포스팅을 시작하기 전에
저번 포스팅이 굉장히 오래 걸렸다..
(놀기도 열심히 놀았구)
구현/응용 부분은 나중에 추가적으로 보충해야지
키워드
#집합 #합집합 #교집합 #차집합 #부분집합
1. 집합 개념
집합 (set)은 특정한 조건에 맞는 별개의 원소들의 모임이다.
집합 A = {a,b,c} 가 존재할 때 $$a \in A$$ 와 같이 원소 a가 집합 A에 속해있음을 표현할 수 있고, $$d \notin A$$ 와 같이 원소 d가 집합 A에 속해있지 않음을 표현할 수 있다.
다음과 같은 두 개의 집합 A, B를 두고 개념을 설명하도록 하겠다.
A = {a, b, d, e, f, g}
B = {b, c, e, i}

합집합 (Union)
$$ A \cup B = {x | x \in A or x \in B}$$
집합 A 혹은 집합 B 중 적어도 하나에 속하는 원소의 집합

교집합 (intersect)
$$ A \cap B = {x | x \in A and x \in B}$$
집합 A와 B에 모두 속하는 원소의 집합

차집합 (subtraction)
$$ A - B = {x | (x \in A and x \notin B)} $$
: 집합 A에 속하지만 집합 B에 속하지는 않는 원소의 집합
$$ B - A = {x | (x \notin A and x \in B)} $$
: 집합 B에 속하지만 집합 A에 속하지는 않는 원소의 집합
검색하다 처음 안 사실인데 A-B 말고 A \ B로 표기하기도 한다고 한다.. 신기


대칭차 (symmetric difference)
둘 중 한 집합에는 속하지만 둘 모두에는 속하지 않는 원소들의 집합
$$ A \vartriangle B = {x | (x \in A and x \notin B) or (x \notin A and x \in B)} = (A \cup B) \ (A \cap B) = (A \ B) \cup (B \ A) $$

2. 집합 구현
집합 ADT
집합 ADT는 유일한 개체들을 담는 용기를 모델링한다.
(그러니까 집합 내에서 중복된 개체는 없다는 뜻이다!)
집합은 시스템 내에서 집합 원소들의 정렬된 리스트로 표현할 수 있다.
집합 메서드
집합 A, B가 존재한다고 가정할 때,
- set union(B) : 집합 A와 B의 합집합을 반환
- set intersect(B) : 집합 A와 B의 교집합 반환
- set subtract(B) : 집합 B를 차감한 차집합 반환
<일반 메서드>
- integer size() : 집합 크기 반환
- boolean isEmpty() : 공집합인지 아닌지 여부 boolean 값으로 반환
- iterator elements() : 요소 순회
<갱신 메서드>
- addElem(e) : 집합에 원소 e 추가
- removeElem(e) : 집합으로부터 원소 e 삭제
<질의 메서드>
- boolean member(e) : 개체 e가 집합의 원소인지 여부 반환
- boolean subset(B) : 집합이 집합 B의 부분집합인지 여부를 반환
<예외>
- emptySetException() : 비어있는 집합에 대해 삭제 혹은 첫 원소 접근을 시도할 경우 발령
구현 방법
앞에서 배웠던 연결리스트, 배열을 이용해서 구현할 수 있다!
노드 하나당 하나의 집합 원소로 표현하면 된다.
집합의 정의에서 다뤘던 것처럼 집합 내에서 원소 중복은 불가능하고, 원소들은 일정한 순서에 의해 정렬되어 저장된다는 점을 유의하자!
이번 구현할 메서드는 파괴적인 메서드이므로 대상 집합 A, B를 보존하지 않는다.
파괴적 VS 비파괴적
어떤 알고리즘/메서드가 "파괴적"이라 함은 알고리즘/메서드의 수행 결과 기존 데이터구조의 원형이 보존되지 않는 것을 의미한다!
즉, 자기 자신을 변화시키는 메서드이다.
예를 들어 배열에서의 add 메서드의 경우 배열의 원소들을 하나씩 뒤로 밀어내므로 메서드 적용 전/후 배열이 다르다.
반면 "비파괴적"은 데이터구조의 원형이 보존되는 것이다.
파이썬의 upperCase같은 경우 메서드를 적용하더라도 원형 문자열이 보존된다.


