네이버 부스트코스에서 제공하는 최성철 님의 강의를 참고하여 작성된 포스팅입니다.
운영체제 & 파일 시스템
관련 용어 정리
- 운영체제(OS) : 우리 프로그램이 동작할 수 있는 구동 환경

프로그램은 OS에 의존적이므로 OS에 맞춰서 개발되어야 한다.
- 파일 시스템 : OS에서 파일을 저장하는 트리구조 저장 체계, root 디렉토리부터 시작
- 디렉토리(=폴더) : 파일과 다른 디렉토리를 포함할 수 있음
- 파일 : 컴퓨터에서 정보를 저장하는 논리적 단위. 파일명과 확장자로 식별됨
- 절대 경로 VS 상대 경로
- 절대 경로 : 루트 디렉토리 ~ 파일 위치 (C:\user\docs)
- 상대 경로 : 현재 디렉토리 ~ 파일 위치 (....\filename)
- GUI : Grapical User Interface, 사용자가 알기 쉽게 그래픽으로 나타낸 것
- CLI : Command Line Interface, 텍스트로 컴퓨터에 명령을 내리는 방식
윈도우 vs 쉘 명령어

사실 윈도우 명령어까지는 굳이 알아둬야 하나 싶다 (그냥 WSL2 깔아서 쓰자..)
파이썬은?
플랫폼 독립적인 인터프리터 언어
- 플랫폼 독립적
- 인터프리터 언어
- 플랫폼 독립적 : OS = 플랫폼. 즉 OS에 상관없이 한번 프로그램을 작성하면 사용 가능함
- 파이썬은 인터프리터를 사용하기에 플랫폼 독립적 실행이 가능하다
- 컴파일러 vs 인터프리터 언어
- 컴파일러 : 소스코드를 기계어로 먼저 번역
- OS 의존적
- 실행속도 빠름
- 한번의 많은 기억 장소 필요
- C, Java, C#…
- 인터프리터 : 소스코드를 실행시점에 해석
- OS 독립적
- 실행속도 느림
- 메모리 적게 필요
- Python, scala..
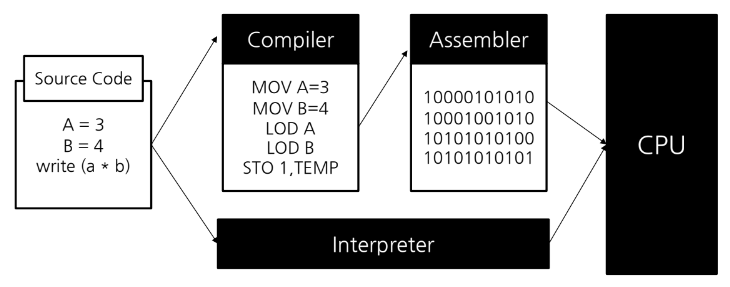
인터프리터 해석 과정
- 컴파일러 : 소스코드를 기계어로 먼저 번역
인터프리터 언어에서는 컴파일-어셈블 (기계어 변환과정) 이 하나의 과정처럼 보임
- 객체 지향 : 실행 순서가 아닌 모듈 중심의 프로그램 작성
- 모듈 : 행동 (method), 속성 (attribute)로 구성
- 절차 지향과 반대됨 (실행 순서 중심)
- 동적 타이핑 언어 : 프로그램이 실행되는 시점에 데이터 타입을 결정
- 후에 나올 타입 힌트는 제공될 수 있음
파이썬 기초 문법
변수
- 변수 : 값을 저장하는 장소
- 선언되는 순간 메모리 특정 영역에 물리적 공간이 할당됨
- 변수는 메모리 주소를 가지고, 변수에 들어가는 값은 그 메모리 주소에 할당된다.
