포스팅을 시작하기 전에
코드량이 늘어나면서 포스팅 시간이 늘어나고 있다 ㅜ.. 최대한 빨리 마쳐야지
키워드
#리스트구현 #그룹화 #공유 #원형연결리스트
1. 리스트 확장
grouping & sharing
그룹화 (grouping)
위에서는 모든 데이터원소들이 한 그룹에 속해있는 경우만 살펴봤다. (한 학생의 한 학기 과목 성적이라던지)
그렇다면 각 원소들이 다른 그룹에 속해있다면, 어떻게 구현해야 할까?
원래의 연결리스트 상태로 구현해도 괜찮을까?
헷갈리니까 예시를 들어보자.
- 대학의 강좌들
- Prof. A : DS
- Prof. B : CS, DB
- Prof. C : none
- 다항식의 항들
- Exp 1 : 3x^4
- Exp 2 : 5x^3, -4
이렇듯 데이터가 다른 그룹에 속해있고, 그걸 구별해줘야하는 상황이라면 위에서 설명했던 구현 방법만으로는 리스트 구현이 힘들 것 같다는 생각이 든다.
위에서 배웠던 리스트의 개념을 다시 한 번 떠올려보자.
리스트는 임의 개체 (데이터)를 연속적으로 저장하고, 중복된 데이터의 저장을 막지 않는다.
그룹별로 리스트 형태에 저장하기를 바라니까, 하나의 리스트에 임의 개체를 연속적으로 저장할 수는 없을 것 같다.
여기서 나오는 개념이 바로 그룹화 (Grouping) 이다.
설계 방안
1. 원소와 그룹 필드로 구성된 리스트 사용
"그룹" 을 표현하기 위해 원소 및 그룹 필드로 구성된 리스트를 사용한다.
구현은 간단하지만, 특정 그룹에 관한 작업을 위해 전체 레코드를 순회해야 한다는 단점이 존재한다.

- 구현 방법 A. 리스트 이용
elem, group 필드로 구성된 노드로 구성된 연결리스트 사용
<구현 ADT & 의사코드>
- void initGroup()
- 연결리스트 헤더, 트레일러 할당 및 초기화
Alg initGroup()
// input : None
// output : an empty doubly linked list with header H and trailer T
H <- getnode()
T <- getnode()
H.next <- T
T.prev <- H
n <- 0
return
- void traverseGroup(g)
- 지정된 그룹의 모든 멤버들을 출력
Alg traverseGroup(g)
// input : a doubly linked list with header H and trailer T, group g
// output : none
p <- H.next
while (p != T)
if (p.group = g)
print(p.elem)
p = p.next
return
- void removeGroup(g)
- 지정된 그룹의 모든 멤버 삭제
Alg removeGroup(g)
// input : a doubly linked list with header H and trailer T, group g
// output : none
p <- H.next
while (p!=T)
// 연결리스트 끊어지지 않게 next 백업해두기 (중요!!!)
pnext <- p.next
if (p.group = g)
removeNode(p)
n -= 1
// 노드 삭제 이후 next 복구
p = pnext
return
<파이썬 구현>
여기서 일반 메서드 (size, isEmpty...) 는 이전 포스팅에서 구현했기에 생략하도록 하겠다.
이전 포스팅 참고 : https://ll2ll.tistory.com/6
[자료구조] 04(1). 연결리스트 구현
포스팅을 시작하기 전에 그림이 들어가면 이해가 더 쉬울것같다는 피드백을 받아서 저번 포스팅에서는 그림을 좀 더 열심히 넣어봤다!! 근데 매번 패드로 그리고 옮기기 조금..조금 귀찮긴 하다
ll2ll.tistory.com
# grouping_linked_list_A.py
from asyncio.windows_events import NULL
class node():
def __init__(self, e, g, prev=None, next=None):
self.elem = e
self.group = g
self.prev = prev
self.next = next
class grouping_linked_list():
# 동적 할당 받으면 되니까 처음부터 공간 얼마 필요한지 필요 X
def __init__(self):
self.head = node(NULL, NULL)
self.tail = node(NULL, NULL)
# tail prev에 head 할당
self.head.next = self.tail
self.tail.prev = self.head
self.n = 0
def add(self, r, e, g):
if r<0:
print("invalidRankException")
else:
p = self.head.next
for i in range(0, r):
p = p.next
# i -1 에 값 존재할 경우 -> 값 갱신
if p.elem != NULL:
p.elem = e
p.group = g
else:
# 존재하지 않을 경우 새 노드 할당
q = node(e, g, p.prev, p)
(p.prev).next = q
p.prev = q
self.n += 1
return
def traverseGroup(self, g):
p = self.head.next
while p != self.tail:
