네이버 부스트코스에서 제공하는 최성철 님의 강의를 참고하여 작성된 포스팅입니다.
Python Data handling
csv
- 탭 (tsv), 빈칸(ssv)로 구분도 가능
- 파이썬에서 처리할 때는 일반적인 textfile을 처리하듯이 파일을 읽어오고 한줄씩 데이터를 처리
# csv 객체
import csv
reader =csv.reader(f, delimiter=',',quotechar='"',quoting=csv.QUOTE_ALL)
- 그런데 pd.read_csv와 딱히 차이점은 없다.. 훨씬 간결하니까 pandas를 쓰자!
HTML(Hyper Text Markup Language)
- 웹 상의 정보를 구조적으로 표현하기 위한 언어
- 제목,단락,링크 등 요소 표시를 위해 Tag를 사용
- 모든 요소들은 꺾쇠 괄호 안에 둘러 쌓여 있음#제목 요소 ,값은 Hello,World
- 모든 HTML은 트리 모양의 포함관계를 가짐
- 일반적으로 웹 페이지의 HTML 소스파일은 컴퓨터가 다운로드 받은 후 웹 브라우저가 해석 / 표시
<!doctype html>
<html>
<head>
<title>Hello HTML</title>
</head>
<body>
<p>Hello World!</p>
</body>
</html>HTML도 일종의 프로그램,페이지 생성 규칙이 있음 → 추출된 데이터를 바탕으로 하여 다양한 분석이 가능
- HTML 분석 방법
- string
- regex : 정규 표현식
- beautifulsoup : 정적 웹사이트 크롤링
- selenium : 동적 웹사이트 크롤링
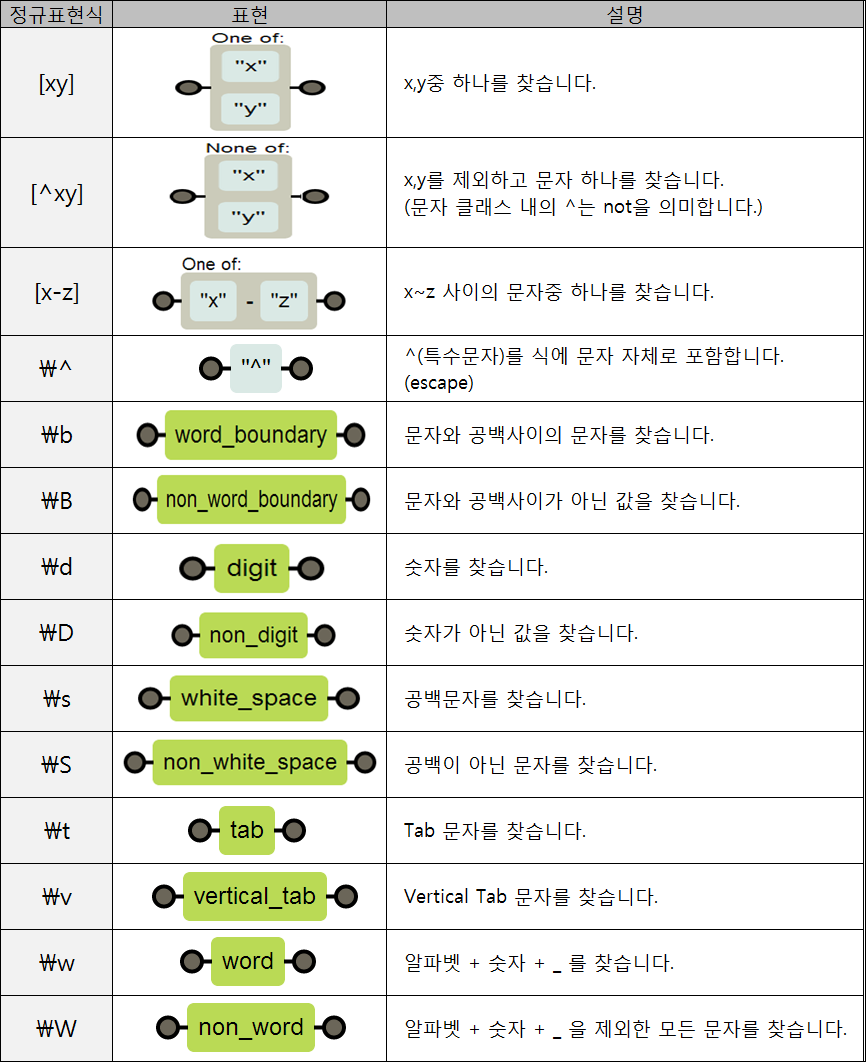
regex
복잡한 문자열 패턴을 정의하는 문자 표현 공식
| regex | 문자열 예시 |
|---|---|
| ^\d{3}-\d{4}-\d{4}$ | 010-0000-0000 |
| ^\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}$ | 203.252.101.40 |

- [정규식 연습장] (https://regexr.com/) : 정규 표현식 입력 시 설명 나옴
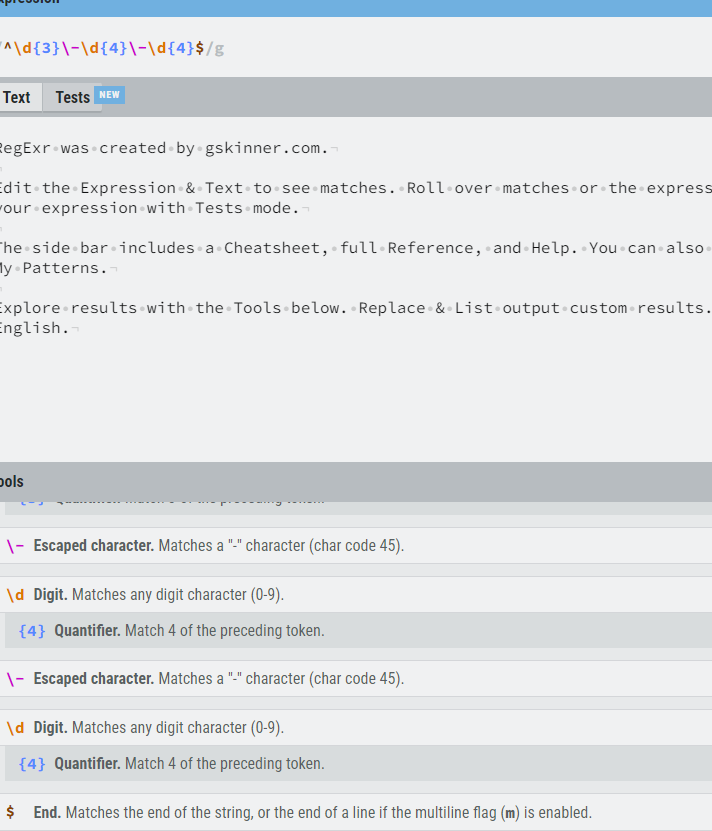
- 정규식 만들어주는 사이트
- 정규식 추출 방법
- http로 시작, zip으로 끝남. 그 사이에는 무엇이 있어도 상관 X
- 하이퍼링크들 추출됨
- ① 정규식 연습장(http://www.regexr.com/)으로%EC%9C%BC%EB%A1%9C) 이동
② 구글 USPTO Bulk Download (특허 데이터) 데이터페이지 소스 보기 클릭
③ 소스 전체 복사후 정규식 연습장 페이지에 붙여넣기
④ 상단 Expression 부분을 수정해가며 “Zip”로 끝나는 파일명만 추출
⑤ Expression에 (http)(.+)(zip)를 입력 - 정규식 추출 방법 (Python) : re 모듈 이용
- search() : 한 개만 찾기
- findall() : 전체 찾기추출된 패턴은 tuple로 반환됨