- A = 8 : “A라는 이름을 가진 메모리 주소에 8을 저장”

리스트
리스트에 있는 값들은 주소 (offset) 을 가짐
- slicingcities[::2] : 2칸 단위
- cities[::-1] : 역으로 슬라이싱
- cities[-50:50] : 범위 넘어갈 경우 자동으로 최대범위 지정
- extend(list) : 리스트에 새로운 리스트 추가
- color.extend([”black”, “purple”])
- insert(index, value) : index 번째 주소에 값 추가
- color.insert(0, “orange”)
- remove(value) : list 중 처음으로 있는 value 요소 삭제
- color.remove(”white”)
- del(list[index]) : list의 index번째 요소 삭제
패킹, 언패킹
- 패킹 : 한 변수에 여러 개 데이터 넣기
- 언패킹 : 한 변수 데이터를 각각의 변수로 반환
copy() vs deepcopy()
- 얕은 복사
- 변수 대입, copy.copy()
- 원본 객체의 값을 변경하면 복사본도 변경됨
- 깊은 복사
- copy.deepcopy()
- 원본 객체의 값을 변경해도 복사본은 변경 X
- 내부 객체들까지 모두 복사되기 때문
함수
- 코드를 논리적인 단위로 분리
- 캡슐화 : 인터페이스만 알면 타인의 코드 사용 가능
- parameter : 함수의 입력 값 인터페이스
- argument : 실제 파라미터에 대입된 값
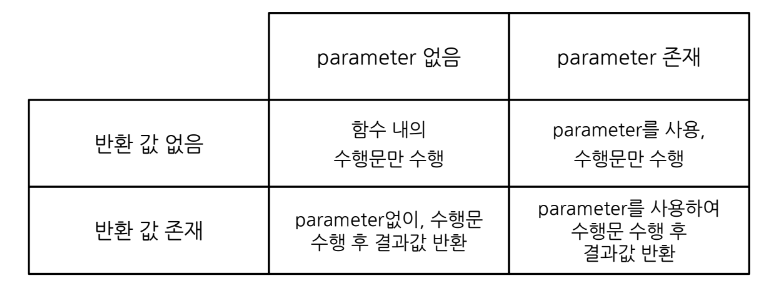
프린트 포맷팅
- % string
- print(’%s’ %(’one’))
- format
- 인덱스 형태 : print("My name is {0} and {1} years old.".format(name,age))
- 변수명 형태 : print("Product:{name:>10s},Price per unit: {price:10.5f}.".format(name="Apple", price=5.243))
- print(’{}’.format(’one’))
- f-string : 최근 가장 많이 쓰임
- name = "Sungchul"
age = 39
print(f"Hello, {name}. You are {age}.")
- name = "Sungchul"
- padding
- print("Product:%5s, Price per unit: %.5f." % ("Apple", 5.243))
print("Product: {0:>5s}, Price per unit: {1:10.3f}.".format("Apple", 5.243))
- print("Product:%5s, Price per unit: %.5f." % ("Apple", 5.243))
조건문
명령문이 한줄이면 붙여쓰기 가능하다
if score>=90 : grade='A'
elif score>=60: grade='D'
else: grade='F'삼항 연산자
value = 12
is_even = True if value % 2 == 0 else False반복문
- 왜 range는 0부터 시작할까?
- 일종의 관례인데 2진수가 0부터 시작하기 때문에 0부터 시작하는 걸 권장한다고 한다!
문자열
- 영문자 1글자 = 1byte
- 그럼 한글은 어떨까?
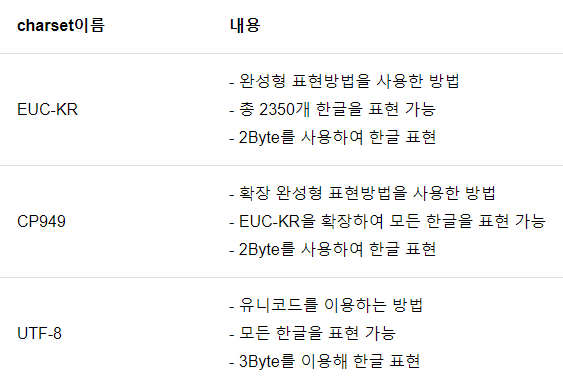
- 한 글자씩 메모리 공간이 할당됨

- 컴퓨터는 문자를 직접적으로 인식하지 못하고, 2진수로 인식함
→ 2진수를 문자로 변환하는 표준 규칙 (ex. UTF-8) - 문자열 오프셋
왼쪽에선 0부터, 오른쪽에선 -1부터 시작
문자열 함수
헷갈리거나 생소한 것들만 따로 정리해보자!