if p.group == g:
print('Group :', g, 'Element :', p.elem)
p = p.next
return
def removeGroup(self, g):
p = self.head.next
while p != self.tail:
pnext = p.next
if p.group == g:
(p.prev).next = p.next
(p.next).prev = p.prev
self.n -= 1
p = pnext
return
from grouping_linked_list_A import grouping_linked_list
new_array = grouping_linked_list()
new_array.add(0, 'z1', 'Z')
new_array.add(1, 'x1', 'X')
new_array.add(2, 'z2', 'Z')
new_array.add(3, 'y1', 'Y')
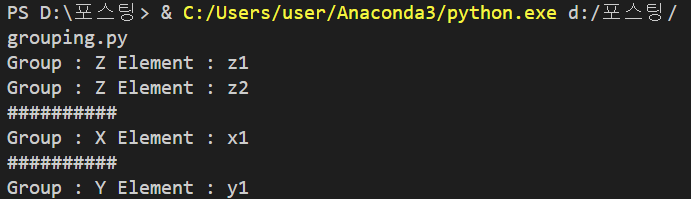
new_array.traverseGroup('Z')
print('#' * 10)
new_array.removeGroup('Z')
new_array.traverseGroup('X')
print('#' * 10)
new_array.traverseGroup('Y')
<실행 결과>
- 구현 방법 B. 1D 배열 이용
elem, group 필드로 구성된 레코드의 배열 이용해 구현
구현 방법 A보다 구현이 복잡하지만 기억장소 낭비가 없다는 장점이 존재한다.

<구현 ADT & 의사코드>
- void initGroup()
- 배열 할당하고 초기화
Alg initGroup()
// input : array V, integer N, integer n
// output : an empty array V of size n
n = 0
return
- void traverseGroup(g)
- 지정된 그룹의 모든 멤버들을 출력
Alg traverseGroup(g)
// input : array V, integer N, integer n, group g
// output : none
for i<-0 to n-1
// 배열의 그룹 필드가 지정된 그룹과 일치한다면 출력
if (V[i].group = g)
print(V[i].elem)
return
- void removeGroup(g)
- 지정된 그룹의 모든 멤버 삭제
Alg removeGroup(g)
// input : array V, integer N, integer n, group g
// output : none
i <- 0
while (i<n)
if (V[i].group = g)
remove(V[i])
else
i <- i+1
return
<파이썬 구현>
# grouping_array_A.py
class group_array():
def __init__(self, N):
# 배열 입력 개수만큼 0으로 초기화
self.N = N # 최대 배열 개수
self.elem = [0] * N
self.group = [0] * N
self.n = 0 # 현재 원소 개수
def add(self, r, e, g):
if self.n + 1 == self.N:
print("FullListException")
else:
self.elem[r] = e
self.group[r] = g
self.n += 1
return
def traverseGroup(self, g):
for i in range(0, self.n):
if self.group[i] == g:
print('Group : ', g, 'Element : ', self.elem[i])
return
def removeGroup(self, g):
if self.n == 0:
print("EmptyListException")
else:
i = 0
while i < self.n:
if self.group[i] == g:
# 한칸씩 앞으로 땡겨오기
for j in range(i+1, self.n):
self.group[j - 1] = self.group[j]
self.elem[j - 1] = self.elem[j]
self.n -= 1
else:
i += 1
return
from grouping_array_A import group_array
new_array = group_array(8)
new_array.add(0, 'z1', 'Z')
new_array.add(1, 'x1', 'X')
new_array.add(2, 'z2', 'Z')
new_array.add(3, 'y1', 'Y')
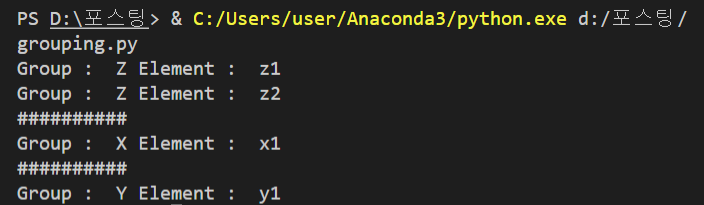
new_array.traverseGroup('Z')
print('#' * 10)
new_array.removeGroup('Z')
new_array.traverseGroup('X')
print('#' * 10)
new_array.traverseGroup('Y')
<실행 결과>
2. 부리스트 (sublist) 들의 리스트 사용
"그룹"을 표현하기 위해 그룹의 리스트를 사용하며, 각 그룹이 다시 원소들의 부리스트로 구성됨
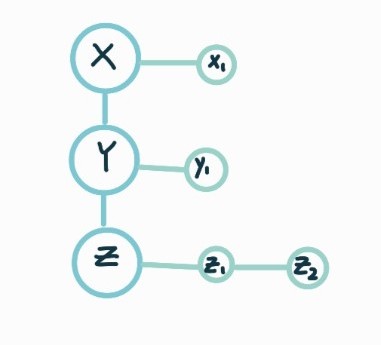
특정 그룹에 대한 작업을 처리할 때, 모든 요소를 순회하지 않고도 격리해서 처리할 수 있다는 장점이 존재한다.