파괴적 구현방법
- set union(B) : 집합 A와 B의 합집합을 반환
Alg union(B)
// input set A,B [sorted]
// output set A \cup B
C <- empty list // 합집합이 될 리스트
while (!A.isEmpty() & !B.isEmpty()) // A, B 중 하나가 공집합이 되기 전까지
a, b <- A.get(1), B.get(1) // 각 집합 첫 번째 원소 가져오기
// 작은 원소부터 순서대로 합집합 C에 추가한다
if (a<b)
C.addLast(a)
A.removeFirst()
else if (a>b)
C.addLast(b)
B.removeFirst()
else // a=b (A, B의 교집합 원소)
C.addLast(a)
A.removeFirst()
B.removeFirst()
// A의 나머지 원소들 추가
while (!A.isEmpty())
a <- A.get(1)
C.addLast(a)
A.removeFirst()
while (!B.isEmpty())
b <- B.get(1)
C.addLast(b)
B.removeFirst()
return C
- set intersect(B) : 집합 A와 B의 교집합 반환
Alg intersect(B)
// input set A,B [sorted]
// output set A \cap B
C <- empty list // 교집합이 될 리스트
while (!A.isEmpty() & !B.isEmpty()) // A, B 중 하나가 공집합이 되기 전까지
a, b <- A.get(1), B.get(1) // 각 집합 첫 번째 원소 가져오기
// 교집합 이외의 모든 원소 제거
if (a<b)
A.removeFirst()
else if (a>b)
B.removeFirst()
else // a=b (A, B의 교집합 원소)
C.addLast(a)
A.removeFirst()
B.removeFirst()
while (!A.isEmpty())
A.removeFirst()
while (!B.isEmpty())
B.removeFirst()
return C
- set subtract(B) : 집합 B를 차감한 차집합 반환
Alg subtract(B)
// input set A,B [sorted]
// output set A - B
C <- empty list // 차집합(A-B)이 될 리스트
while (!A.isEmpty() & !B.isEmpty()) // A, B 중 하나가 공집합이 되기 전까지
a, b <- A.get(1), B.get(1) // 각 집합 첫 번째 원소 가져오기
if (a<b)
C.addLast(a) // 집합 A의 원소 추가
A.removeFirst()
else if (a>b)
B.removeFirst()
else // a=b (A, B의 교집합 원소) 교집합 추가 X
A.removeFirst()
B.removeFirst()
while (!A.isEmpty())
a <- A.get(1) // 집합 A의 원소 추가
A.removeFirst()
while (!B.isEmpty())
B.removeFirst()
return C
- boolean member(e) : 개체 e가 집합의 원소인지 여부 반환
Alg member(e)
// input set A, element e
// set A는 오름차순으로 정렬되어 있음
// output boolean value
if (A = empty_list) // a가 공집합일 때
return false
p <- A // p에 집합 A 복사
while (true)
a <- p.elem // p의 집합 원소 하나 꺼내기
if (a<e)
if (p.next = NULL) // p가 마지막 노드일 때
return false
else
p <- p.next // 다음 노드 순회
// 오름차순 정렬되어 있으므로 e가 집합 A의 원소이면 a가 e보다 클 수 없음
else if(a>e)
return false
else // a=e, e가 집합 A의 원소임을 의미
return true
- boolean subset(B) : 집합이 집합 B의 부분집합인지 여부를 반환
Alg subset(B)
// input set A, B
// output boolean
if (A = empty_list)
return true
p <- A
while (true)
if (B.member(p.elem))
if (p.next = NULL) // p가 마지막 노드일 때
return true
else
p <- p.next
else
return false
<파이썬 구현> - 배열을 통한 구현
파괴적 구현방법이기 때문에 한 번에 한 개의 메서드만 실행 가능하다 (원래의 데이터 구조가 파괴되기 때문)
# array_linked_list.py -- 이전 연결리스트에서 사용
from asyncio.windows_events import NULL
class array_linked_list:
# 초기 n=0 (원소 개수)
def __init__(self):
self.n = 0
# 리스트 초기화 메서드
def initialize(self, N):
self.arr = [0]*N
self.N = N
# 일반 메서드
def isEmpty(self):
if self.n == 0:
return True
else:
return False
def size(self):
return self.n
def traverse(self):
for i in range(self.n):
print(self.arr[i], end=' ')
return
# 접근 메서드
def get(self, r):
if r<0 or r>self.n:
print("invalidRankException")
return NULL
elif self.n == 0:
print("emptyListException")
return NULL
else:
return self.arr[r]
# 갱신 메서드
def set(self, r, e):
if r<0 or r>self.n:
print("invalidRankException")
return NULL
else:
self.arr[r] = e
return e
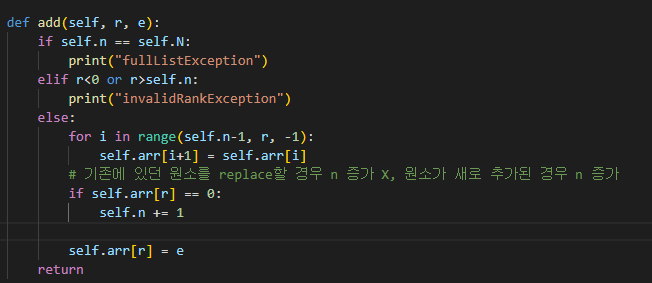
def add(self, r, e):
if self.n == self.N:
print("fullListException")
elif r<0 or r>self.n:
print("invalidRankException")
else:
for i in range(self.n-1, r, -1):
self.arr[i+1] = self.arr[i]
# 기존에 있던 원소를 replace할 경우 n 증가 X, 원소가 새로 추가된 경우 n 증가
if self.arr[r] == 0:
self.n += 1
self.arr[r] = e
return
def addFirst(self, e):
if self.n == self.N:
print("fullListException")
elif self.n > 0:
for i in range(self.n-1, -1, -1):
self.arr[i+1] = self.arr[i]
self.arr[0] = e
self.n += 1
return
def addLast(self, e):
if self.n == self.N:
print("fullListException")
else:
self.n += 1
self.arr[self.n - 1] = e
return
def remove(self, r):
if r<0 or r>self.n-1:
print("invalidRankException")
return NULL
elif self.n == 0:
print("emptyListException")
return NULL
else:
e = self.arr[r]
for i in range(r+1, self.n):
self.arr[i-1] = self.arr[i]
self.n -= 1
return e
def removeFirst(self):
if self.n == 0:
print("emptyListException")
return NULL
else:
e = self.arr[0]
for i in range(1, self.n):
self.arr[i-1] = self.arr[i]
self.n -= 1
return e
def removeLast(self):
if self.n == 0:
print("emptyListException")
return NULL
else:
e = self.arr[self.n-1]
self.n -= 1
return e
from array_linked_list import array_linked_list
# 내장메서드와의 겹침 피하기 위해 대문자로 작성
class Set:
def __init__(self, A, B):
self.A = A
self.B = B
def Union(self):
max_len = self.A.n + self.B.n
# 클래스 호출
C = array_linked_list()
C.initialize(max_len)
while not(self.A.isEmpty()) and not(self.B.isEmpty()):
a = self.A.get(0)
b = self.B.get(0)
# 작은 원소부터 순서대로 합집합 C에 추가
if a<b:
C.addLast(a)
self.A.removeFirst()
elif a>b:
C.addLast(b)
self.B.removeFirst()
else:
C.addLast(a)
self.A.removeFirst()
self.B.removeFirst()
# A의 나머지 원소들 추가
while not(self.A.isEmpty()):
a = self.A.get(0)
C.addLast(a)
self.A.removeFirst()
# B의 나머지 원소들 추가
while not(self.B.isEmpty()):
b = self.B.get(0)
C.addLast(b)
self.B.removeFirst()
return C
def Intersect(self):
max_len = self.A.n if self.A.n > self.B.n else self.B.n
# 클래스 호출
C = array_linked_list()
C.initialize(max_len)
while not(self.A.isEmpty()) and not(self.B.isEmpty()):
a = self.A.get(0)
b = self.B.get(0)
# 작은 원소부터 순서대로 합집합 C에 추가
if a<b:
self.A.removeFirst()
elif a>b:
self.B.removeFirst()
else:
C.addLast(a)
self.A.removeFirst()
self.B.removeFirst()
# A의 나머지 원소들 추가
while not(self.A.isEmpty()):
if self.A.isEmpty()==True:
break
self.A.removeFirst()
# B의 나머지 원소들 추가
while not(self.B.isEmpty()):
if self.B.isEmpty()==True:
break
self.B.removeFirst()
return C
def Subtract(self, cmd):
if cmd == 'B': # 'A' - 'B'
# 클래스 호출
C = array_linked_list()
C.initialize(self.A.n)
while not(self.A.isEmpty()) and not(self.B.isEmpty()):
a = self.A.get(0)
b = self.B.get(0)
if a<b:
C.addLast(a)
self.A.removeFirst()
elif a>b:
self.B.removeFirst()
else:
self.A.removeFirst()
self.B.removeFirst()
while not(self.A.isEmpty()):
a = self.A.get(0)
C.addLast(a)
self.A.removeFirst()
while not(self.B.isEmpty()):
self.B.removeFirst()
else:
# 클래스 호출
C = array_linked_list()
C.initialize(self.B.n)
while not(self.A.isEmpty()) and not(self.B.isEmpty()):
a = self.A.get(0)
b = self.B.get(0)
if b<a:
C.addLast(b)
self.B.removeFirst()
elif b>a:
self.A.removeFirst()
else:
self.A.removeFirst()
self.B.removeFirst()