Python String Methods
| 함수명 | 기능 |
|---|---|
| a.capitalize() | 첫 문자를 대문자로 변환 |
| a.title() | 띄어쓰기 후 첫 글자만 대문자 |
| a.count(’abc’) | 문자열 a에 ‘abc’가 들어간 횟수 |
| a.find(’abc’) | 문자열 a에 ‘abc’가 들어간 위치 (왼쪽부터 탐색) |
| a.rfind(’abc’) | 문자열 a에 ‘abc’가 들어간 위치 (오른쪽부터 탐색) |
| a.startswith('abc') | 문자열 a는 ‘abc’로 시작하는가? |
| a.endswith('abc') | 문자열 a는 'abc'로 끝나는가? |
| a.isdigit() | 문자열이 숫자인지 |
| a.islower() | 문자열이 소문자인지 |
| a.isupper() | 문자열이 대문자인지 |
함수에서 파라미터를 전달하는 방식
- 값에 의한 호출 (Call by Value)
- 함수에 인자를 넘길 때 값만 넘김
- 함수 내에서 인자 값 변경해도 호출자에 영향 X
- 참조에 의한 호출 (Call by Reference)
- 함수에 인자를 넘길 때 메모리 주소를 넘김
- 함수 내에 인자 값 변경 시, 호출자의 값도 변경됨
- 객체 참조에 의한 호출 (Call by Object Reference)
- 파이썬 함수는 객체의 주소가 함수로 전달되는 방식
- 전달된 객체를 참조하여 변경 시 호출자에게 영향을 주나, 새로운 객체를 만들 경우 호출자에게 영향을 주지 않음
def swap_value (x, y):
temp = x
x = y
y = temp변수가 가리키는 메모리 주소만 변경되고, 함수 밖에서 호출자가 변경되지 않음
def swap_offset (offset_x, offset_y):
temp = a[offset_x]
a[offset_x] = a[offset_y]
a[offset_y] = tempa 리스트의 전역 변수 값을 직접 변경함 → 값이 변경됨
가장 권장되는 방식
객체 자체를 함수에 호출, 객체가 그대로 유지되고 값도 변경됨
def swap_reference (list, offset_x, offset_y):
temp = list[offset_x]
list[offset_x] = list[offset_y]
list[offset_y] = tempa 리스트 객체의 주소 값을 받아 값을 변경 → 값이 변경됨
지역 변수 VS 전역 변수
- 지역 변수 : 함수 내에서만 사용
- 전역 변수 : 프로그램 전체에서 사용
- 함수 내에 전역 변수와 같은 이름의 변수 선언 시 새로운 지역 변수 생성
- 함수 내에서 전역 변수 사용하려면 global 키워드 사용
type hints
파이썬의 가장 큰 특징은 동적 타이핑이지만, 다른 사용자가 인터페이스를 알기 어려움
- 사용자에게 인터페이스를 명확히 알려줄 수 있음
- 함수 문서화 시 파라미터에 대한 정보를 명확히 알 수 있음
- mypy, IDE, linter를 통해 코드의 발생 가능한 오류 사전에 확인
- linter : 소스 코드 분석해 버그, 스타일 오류 등을 표시해주는 도구들
https://sanggi-jayg.tistory.com/entry/Python-Linter-비교- mypy : Mypy는 파이썬에서 가장 많이 사용되고 있는 정적 타입 검사 도구
no: int = "1" print(no) ## 인터프리터 실행 ## python test.py 1 ## mypy 실행 ## mypy test.py test.py:1: error: Incompatible types in assignment (expression has type "str", variable has type "int") Found 1 error in 1 file (checked 1 source file)pip install mypy mypy new_file.py
- flake8, black
pep8 like 수준을 준수하는지 확인- flake8 : 어느 라인이 잘못됐는지 출력
conda install -c anaconda flake8 ##### flake8_test.py:2:12: E203 whitespace before ':' flake8_test.py:3:10: E211 whitespace before '('- black : 자동으로 수정까지!
conda install black black function.py
- linter : 소스 코드 분석해 버그, 스타일 오류 등을 표시해주는 도구들
- type hint 예시
def do_function(var_name : var_type) -> return_type: pass # name은 str 자료형, 반환값은 str def type_hint_example(name: str) -> str: return f"Hello,{name}" # index는 int 자료형, 반환값은 없음 def insert(self, index: int, module: Module) -> None: r"""Insert a given module before a given index in the list. Args: index (int): index to insert. module (nn.Module): module to insert """ for i in range(len(self._modules), index, -1): self._modules[str(i)] = self._modules[str(i - 1)] self._modules[str(index)] = module- docstring : 파이썬 함수에 대한 상세 스펙
- 함수 기능만 설명
def multiplier(a, b): """Takes in two numbers, returns their product.""" return a*b- 파라미터, 반환 값까지 설명
def add_binary(a, b): ''' Returns the sum of two decimal numbers in binary digits. Parameters: a (int): A decimal integer b (int): Another decimal integer Returns: binary_sum (str): Binary string of the sum of a and b ''' binary_sum = bin(a+b)[2:] return binary_sum
- Python Docstrings (With Examples)
함수 개발 가이드라인
좋은 함수에 대한 고민은 협업을 위해 꼭 필요하다!