- 구현 방법 A. 연결리스트 이용
리스트는 헤더 및 트레일러 주소를 저장하기 위한 두 개의 1D 배열로, 부리스트는 각 그룹에 대한 이중연결리스트로 구현
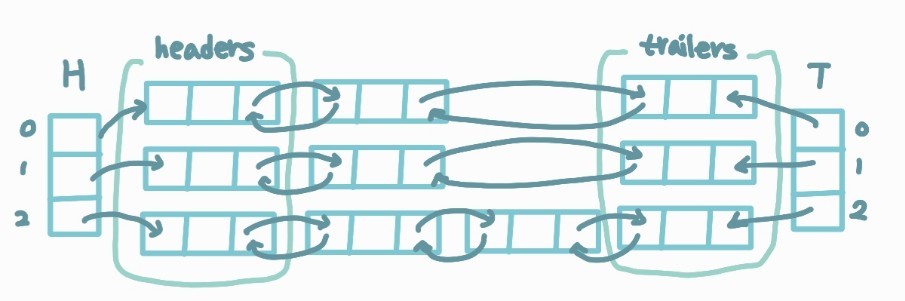
배열 구현 방법보다 기억 장소 낭비를 줄일 수 있다.
<구현 ADT & 의사코드>
- void initGroup()
- 헤더, 트레일러 할당하고 초기화
Alg initGroup()
// input : array H, array T, integer M
// output : header p, trailers, empty doubly linked lists
for i <- 0 to M - 1
// 헤더, 트레일러 노드
h <- getnode()
t <- getnode()
h.next <- t
t.prev <- h
// 헤더 리스트에 저장
H[i] <- h
// 트레일러 리스트에 저장
T[i] <- t
return
- void traverseGroup(g)
- 지정된 그룹의 모든 멤버들을 출력
Alg traverseGroup(g)
// input : array H, T, group g
// output : none
p <- H[g].next
while (p != T[g])
print(p.elem)
p = p.next
return
- void removeGroup(g)
- 지정된 그룹의 모든 멤버 삭제
Alg removeGroup(g)
// input : array H, array T, group g
// output : none
remove(H[g])
remove(T[g])
return
<파이썬 구현>
# grouping_linked_list_B.py
from asyncio.windows_events import NULL
class node():
def __init__(self, e, g, prev=None, next=None):
self.elem = e
self.group = g
self.prev = prev
self.next = next
class grouping_linked_list():
# 동적 할당 받으면 되니까 처음부터 공간 얼마 필요한지 필요 X
def __init__(self, M):
self.H = [0]*M
self.T = [0]*M
for i in range(0, M):
self.head = node(NULL, NULL)
self.tail = node(NULL, NULL)
# tail prev에 head 할당
self.head.next = self.tail
self.tail.prev = self.head
# 헤더, 트레일러 리스트에 각각 저장
self.H[i] = self.head
self.T[i] = self.tail
return
def addFirst(self, e, g):
if g == 'X':
ridx = 0
elif g == 'Y':
ridx = 1
else:
ridx = 2
p = self.H[ridx].next
q = node(e, g, p.prev, p)
(p.prev).next = q
p.prev = q
return
def traverseGroup(self, g):
if g == 'X':
ridx = 0
elif g == 'Y':
ridx = 1
else:
ridx = 2
p = self.H[ridx].next
while p != self.T[ridx]:
print('Group :', g, 'Element :', p.elem)
p = p.next
return
def removeGroup(self, g):
if g == 'X':
ridx = 0
elif g == 'Y':
ridx = 1
else:
ridx = 2
p = self.H[ridx].next
while p != self.T[ridx]:
pnext = p.next
(p.prev).next = p.next
(p.next).prev = p.prev
p = pnext
return
# grouping.py
from grouping_linked_list_B import grouping_linked_list
# 그룹 개수, 최대 개수
new_array = grouping_linked_list(3)
new_array.addFirst('z1', 'Z')
new_array.addFirst('x1', 'X')
new_array.addFirst('z2', 'Z')
new_array.addFirst('y1', 'Y')
new_array.traverseGroup('Z')
print('#' * 10)
new_array.removeGroup('Z')
