대신 방해물과 상호작용할 경우 나중에 실제 과제를 완료하더라도 즉시 실패로 표시되도록 함
- 에이전트에게 한 가지 목표를 완료하도록 지시한 다음, 다른 목표로 끼어들어 적절하게 전환하는지 평가하는 등의 평가 유형도 포함하여, 에이전트가 명령 변화에 충분히 반응하는지 확인
4. OCR 기반 평가 (상업용 게임)
- 많은 상업용 비디오 게임 환경은 과제나 퀘스트의 완료, 또는 자원 수집이나 특정 지역 진입과 같은 하위 수준 행동의 결과를 알리는 화면 텍스트를 제공
- 게임 화면의 텍스트 변화로 행동 성공 여부 판단 (e.g. “You collected wood”)
- 적은 비용으로 행동 평가 가능
- No Man’s Sky, Valheim에서 특히 활용했으나, 다른 비디오 게임들은 화면 텍스트가 훨씬 적기 때문에 OCR로 평가할 수 있는 행동의 범위가 매우 좁음
5. Human Evaluation (전문가 평가)
- 작업 성공 신호를 자동으로 도출할 수 없는 많은 경우 인간 평가에 의존
- 다중 평가자(보통 5명)
- 해당 게임을 최소 16시간 이상, 종종 몇 주에 걸쳐 플레이한 경험이 있는 게임 전문가들을 평가자로 활용
- 가장 일반적 평가방법이지만 가장 비용이 크고 느림
3.4.1 Latency mitigations
에이전트와 비동기적으로 실시간 실행되는 여러 환경에서 평가될 때, 행동 계산과 네트워크를 통한 관찰 및 행동 전송으로 인해 지연이 발생
- 훈련 시 에이전트의 시각 입력에 대해 시간적으로 오프셋(offset)된 행동을 예측 (=현재 화면보다 조금 미래 행동을 예측) 하도록 함
- 평가 시에는 TPU 가속기에서의 행동 계산 스케줄링, 타임스텝 간 신경망 상태의 온디바이스(on-device) 캐싱, 배치 크기 및 기타 구현 세부 사항의 신중한 선택을 통해 지연 시간을 최소화
4. Initial Results
- SIMA 에이전트의 능력에 대한 몇 가지 정성적 예시를 제시

- 환경 및 기술 범주별로 세분화된 SIMA 에이전트의 정량적 성능을 고려
- 평가 과제의 하위 집합을 조사하여 인간 수준의 성능을 추정
4.1. Performance across environments and skills
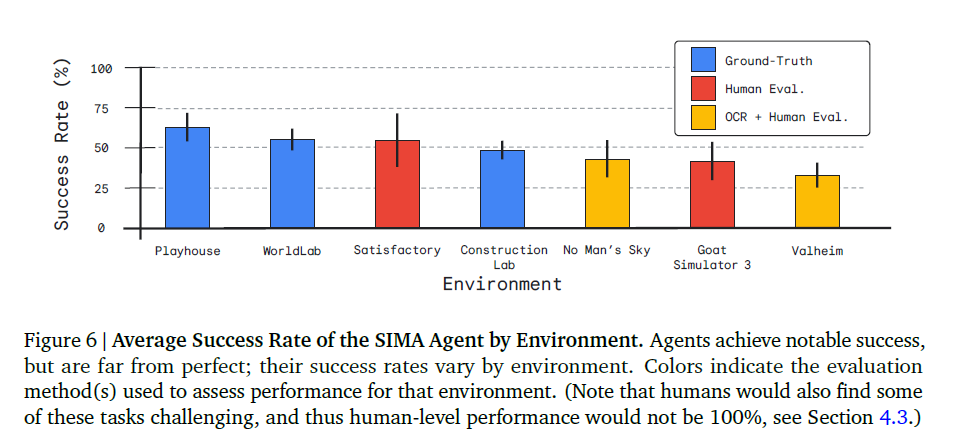
- 평균은 서로 다른 랜덤 시드를 사용한 3개의 AI 모델이 낸 점수를 모두 합쳐서 평균
- 연구용 환경에서는 여러번 시도 (단, 상업용 게임에서는 비용 이슈로 한번씩만)
- 오차 막대는 서로 다른 랜덤 시드를 사용한 3개의 95% 신뢰 구간(CI)을 나타냅니다.