import re import urllib.request url ="https://bit.ly/3rxQFS4" html =urllib.request.urlopen(url) html_contents =str(html.read()) id_results =re.findall(r"([A-Za-z0-9]+\*\*\*)",html_contents) #findall 전체 찾기, 패턴대로 데이터 찾기 for result in id_results: print (result) url ="http://www.google.com/googlebooks/uspto-patents-grants-text.html" #url 값 입력 html =urllib.request.urlopen(url)#url 열기 html_contents =str(html.read().decode("utf8")) # utf8로 decode #html 파일 읽고,문자열로 변환 url_list =re.findall(r"(http)(.+)(zip)",html_contents) for url in url_list: print("".join(url))#출력된 Tuple 형태 데이터 str으로 join
XML
데이터의 구조와 의미를 설명하는 TAG(Markup) 를 사용해 표시하는 언어
- TAG - TAG 사이에 값이 표시
- 구조적 정보 표현 가능
- HTML과 문법이 비슷함
- 대표적 데이터 저장 방식
- 정보의 구조에 대한 정보인 스키마와 DTD등으로 정보에 대한 정보(메타정보)가 표현되며,용도에 따라 다양한 형태로 변경 가능
- XML은 컴퓨터(예:PC↔ 스마트폰)간에 정보를 주고받기 매우 유용한 저장 방식으로 쓰이고 있음
- XML도 HTML과 같이 구조적 markup 언어
- 정규표현식으로 Parsing이 가능하지만, 주로 beautifulsoup으로 파싱
- XML 문서 구조
- 원 : XmlNode 개체, DOM 트리의 기본 개체
- XmlDocument : XML을 메모리에 로드하거나 파일로 저장하는 것처럼 문서 전체에 수행되는 메서드를 지원
- XML 예제위 XML 데이터를 DOM 구조로 읽어오면 다음과 같이 메모리 구조화가 됨
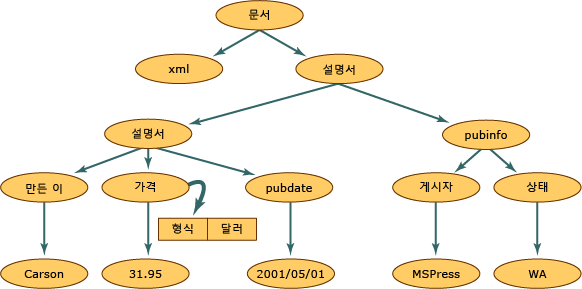
<?xml version="1.0"?> <books> <book> <author>Carson</author> <price format="dollar">31.95</price> <pubdate>05/01/2001</pubdate> </book> <pubinfo> <publisher>MSPress</publisher> <state>WA</state> </pubinfo> </books>- 출처 : https://learn.microsoft.com/ko-kr/dotnet/standard/data/xml/xml-document-object-model-dom?redirectedfrom=MSDN
<?xml version="1.0"?> <고양이> <이름>나비</이름> <품종>샴</품종> <나이>6</나이> <중성화>예</중성화> <발톱제거>아니요</발톱제거> <등록 번호>Izz138bod</등록 번호> <소유자>이강주</소유자> </고양이>
beautifulsoup
conda install -c anaconda beautifulsoup4
# 모듈 호출
from bs4 import BeautifulSoup
# 객체 생성
soup = BeautifulSoup(books_xml,"lxml")
# Tag 찾는 함수 find_all 생성
soup.find_all("author")