new_array.traverseGroup('X')
print('#' * 10)
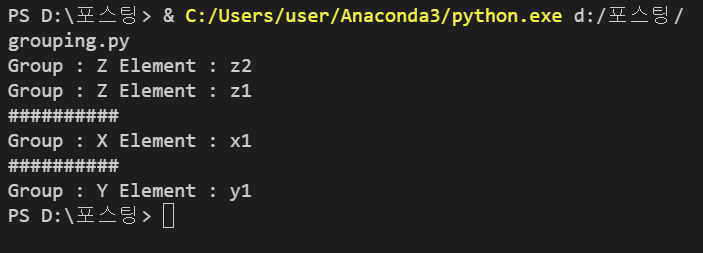
new_array.traverseGroup('Y')
<실행 결과>
- 구현 방법 B. 2D 배열 이용
M*N 배열을 사용해 리스트는 각 그룹을 나타내는 행을 / 부리스트는 각 행의 원소들을 이용해 구현
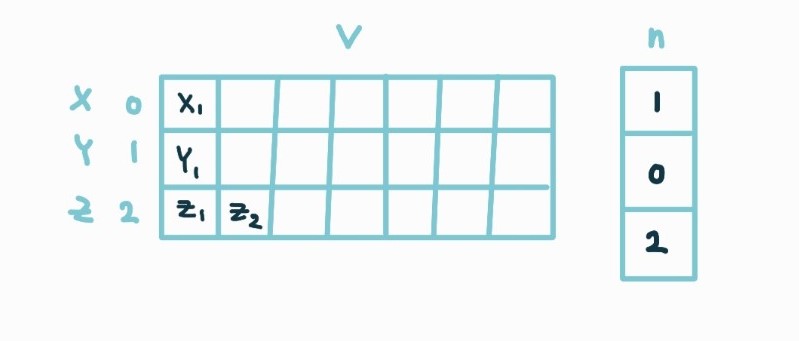
M은 그룹의 개수, N은 각 그룹 중 최대 원소 개수를 가진 그룹의 원소 수
열의 크기 N이 최대 그룹 크기를 커버해야 하므로 기억장소가 낭비된다는 단점이 존재한다.
<구현 ADT & 의사코드>
- void initGroup()
- 2차원 배열 할당하고 초기화
Alg initGroup()
// input : array V, array U, integer N, integer M
// output : array U of size M
for i<-0 to M-1
U[i] <- 0
return
- void traverseGroup(g)
- 지정된 그룹의 모든 멤버들을 출력
Alg initGroup()
// input : array V, array U, integer N, group g
// output : none
for j<-0 to U[g] - 1
print(V[g, j]) // 특정 그룹 전체 원소 순회
return
- void removeGroup(g)
- 지정된 그룹의 모든 멤버 삭제
Alg removeGroup(g)
// input : array V, array U, integer N, group g
// output : none
U[g] <- 0
return
<파이썬 구현>
# grouping_array_B.py
class group_array():
def __init__(self, M, N):
# 2차원 배열 크기 입력 받기
# M은 그룹 개수, N은 각 그룹 중 최대 원소 개수를 가진 그룹의 원소 수
self.M = M
self.N = N
self.arr = [[0] * N for i in range(M)]
self.n = [0] * M
def addFirst(self, e, g):
if g == 'X':
ridx = 0
elif g == 'Y':
ridx = 1
else:
ridx = 2
for i in range(self.n[ridx]-1, -1, -1):
self.arr[ridx][i+1] = self.arr[ridx][i]
self.arr[ridx][0] = e
self.n[ridx] += 1
return
def traverseGroup(self, g):
if g == 'X':
ridx = 0
elif g == 'Y':
ridx = 1
else:
ridx = 2
for i in range(self.n[ridx]):
print('Group : ', g, 'Element : ', self.arr[ridx][i])
return
def removeGroup(self, g):
if g == 'X':
ridx = 0
elif g == 'Y':
ridx = 1
else:
ridx = 2
if self.n[ridx] == 0:
print("EmptyListException")
else:
i = 0
while i < self.n[ridx]:
# 한칸씩 앞으로 땡겨오기
for j in range(i + 1, self.n[ridx]):
self.arr[ridx][j - 1] = self.arr[ridx][j]
self.n[ridx] -= 1
i += 1
return
# grouping.py
from grouping_array_B import group_array
# 그룹 개수, 최대 개수
new_array = group_array(3,6)
new_array.addFirst('z1', 'Z')
new_array.addFirst('x1', 'X')
new_array.addFirst('z2', 'Z')
new_array.addFirst('y1', 'Y')
new_array.traverseGroup('Z')
print('#' * 10)
new_array.removeGroup('Z')
new_array.traverseGroup('X')
print('#' * 10)
new_array.traverseGroup('Y')
<실행 결과>

공유 (sharing)
위에서 서로 다른 그룹에 속하는 원소들을 다루는 방법들을 알아봤다.
그렇다면 동일한 원소가 다른 그룹에 의해 공유된다면 어떨까?
역시 예시를 보고 이해해보자.