전반적으로 결과는 SIMA 에이전트가 많은 환경에서 다양한 작업을 완료할 수 있음을 보여주지만, 여전히 상당한 개선의 여지가 있다.
- 파란색 (Ground-Truth): 게임 내부 코드로 정확히 채점 (연구용 환경)
- 노란색 (OCR + Human): 화면 글자 인식과 사람의 평가를 병행 (상업용 게임)
- 가능한 작업은 OCR로 자동 채점하고 나머지는 사람이 채점하여 결과를 종합
- 빨간색 (Human Eval): 사람의 평가에만 의존 (Satisfactory 게임)
- 비교적 단순한 연구 환경인 Playhouse와 WorldLab에서 성능이 가장 좋음
- Construction Lab은 연구용 환경임에도 성공률이 50% 미만으로 낮음
- 태스크들이 블록을 조립하거나 물리 법칙을 이용해야 하는 등 상대적으로 난이도가 높게 설계되었기 때문
- 더 복잡한 상업용 비디오 게임 환경의 경우, 성능이 다소 낮음

- Stop, Move 같은 단순한 이동 기술은 성공률이 높음
- Look은 쉬운 태스크처럼 보이지만 성공률이 낮음
- 단순히 시점을 돌리는 것 뿐만 아니라, No Man's Sky에서 행성을 바라보며 우주선을 조종하거나, 지형지물을 파악하는 복잡한 맥락이 포함되어 있기 때문
- Combat, Use tools, Build과 같이 정밀한 조작이나 공간에 대한 정확한 이해가 필요한 기술들은 성공률이 낮음
- 특히 Build의 경우 25% 미만의 낮은 성공률을 보이는데, 이는 정확한 위치에 물체를 배치해야 하는 어려움 때문이다
4.2. Evaluating environment generalization & ablations
다양한 베이스라인 / ablation 모델들과 비교
- SIMA
- Zero-shot : 주요 에이전트와 동일하게 훈련되었지만, 환경 중 N-1개에서만 훈련되고 테스트해보는 그 환경에서만 훈련이 안된 경우
- 에이전트의 transfer 능력을 평가
- No pretraining ablation : SIMA 에이전트에서 사전 훈련된 인코더를 제거
- No language ablation : 훈련 및 평가 중에 언어 입력이 없는 에이전트
- 에이전트의 성능이 단순히 언어와 무관한 행동적 사전 지식(behavioral priors)으로 어느 정도 설명될 수 있는지