while not(self.B.isEmpty()):
b = self.B.get(0)
C.addLast(b)
self.B.removeFirst()
while not(self.A.isEmpty()):
self.A.removeFirst()
return C
def member(self, cmd, e):
if cmd == 'A':
if self.A.isEmpty() == True:
return False
p = self.A
for i in range(p.n):
a = p.get(i)
if a < e:
if i >= p.n - 1: # p가 마지막 노드일 때
return False
# 오름차순 정렬되어 있으므로 e가 집합 A의 원소이면 a가 e보다 클 수 없음
elif a > e:
return False
# a = e, e가 집합 A의 원소임을 의미
else:
return True
else:
if self.B.isEmpty() == True:
return False
p = self.B
for i in range(p.n):
b = p.get(i)
if b < e:
if i >= p.n - 1: # p가 마지막 노드일 때
return False
# 오름차순 정렬되어 있으므로 e가 집합 B의 원소이면 b가 e보다 클 수 없음
elif b > e:
return False
# b = e, e가 집합 B의 원소임을 의미
else:
return True
def subset(self, cmd, set_arr):
if set_arr.isEmpty() == True:
return True
for i in range(set_arr.n):
p = set_arr.get(i)
if self.member(cmd, p):
if i >= set_arr.n - 1:
return True
else:
return False
# set.py
from set_list import Set
from array_linked_list import array_linked_list
# 집합 생성
A = array_linked_list()
A.initialize(6)
B = array_linked_list()
B.initialize(4)
A.addLast('a')
A.addLast('b')
A.addLast('d')
A.addLast('e')
A.addLast('f')
A.addLast('g')
B.addLast('b')
B.addLast('c')
B.addLast('e')
B.addLast('i')
D = array_linked_list()
D.initialize(2)
D.addLast('c')
D.addLast('i')
# 클래스 호출 및 실행
U = Set(A, B)
#U.Union().traverse()
#U.Intersect().traverse()
#U.Subtract('A').traverse()
#U.Subtract('B').traverse()
# print(U.member('A', 'a'))
# print(U.member('A', 'd'))
# print(U.member('A', 'f'))
# print(U.member('A', 'g'))
# print(U.member('B', 'c'))
# print(U.member('B', 'i'))
# print(U.member('A', 'c'))
# print(U.member('B', 'a'))
# print(U.subset('A', D))
# print(U.subset('B', D))


비파괴적 구현방법
원래의 집합을 파괴하지 않는 방법으로 구현하기 위해 union과 intersect를 재귀 알고리즘으로 구현할 것이다!
- 집합 A, B는 각각 정렬된 단일연결리스트로 구현되어 있다
- A, B는 각각 집합 A와 B의 첫 원소를 저장한 노드의 주소이며 공집합인 경우 주소는 NULL이다
- 각 노드는 elem과 next 필드로 구성된다
- set union(B) : 집합 A와 B의 합집합을 반환
Alg union(A, B)
// input set A, B
// output A \cup B
// base case (탈출조건)
if ((A = empty_list) & (B = empty_list)) // A, B 모두 공집합일 경우
return empty_list
p <- getnode() // 합집합 연결리스트 노드
// recursive part
// A만 공집합일 경우
if (A = empty_list)
p.elem <- B.elem // 노드에 집합 B 원소 할당
p.next <- union(A, B.next) // p 다음 원소 재귀적으로 연결
// B만 공집합일 경우
else if (B = empty_list)
p.elem <- A.elem // 노드에 집합 A 원소 할당
p.next <- union(A.next, B) // p 다음 원소 재귀적으로 연결
else
// 집합은 정렬된 상태로 유지되어야 한다는 것을 잊지 말것!
if (A.elem < B.elem) // A가 B 원소보다 작을 경우
p.elem <- A.elem // 노드에 집합 A 원소 할당
p.next <- union(A.next, B) // p 다음 원소 재귀적으로 연결
else if (A.elem > B.elem) // B가 A 원소보다 작을 경우
p.elem <- B.elem // 노드에 집합 B 원소 할당
p.next <- union(A, B.next) // p 다음 원소 재귀적으로 연결
else // A.elem = B.elem
p.elem <- A.elem // 노드에 집합 A 원소 할당 (B.elem도 상관 X)
p.next <- union(A.next, B.next) // p 다음 원소 재귀적으로 연결
return p // 합집합 노드 시작지점 반환
- set intersect(B) : 집합 A와 B의 교집합 반환
Alg intersect(A, B)
// input set A, B
// output A \cap B
// base case (탈출조건)
if ((A = empty_list) | (B = empty_list)) // A, B 중 하나가 공집합일 경우
return NULL
// 교집합 원소들만 존재하면 되므로 A가 공집합일 때, B가 공집합일 때는 고려할 필요 X
// recursive part
// 집합은 정렬된 상태로 유지되어야 한다는 것을 잊지 말것!