- 함수는 가능하면 짧게!
- 함수 이름에는 함수 역할, 의도를 명확하게
- 하나의 함수에는 유사한 역할 하는 코드만
- 인자로 받은 값 자체를 바꾸지 말고 임시변수로 선언
- 코딩 컨벤션
- 코드 마지막에는 항상 한 줄 추가
- 함수명은 소문자와 언더바로 구성
- huggingface transformer 라이브러리 내 모델 구현 코드들을 살펴보면 많은도움이 된다고 한다!
https://huggingface.co/docs/transformers/index
🤗 Transformers
Efficient training techniques
huggingface.co
자료 구조
스택 (LIFO)
- 후입선출
- push, pop
[스택 포스팅] (https://ll2ll.tistory.com/9)
큐 (FIFO)
- 선입선출
- put, get
[큐 포스팅] (https://ll2ll.tistory.com/10)
튜플
- 값의 변경이 불가능한 리스트
- 리스트의 연산, 인덱싱, 슬라이싱 등 동일하게 사용 가능
- 변경되지 않아야 할 데이터를 저장 → 사용자 실수에 의한 에러를 방지
set
- 값을 순서 없이 저장
- 중복 X, 모두 unique value
- 집합 연산
- s1.union(s2), s1|s2 : s1, s2의 합집합
- s1.intersection(s2), s1&s2 : s1, s2 교집합
- s1.difference(s2), s1-s2 : s1, s2 차집합
dict
- {key : value, key : value, …}
OrderedDict
데이터를 입력한 순서대로 dict 반환 (그냥 dict도 파이썬 3.6부터 입력 순서 보장)
defaultdict
dict type 값에 기본값 지정, 신규값 생성 시 default value가 들어감
from collections import defaultdict
d = defaultdict(lambda:0)
print(d['first']) # 0deque
- stack, queue 지원
- 리스트에 비해 효율적이고 빠름
- Linked list의 특성 지원 (rotate, reverse)
counter
- sequence type의 element 개수를 dict로 반환

- dict type, keyword parameter도 처리 가능

- set 연산 지원
namedtuple
tuple 형태로 데이터 구조체 저장
from collections import namedtuple
Point = namedtuple('Point', ['x', 'y'])
p = Point(11, y=22)
print(p[0] + p[1])namedtuple 사용법에 대해서는 아래 포스팅을 참고하면 좋다!
Python Namedtuple Example 및 사용법
Pythonic Code
어떤 것이 ‘파이썬다운’ 코드인가?
split
string을 기준값으로 나눠 list로 반환
join
string으로 구성된 list를 합쳐 하나의 string으로 반환
list comprehension
- 기존 list를 사용해 다른 list를 만드는 방법
- for + append보다 속도가 빠름
enumerate, zip
- enumerate : list element 추출 시 번호 붙여서 추출
- zip : 두 개 리스트 값을 병렬 추출
lambda
- 코드 해석 어려움
- 이름이 존재하지 않는 함수 (익명 함수)
→ 최근에는 사용을 권장하지 않음.. 하지만 많이 쓴다!