# 반환된 패턴의 값 반환 (태그와 태그 사이)
변수.get_text()2.6 사이트 정보 추출하기 - beautifulsoup 사용법 (1)
from bs4 import BeautifulSoup
with open("books.xml","r",encoding="utf8")as books_file:
books_xml =books_file.read()#File을 String으로 읽어오기
soup=BeautifulSoup(books_xml,"lxml")#lxml Parser를 사용해서 데이터 분석
#author가 들어간 모든 element 추출
for book_info in soup.find_all("author"):
print (book_info)
print (book_info.get_text())import urllib.request
from bs4 import BeautifulSoup
with open("US08621662-20140107.XML","r",encoding="utf8") as patent_xml:
xml =patent_xml.read()#File을 String으로 읽어오기
soup =BeautifulSoup(xml,"lxml")#lxml parser 호출
#invention-title tag 찾기
invention_title_tag =soup.find("invention-title")
print (invention_title_tag.get_text())JSON
JavaScript Object Notation
- javascript의 데이터 객체 표현 방식
- 간결, 데이터 용량이 적고 코드 전환이 쉬움
- XML의 대체제
- Python의 Dict Type과 유사, key:value 쌍으로 데이터 표시

- xml - json 비교
```xml
<?xml version="1.0"
encoding="UTF-8" ?>
<employees>
<name>Shyam</name>
<email>shyamjaiswal@gmail.com</e
mail></employees>
<employees>
<name>Bob</name>
<email>bob32@gmail.com</email>
</employees><employees>
<name>Jai</name>
<email>jai87@gmail.com</email>
</employees>
```
```json
{"employees":[
{"name":"Shyam"
,
"email":"shyamjaiswal@gmail.com"},
{"name":"Bob"
,
"email":"bob32@gmail.com"},
{"name":"Jai"
,
"email":"jai87@gmail.com"}]
}
```- in python
- json 모듈로 손쉽게 파싱, 저장 가능
- 데이터 저장 및 읽기는 dict type과 상호 호환
- 웹 API는 대부분 정보 교환 시 JSON 활용
- 대부분의 사이트에서 사용됨 → 각 사이트마다 Developer API의 활용법을 찾아 사용
- read
## json data ## {"employees":[ {"firstName":"John","lastName":"Doe"}, {"firstName":"Anna","lastName":"Smith"}, {"firstName":"Peter","lastName":"Jones"} ]} import json with open("json_example.json","r",encoding="utf8")as f: contents =f.read() json_data =json.loads(contents) print(json_data["employees"])
- write