대학 강좌 리스트 중 'Data Structure (DS)' 라는 과목을 Student A, B, C가 모두 수강한다고 할 때 'DS' 원소는 공유 데이터원소이다.
- Student A : DS, OS
- Student B : DB, DS
- Student C : DS, OS, DB, MM
설계 방안
1. 레코드의 리스트 사용
"그룹" 에서의 설계 방안 1과 비슷하다!
"공유" 를 표현하기 위해 원소 및 그룹 필드로 구성된 리스트를 사용한다.

서로 다른 그룹에 속하는 원소들을 다룰 때처럼, 리스트에 해당 원소와 해당 그룹 필드로 이루어진 노드 추가하는 방식이다.
간단하지만 특정 원소 / 그룹 작업 모두에 전체 레코드 순회가 필요하기에 처리 시간이 증가한다는 단점을 가지고 있다.
- 설계 방안 A : 배열을 이용한 구현
리스트를 elem 및 group 필드로 구성된 레코드의 1D 배열로 구현
기억장소 낭비가 없다는 장점이 존재한다.

- 설계 방안 B : 연결리스트를 이용한 구현
elem, group 필드로 구성된 노드로 구성된 연결리스트 사용
기억장소 사용을 최소화한다는 장점이 존재한다.

구현 방법은 "그룹" 에서와 동일하기에 생략하도록 하겠다.
[내부링크]
2. 다중리스트 사용
공유를 표현하기 위해, 원소들의 리스트와 그룹들의 리스트가 교차하는 형태의 다중리스트를 사용한다.
글로만 보면 좀 어려우니까 그림을 통해 이해해보자!

Elements와 Groups의 교차점에 있는 서브리스트는 원소-그룹 사이의 관련성 여부를 표현한다.
특정 원소 및 특정 그룹 관련 작업 모두 별도로 처리 가능하다는 장점이 존재한다.
- 설계 방안 A : 2D 배열 사용
행 - 원소 / 열 - 그룹을 나타내는 2D boolean 배열을 사용한다.
구현하기는 간단하지만 원소-그룹 간 관계가 희소한 경우 기억장소가 낭비된다는 단점이 존재한다.
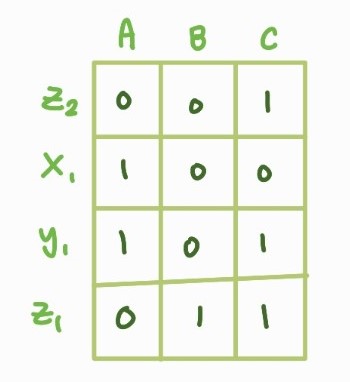
<구현 ADT & 의사코드>
- void initShare()
- 2차원 boolean 배열 할당하고 초기화
Alg initShare()
// input : array V, integer NE, integer NG
// output : array V of size M*N
for i<-0 to NE-1
for j<-0 to NG-1
V[i] <- False
return
- void traverseShareElements(g)
- 지정된 그룹과 관련된 모든 원소들 방문
Alg traverseShareElements(g):
// input : array V, group g
// output : none
col <- V[g]
for elem in col
if elem = true
visit(elem)
return
- void traverseShareGroups(e)
- 지정된 원소와 관련된 모든 그룹들 방문
Alg traverseShareGroups(e):
// input : array V, element e
// output : none
row <- V[e]
for elem in row
if elem = true
visit(elem)
return
- void addShare(e,g)
- (원소, 그룹) 쌍을 삽입
Alg addShare(e, g):
// input : array V, element e, group g
// output : none
V[g][e] = true
return
- void deleteShare(e)
- 지정된 원소를 모든 그룹에서 삭제
Alg deleteShare(e):
// input : array V, element e
// output : none
for g in V:
V[g][e] = false
return
<파이썬 구현>
# share_arr.py
class array_share:
def __init__(self, M, N):
# 2차원 배열 크기 입력 받기
# M은 그룹 개수, N은 원소 개수
self.M = M