- Environment-specialized : 각 환경에 대해 해당 환경의 데이터로만 훈련된 전문 에이전트
비교 에이전트의 수가 많기 때문에 해당 에이전트에서는 3개의 시드 대신 단일 시드만 테스트함

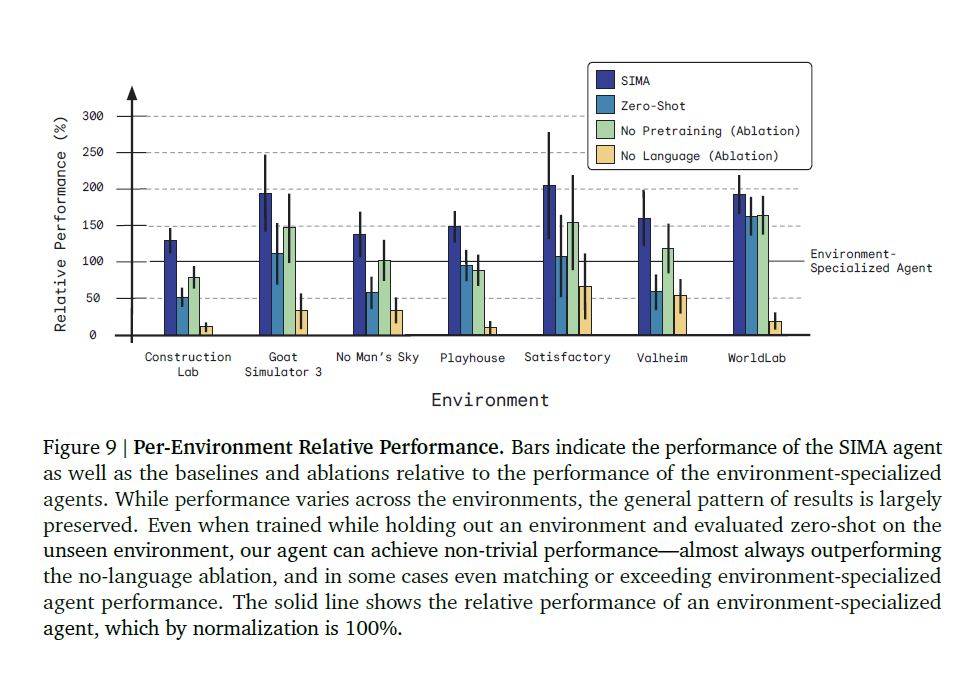
- 오차 막대 : 태스크 간의 점수 편차
- SIMA는 전체적으로 환경 전문 에이전트보다 성능이 뛰어남
- 환경 간에 긍정적인 전이 효과가 있음
- 언어가 없는 경우 매우 저조한 성능을 보여, 에이전트가 언어를 제대로 사용하고 있을 뿐만 아니라 태스크가 제대로 설계되었음을 입증
- 제로샷과 같은 경우에도 어느정도 준수한 성능을 보여주지만, 환경 특화 기술을 달성하는데는 부족
- 많은 게임에 나타나는 일반적인 탐색 기술은 수행 가능
- 환경 전문 에이전트는 게임별 상호작용을 잘 수행하지만 많은 게임에서 지원되는 공통 기술에서는 더 약한 모습을 보이는 반면, 제로샷 에이전트는 이러한 공통 기술을 실행할 수 있음
CFG Ablation study

- 연구 환경 (Construction Lab, Playhouse, WorldLab) 에서만 수행됨
- CFG가 없을 경우 에이전트의 성능이 눈에 띄게 저하됨
- 그러나 언어가 아예 없는것보다는 훨씬 좋은 성능 보임
4.3. Human comparison
No man's sky 게임에서 인간과 에이전트간의 성능 비교
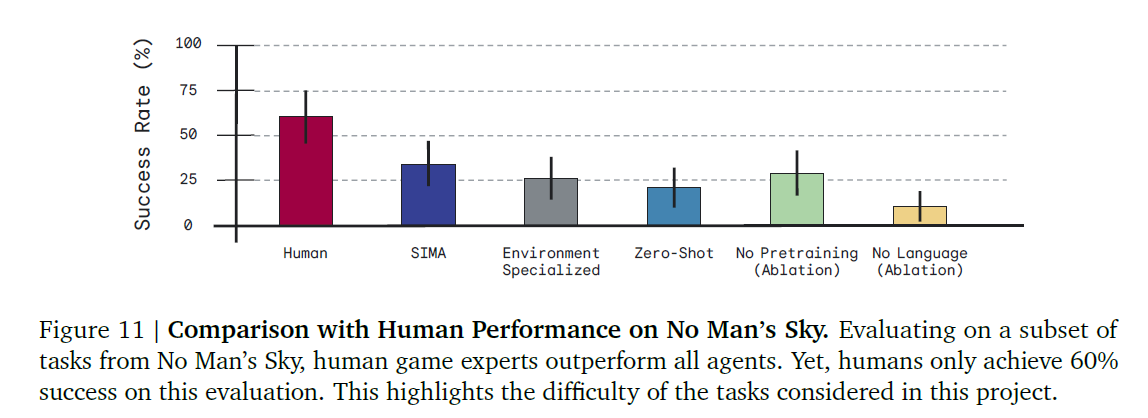
- 인간의 성능도 생각보다 낮은 것을 확인할 수 있음
- 태스크 난이도가 높다
- 과제를 완료하기 전에 불필요한 행동에 관여한 경우 실패 처리되었기 때문일수도
- e.g. "채굴 빔을 재충전하라"는 지시를 받았을 때 처음에 우주선 메뉴를 열고 상호작용하거나, "산소를 채굴하라"는 말을 듣고 스캔 후 분석 모드로 들어가는 것과 같은 경우
- SIMA 에이전트는 의미 있는 성능을 달성했으나, 아직 인간 성능에 도달하기 위해서는 상당한 진전이 필요하다
5. Looking ahead
SIMA는 현재 진행 중인 프로젝트이며, 눈에 띄는 초기 결과를 보여주었다.
환경 간 긍정적 transfer의 신호뿐만 아니라, zero-shot 에서의 성능도 확인할 수 있었다.
향후 연구에서는 다음을 목표로 한다.