import json
# dict type과 상호 호환
dict_data ={'Name':'Zara','Age':7,'Class':'First'}
with open("data.json","w") as f:
json.dump(dict_data,f)실습 : 트위터 데이터 가져오기
- Twitter에서 제공하는 Developer API를 사용하여 트위터 데이터 수집
- 수집되는 데이터 형태는 JSON형태로 제공함
- developer.twitter.com Oauth 인증으로 데이터를 주고 받을 수 있음
- 다양한 기능을 이해하기 위해 API문서의 공부가 필요
developer.twitter.com/en/docs
- 트위터 가입후 Twitter App 생성 (developer.twitter.com/en/apps)
- 트위터 App 정보 입력 (developer.twitter.com/en/apps)
- Keys와 AccessTokens로 가서 APIKey 값 확인
- conda 가상 환경으로 requests 와 oauthlib 설치
acitvate python_mooc conda install requests pip install requests-oauthlib- oauth 접속 권한 받기
import requests from requests_oauthlib import OAuth2 consumer_key = '확인한 consumer_key' consumer_secret = '확인한 consumer_secret' access_token = '확인한 access_token' access_token_secret = '확인한 access_token_secret' oauth =OAuth2(client_key=consumer_key,client_secret=consumer_secret, resource_owner_key=access_token,resource_owner_secret=access_token_secret)- 특정 계정의 타임라인 데이터 가져오기
#Twitter RESTapi //screen_name 은 트위터 계정명 url ='https://api.twitter.com/1.1/statuses/user_timeline.json?screen_name={0}'.format('naver_d2') r =requests.get(url=url,auth=oauth) statuses =r.json()
for status in statuses:
print(status['text'],status['created_at'])
```
'NLP > AI 이론' 카테고리의 다른 글
| [AI Math] 벡터와 행렬의 개념 (1) | 2024.01.28 |
|---|---|
| [Python] NumPy & Pandas (1) | 2024.01.28 |
| [Python] Python File/Exception/Log Handler (1) | 2024.01.28 |
| [Python] OOP + 파이썬 모듈화 (1) | 2024.01.28 |
| [Python] 파이썬이란? (1) | 2024.01.28 |