self.N = N
self.arr = [[False] * M for i in range(N)]
def addShare(self, e, g):
col_list = {'A' : 0, 'B':1, 'C':2}
row_list = {'z2' : 0, 'x1' : 1, 'y1' : 2, 'z1' : 3}
col_idx = col_list[g]
row_idx = row_list[e]
self.arr[row_idx][col_idx] = True
return
def deleteShare(self, e):
col_list = {'A' : 0, 'B' : 1, 'C' : 2}
row_list = {'z2' : 0, 'x1' : 1, 'y1' : 2, 'z1' : 3}
row_idx = row_list[e]
for idx in range(len(self.arr[row_idx])):
self.arr[row_idx][idx] = False
return
def traverseShareElements(self, g):
col_list = {'A' : 0, 'B':1, 'C':2}
row_list = {'0' : 'z2', '1':'x1', '2':'y1', '3' : 'z1'}
col_idx = col_list[g]
for idx, elem in enumerate(self.arr):
if elem[col_idx] == True:
print(row_list[str(idx)])
return
def traverseShareGroups(self, e):
col_list = {'0' : 'A', '1':'B', '2':'C'}
row_list = {'z2' : 0, 'x1' : 1, 'y1' : 2, 'z1' : 3}
row_idx = row_list[e]
for idx, elem in enumerate(self.arr[row_idx]):
if elem == True:
print(col_list[str(idx)])
return
# shared_list.py
from share_arr import array_share
share_list = array_share(3,4)
for i in share_list.arr:
for j in i:
print(j, end=' ')
print()
print('#'*15)
# 초기 배열 관계 설정
share_list.addShare('z2', 'C')
share_list.addShare('x1', 'A')
share_list.addShare('y1', 'A')
share_list.addShare('y1', 'C')
share_list.addShare('z1', 'B')
share_list.addShare('z1', 'C')
for i in share_list.arr:
for j in i:
print(j, end=' ')
print()
print('#'*15)
share_list.traverseShareElements('C')
share_list.traverseShareGroups('z1')
share_list.deleteShare('y1')
for i in share_list.arr:
for j in i:
print(j, end=' ')
print()
print('#'*15)
<실행 결과>

- 설계 방안 B : 다중 연결리스트를 이용한 구현
1. 두 개의 배열을 이용해 원소 및 그룹 리스트를 각각 구현
2. 원형 헤더 연결리스트들을 이용해 (원소, 그룹) 부리스트들을 구현
구현하기는 설계방안 A보다 복잡하지만 기억장소 낭비를 최소화할 수 있다.
구현 방법을 과정별로 살펴보자.
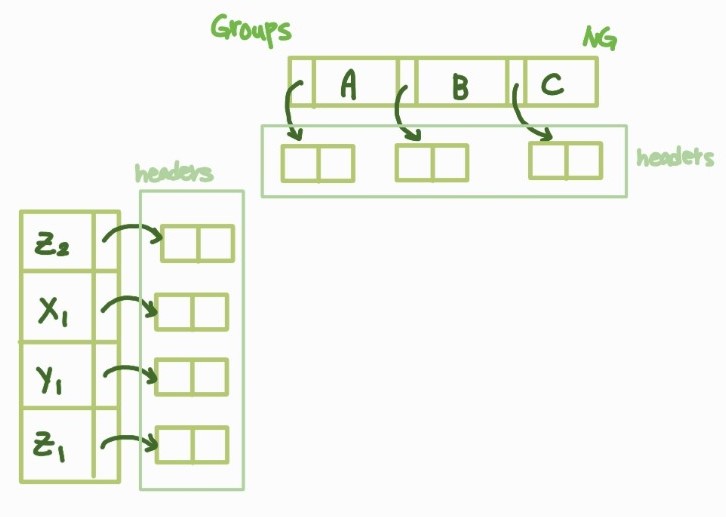

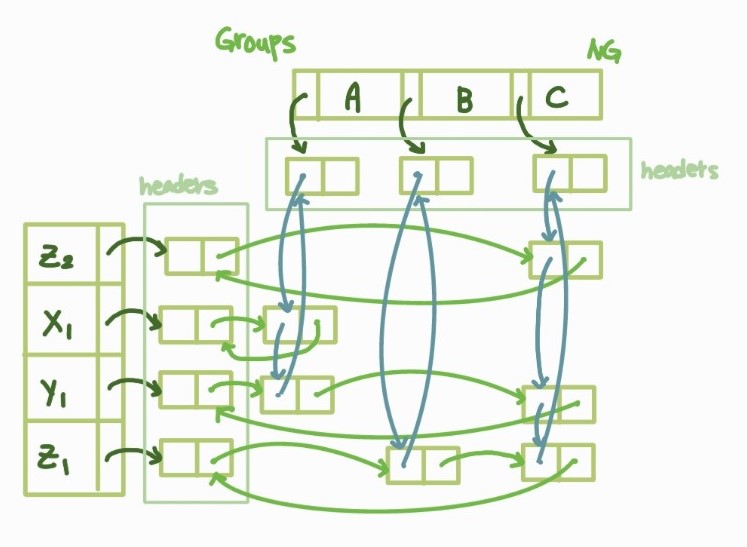
하지만 (e, g) 노드 1개 또는 특정 원소나 특정 그룹의 모든 (e,g) 노드를 삭제할 때 이전 노드 참조가 필요하기 때문에 단일 연결리스트를 이용해서 구현할 경우 많은 시간 소요됨 -> 이중연결리스트 사용!