map function

출처 : https://tykimos.github.io/2020/01/01/Python_Lambda_Map/
- map을 사용하면 iterable 객체를 순회하며 각 입력마다 해당 함수 적용함
- 메모리 효율적
- 조건문 적용
list( map( lambda x:x ** 2 if x % 2 == 0 else x, ex) )
reduce function
map과는 달리 통합하는 과정까지 포함
from functools import reduce
print(reduce(lambda x, y : x+y, [1,2,3,4,5]))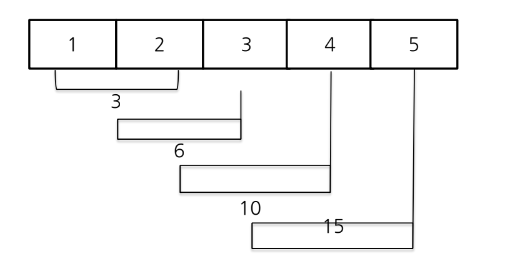
generator
- iterable 객체를 특수한 형태로 사용하는 함수
- 여러 개의 데이터를 미리 만들어놓지 않고 필요할 때마다 즉석에서 하나씩 만들어낼 수 있는 객체
- next() 를 통해 차례로 값에 접근할 때마다 메모리에 적재
def geneartor_list(value):
result = []
for i in range(value):
yield i→ yield를 사용해 한 번에 하나의 element 반환 가능
def return_abc():
return list("ABC") # 리스트 반환
def yield_abc():
yield "A"
yield "B"
yield "C" # generator 반환return키워드를 사용할 때는 결과값을 딱 한 번만 제공하는데,yield키워드는 결과값을 여러 번 나누어서 제공- return은 모든 결과값을 메모리에 올려야 함 / yield는 결과 값을 하나씩 메모리에 올림
- yield는 대용량 파일을 읽거나, 스트림 데이터를 처리할 때 사용
- list 또한 generator처럼 쓸 수 있다
def yield_abc(): yield from ["A", "B", "C"]
generator comprehension
yield 이외에 generator를 만드는 또 다른 방법
list comprehension과 비슷하다
gen_ex = (n*n for n in range(500))
print(type(gen_ex))abc = (ch for ch in "ABC")
print(abc)
for ch in abc:
print(ch)
#############
<generator object <genexpr> at 0x7f2dab21ff90>
A
B
C- 이걸 왜 써야 하지?
- 리스트(iterator) 보다 훨씬 작은 크기이기 때문에 메모리 효율적
-
from sys import getsizeof gen_ex = (n*n for n in range(500)) list_ex = [n*n for n in range(500)] print(getsizeof(gen_ex), getsizeof(list_ex)) - 중간 과정에서 루프 중단 우려 있는 경우
- 큰 데이터, 스트림 데이터 처리
미리 모든 값을 계산하지 않고 필요할 때마다 값을 그때그때 계산하기 때문에 수행 시간이 긴 연산을 필요한 순간까지 늦출 수 있고 메모리를 절약할 수 있다.
function arguments
- keyword arguments
- 함수에 입력되는 파라미터 변수명 사용
- default arguments
- 파라미터 기본 값 사용, 입력 X 시 기본값
- variable-length arguments
- 개수가 정해지지 않은 변수를 함수 파라미터로 사용
- asterisk(*) 기호 사용
- 위치 가변 인자 (*args)
- 가변인자는 일반적으로 *args를 변수명으로 사용
- 오직 1개만 사용 가능 -> *args1, *args2 이런 식으로는 사용이 불가!
- 기존 파라미터 이후 값을 튜플로 저장
def print_somthing(my_name, your_name): print("Hello {0}, My name is {1}".format(your_name, my_name)) def print_somthing_2(my_name, your_name="TEAMLAB"): print("Hello {0}, My name is {1}".format(your_name, my_name)) def asterisk_test(a, b, *args): return a+b+sum(args) print(asterisk_test(1, 2, 3, 4, 5)) # 15
- 키워드 가변인자(**kwargs)
- 파라미터 이름을 따로 지정하지 않고 입력
- asterisk 2개 사용 (**)
- 입력된 값은 dict type 으로 사용 가능
- 가변인자는 오직 한 개만 기존 가변인자 다음에 사용
def f(x, y, **kwargs): # x -> 2 # y -> 3 # kwargs -> { 'flag': True, 'mode': 'fast', 'header': 'debug' }
- 위치 가변 인자 (*args)
- 두 가지 혼합
f(2, 3, flag=True, mode='fast', header='debug') def f(*args, **kwargs): # args = (2, 3) # kwargs -> { 'flag': True, 'mode': 'fast', 'header': 'debug' } ...
asterisk - unpacking
def asterisk_test(a,*args):
print(a,args)
print(type(args))
asterisk_test(1,*(2,3,4,5,6)) # 1 (2,3,4,5,6)def asterisk_test(a,args):
print(a,*args)
print(type(args))
asterisk_test(1,(2,3,4,5,6)) # 1 2 3 4 5 6'NLP > AI 이론' 카테고리의 다른 글
| [AI Math] 벡터와 행렬의 개념 (1) | 2024.01.28 |
|---|---|
| [Python] NumPy & Pandas (1) | 2024.01.28 |
| [Python] Python Data Handling (1) | 2024.01.28 |
| [Python] Python File/Exception/Log Handler (2) | 2024.01.28 |
| [Python] OOP + 파이썬 모듈화 (1) | 2024.01.28 |