- 게임, 환경 및 데이터셋 포트폴리오를 지속적으로 확장하여 더 많은 환경과 데이터셋으로 확장하는 것
- 에이전트의 robustness와 controllability를 높이는 것
- 점점 더 고품질이 되어가는 사전 훈련 모델들을 활용하는 것
- 더 포괄적이고 신중하게 통제된 평가를 개발하는 것
SIMA를 복잡한 환경에서 언어와 사전 훈련 모델을 안전하게 접목시키는 최첨단 연구를 수행하기 위한 이상적인 플랫폼으로 만들고, 이를 통해 AGI의 근본적인 과제를 해결하는 데 기여할 것이다.
(코드 공개가 안된 점이 아쉬움... )
SIMA 2
25년 11월 13일에 발표됨
SIMA 2: A Gemini-Powered AI Agent for 3D Virtual Worlds
Introducing SIMA 2, the next milestone in our research creating general and helpful AI agents. By integrating the advanced capabilities of our Gemini models, SIMA is evolving from an instruction-foll…
deepmind.google
- Gemini Flash-Lite 파운데이션 모델을 기반으로 만들어짐
SIMA 1과의 주요 차이점
단순 지시 이행에서 '대화형 파트너'로 진화
- SIMA 1: 단순한 언어 명령을 수행
- SIMA 2: 사용자와 대화가 가능하고, 높은 수준의 목표에 대해 추론할 수 있는 상호작용적 파트너(Interactive Partner)로 발전
- 에이전트가 내부적으로 추론(Reasoning) 과정을 거치고, 그 결과를 대화(Dialogue)로 출력 가능
- 사용자의 모호한 요청에 대해 되묻거나, 작업을 완료한 후 상황을 설명
입력 및 지시 이해 능력의 확장 (멀티모달)
- SIMA 1: 훈련 데이터에 있는 제한된 어휘의 텍스트 지시만 이해 가능
- SIMA 2: Gemini의 능력을 상속받아 복잡한 지시를 이해
- 멀티모달 프롬프트
- 텍스트뿐만 아니라 이미지(스케치, 다이어그램 등)를 입력받아 작업을 수행 가능
- 예를 들어, 나무 스케치를 보여주며 "이런 물체를 찾아라"고 하면 이를 이해하고 수행
- 복잡한 언어 이해: 다국어 지시를 이해하거나, 이모지(도끼+나무=나무 베기)를 해석하고, 복잡한 다단계 지시사항을 수행 가능
- 멀티모달 프롬프트
성능 및 일반화 능력의 비약적 향상
- 성능: 훈련된 환경에서의 평균 성공률이 SIMA 1 대비 약 2배 향상되었으며, 인간의 수행 능력에 훨씬 가까워짐
- 일반화 (Generalization): 훈련 과정에서 본 적 없는 새로운 게임(ASKA, Minecraft 등)에서도 훨씬 더 잘 적응함
- 심지어 비디오 게임이 아닌 Genie 3가 생성한 사실적인 환경에서도 작동함을 보여줌
자가 발전 (Self-Improvement) 기능 추가
- SIMA 2는 스스로 새로운 기술을 배우고 능력을 향상시킬 수 있는 구조
- Gemini 기반 시스템: 별도의 Gemini 모델들이 '과제 생성자(Task Setter)'와 '보상 모델(Reward Model)' 역할을 하여, 에이전트에게 끊임없이 새로운 목표를 주고 성공 여부를 채점
- 이를 통해 사람의 개입 없이도 새로운 환경에서 스스로 학습하며 발전 가능
보고, 듣고, 말하고, 스스로 생각하며 배우는 범용 AI 에이전트에 훨씬 더 가까워졌다.
참고 문헌
https://arxiv.org/abs/2404.10179
- Abramson et al., 2020; DeepMind Interactive Agents Team et al., 2021 [본문으로]
'NLP > 논문리뷰' 카테고리의 다른 글
| [논문 Review] 27. SIMA 2: A Generalist Embodied Agent forVirtual Worlds (0) | 2026.02.02 |
|---|---|
| [논문 Review] 26. Cultivating Game Sense for Yourself: Making VLMs Gaming Experts (1) | 2026.01.04 |
| [논문 Review] 24. ClueCart (0) | 2025.11.03 |
| [논문 Review] 23. Generative Agents (3) | 2025.04.10 |
| [논문 Review] 22. Evaluating Human-LM Interaction (1) | 2025.03.06 |