헤더-트레일러 원형이중연결리스트 (이름이 참 길다..) 구조를 활용해서 다시 한 번 그려보자
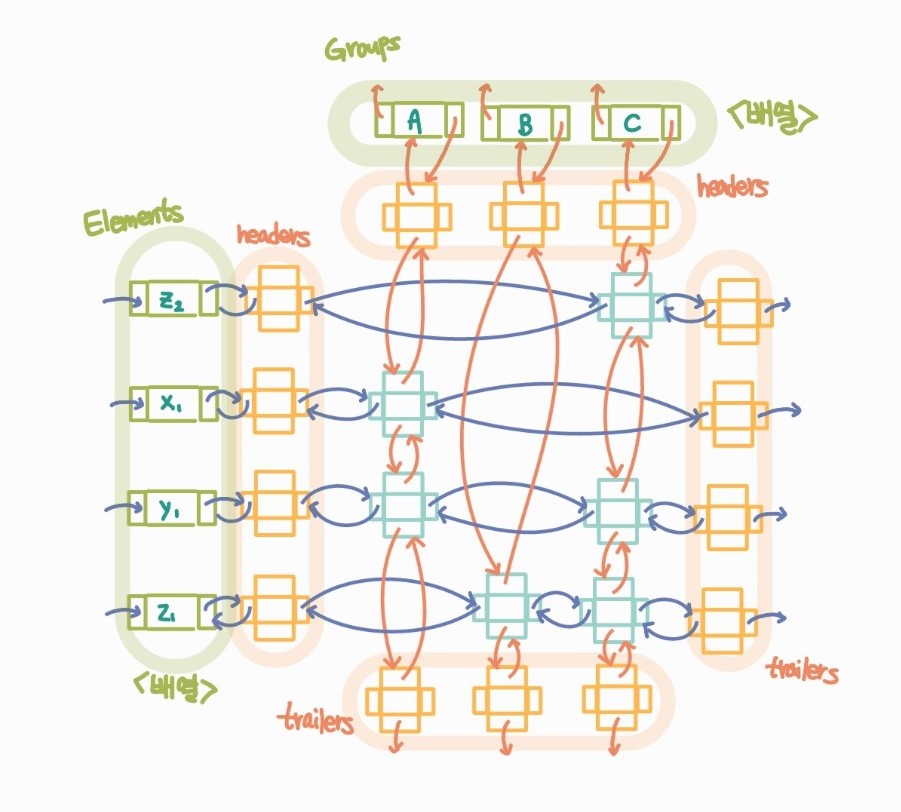
<구현 ADT & 의사코드>
- void initGroup()
- elements 리스트와 groups 리스트에 헤더리스트 연결
Alg initShare()
// input : array elements, groups, integer NE, integer NG
// output : an empty multilinkedlist
for i <- 0 to NE-1
H <- getnode()
H.nextgroup <- H
elements[i].header <- H
for i <- 0 to NG-1
H <- getnode()
H.nextelement <- H
groups[i].header <- H
return
- void traverseShareElements(g)
- 지정된 그룹과 관련된 모든 원소들 방문
Alg traverseShareElements(g):
// input : array Groups, group g
// output : none
H <- Groups[g].header
p <- H.nextelement
while (p!=H)
visit(p)
p <- p.nextelement
return
- void traverseShareGroups(e)
- 지정된 원소와 관련된 모든 그룹들 방문
Alg traverseShareGroups(e)
// input : array elements, element e
// output : none
H <- elements[e].header
p <- H.nextgroup
while (p!=H)
visit(p)
p <- p.nextgroup
return
- void addShare(e,g)
- (원소, 그룹) 쌍을 맨 앞에 삽입
Alg addShare(e,g)
// input : array elements, array groups, element e, group g
// output : none
p <- getnode()
HG <- groups[g].header
p.nextelement <- HG.nextelement
HG.nextelement <- p
HE <- elements[e].header
p.nextgroup <- HE.nextgroup
HE.nextgroup <- p
return
- void deleteShare(e)
- 지정된 원소를 모든 그룹에서 삭제
Alg deleteShare(e)
// input : array elements, array groups, element e
// output : none
HE <- elements[e].header
TE <- elements[e].trailer
p = HE.next
while p != TE:
# prev-next 삭제하기
(p.prev).next = p.next
(p.next).prev = p.prev
# up-down 삭제하기
(p.up).down = p.down
(p.down).up = p.up
p = p.next
return
<파이썬 구현> -- 버그 고침!!
# share_node.py
class node:
def __init__(self, elem=None, prev=None, next=None):
self.elem = elem
self.prev = prev
self.next = next
class inner_node:
def __init__(self, elem=None, group=None, prev=None, next=None, up=None, down=None):
self.elem = elem
self.group = group
self.prev = prev
self.next = next
self.up = up
self.down = down
class array:
def __init__(self, N, cmd, dic=None):
self.arr = []
for i in range(N):
self.arr.append(node())
dic_list = list(dic.keys())
# header & trailer 설정 - inner_node로 change
if cmd == 'E':
for i in range(N):
self.arr[i].elem = dic_list[i]
header = inner_node()
header.elem = "header "+str(i)
self.arr[i].next = header
header.prev = self.arr[i]
trailer = inner_node()
trailer.elem = "trailer " + str(i)
header.next = trailer
trailer.next = self.arr[i]
self.arr[i].prev = trailer
else:
for i in range(N):
self.arr[i].elem = dic_list[i]
header = inner_node()
header.elem = "header "+str(i)
self.arr[i].next = header
header.up = self.arr[i]
trailer = inner_node()
trailer.elem = "trailer " + str(i)
header.down = trailer
trailer.down = self.arr[i]
trailer.up = header
self.arr[i].prev = trailer
class double_linked_list:
def __init__(self, M, N, group_dict, elem_dict):
self.groups = array(M, 'G', group_dict)
self.elements = array(N, 'E', elem_dict)
self.group_dict = group_dict
self.elem_dict = elem_dict
def addShare(self, e, g):
print("#### add Element", e, "in Group", g, "####")
group_arr = self.groups.arr
elem_arr = self.elements.arr
group_header = group_arr[self.group_dict[g]].next
group_trailer = group_arr[self.group_dict[g]].prev
elem_header = elem_arr[self.elem_dict[e]].next
elem_trailer = elem_arr[self.elem_dict[e]].prev
# print("#### header & trailer check ####")
# print("헤더 :", group_header.elem)
# print("트레일러 :", group_trailer.elem)
# print("헤더 :", elem_header.elem)
# print("트레일러 :", elem_trailer.elem)
# print("<newNode 연결>")
newNode = inner_node(e, g, elem_header, elem_header.next, group_header, group_header.down)
(elem_header.next).prev = newNode
(group_header.down).up = newNode
elem_header.next = newNode
group_header.down = newNode
# print("#### groups와의 connection check ####")
# print("헤더 -> 새 노드 :", group_header.down.elem)
# print("새 노드 -> 헤더 :", newNode.up.elem)
# print("새 노드 -> 트레일러 :", newNode.down.elem)
# print("트레일러 -> 새 노드", group_trailer.up.elem)
def deleteShare(self, e):
elem_arr = self.elements.arr
elem_header = elem_arr[self.elem_dict[e]].next
elem_trailer = elem_arr[self.elem_dict[e]].prev
p = elem_header.next
while p != elem_trailer:
(p.down).up = p.up
(p.up).down = p.down
(p.next).prev = p.prev
(p.prev).next = p.next
p.elem = "deleted"
p = p.next
# group 에서 up down 연결이 제대로 안된듯 하다
def traverseShareElements(self, g):
group_arr = self.groups.arr
print("###### print start about group", g, "######")
group_header = group_arr[self.group_dict[g]].next
group_trailer = group_arr[self.group_dict[g]].prev
p = group_header.down
while p != group_trailer:
print(p.elem)
p = p.down
print("###### print end ######")
def traverseShareGroups(self, e):
elem_arr = self.elements.arr
print("###### print start about element", e, "######")
elem_header = elem_arr[self.elem_dict[e]].next
elem_trailer = elem_arr[self.elem_dict[e]].prev
p = elem_header.next
while p != elem_trailer:
print(p.group)
p = p.next
print("###### print end ######")
from share_node import double_linked_list
group_dict = {'A' : 0, 'B' : 1, 'C' : 2}
elem_dict = {'z2' : 0, 'x1' : 1, 'y1' : 2, 'z1' : 3}
share_list = double_linked_list(3, 4, group_dict, elem_dict)
# 초기 배열 관계 설정
share_list.addShare('z2', 'C')
share_list.addShare('x1', 'A')
share_list.addShare('y1', 'A')
share_list.addShare('y1', 'C')
share_list.addShare('z1', 'B')
share_list.addShare('z1', 'C')
share_list.traverseShareElements('C')
share_list.traverseShareGroups('z1')
share_list.deleteShare('z1')
share_list.traverseShareElements('C')
<실행 결과>

'알고리즘 > 자료구조_알고리즘' 카테고리의 다른 글
| [자료구조] 06. 스택 (Stack) (1) | 2022.08.25 |
|---|---|
| [자료구조] 05. 집합 (0) | 2022.08.25 |
| [자료구조] 04(1). 연결리스트 구현 (0) | 2022.08.11 |
| [자료구조] 03. 기초 데이터구조 - 배열, 연결리스트 (0) | 2022.08.05 |
| [자료구조] 02. 재귀 (0) | 2022.08.04 |