if (A.elem < B.elem) // A가 B 원소보다 작을 경우
return intersect(A.next, B) // A 다음 원소 탐색
else if (A.elem > B.elem) // B가 A 원소보다 작을 경우
return intersect(A, B.next) // B 다음 원소 탐색
else // A.elem = B.elem
p <- getnode() // 교집합 연결리스트 노드
p.elem <- A.elem // 노드에 집합 A 원소 할당 (B.elem도 상관 X)
p.next <- intersect(A.next, B.next) // p 다음 원소 재귀적으로 연결
return p // 교집합 노드 시작지점 반환
파이썬에서는...
파이썬에서는 기본적으로 set 자료형과 &, |, - 연산자를 지원하기 때문에 이렇게 복잡하게 구현할 필요가 없다!
set 자료형은 괄호 안에 리스트를 입력해 만들거나, 문자열을 입력해 만들수 있다.
A = set([2,3,5,8])
B = set("HelloWorld")
print(A)
print(B)
왜 넣은 문자열 순서대로 출력되지 않고, "HelloWorld"의 l은 왜 1개밖에 남아있지 않은가?
이는 set의 2가지 특징 때문이다.
1) 순서가 없다. 이는 리스트/튜플과 구분되는 큰 특징으로, 인덱싱을 통한 접근이 불가하다.
2) 중복을 허용하지 않는다. 위의 집합의 개념에서도 배웠던 내용이다.
# set2.py
A = list(input().split())
B = list(input().split())
A.sort()
B.sort()
print("집합 A :", A, "자료형 :", type(A))
print("집합 B :", B, "자료형 :", type(B))
setA = set(A)
setB = set(B)
print("집합 A :", setA, "자료형 :", type(setA))
print("집합 B :", setB, "자료형 :", type(setB))
print("## Union ##")
print(setA | setB)
print("## Intersect ##")
print(setA & setB)
print("## subtraction (A-B)##")
print(setA - setB)
print("## subtraction (B-A)##")
print(setB - setA)
print("## 원형 보존 확인 ##")
print(setA)
print(setB)
기호가 아닌 다음과 같은 메서드로도 똑같은 구현이 가능하다.
# set2.py
A = list(input().split())
B = list(input().split())
A.sort()
B.sort()
print("집합 A :", A, "자료형 :", type(A))
print("집합 B :", B, "자료형 :", type(B))
setA = set(A)
setB = set(B)
print("집합 A :", setA, "자료형 :", type(setA))
print("집합 B :", setB, "자료형 :", type(setB))
print("## Union ##")
print(setA.union(setB))
print("## Intersect ##")
print(setA.intersection(setB))
print("## subtraction (A-B)##")
print(setA.difference(setB))
print("## subtraction (B-A)##")
print(setB.difference(setA))
print("## 원형 보존 확인 ##")
print(setA)
print(setB)
<실행 결과>

비파괴적인 방법으로 구현되어있음을 확인할 수 있다.
하지만! 우리의 목표는 자료구조를 손으로 구현해보는 것이기 때문에 직접 코딩해보도록 하겠다.
<파이썬 구현>
# set_list2.py
from array_linked_list import array_linked_list
# 내장메서드와의 겹침 피하기 위해 대문자로 작성
class Set_recursive:
def __init__(self, A, B):
self.A = A
self.B = B
def Union(self, a_idx = 0, b_idx = 0):
max_len = self.A.n + self.B.n
# 클래스 호출
if a_idx == 0 and b_idx == 0:
self.C = array_linked_list()
self.C.initialize(max_len)
if a_idx >= self.A.n and b_idx >= self.B.n:
return self.C
if a_idx >= self.A.n:
self.C.addLast(self.B.get(b_idx))
self.Union(a_idx, b_idx+1)
elif b_idx >= self.B.n:
self.C.addLast(self.A.get(a_idx))
self.Union(a_idx+1, b_idx)
else:
if self.A.get(a_idx) < self.B.get(b_idx):
self.C.addLast(self.A.get(a_idx))
self.Union(a_idx+1, b_idx)
elif self.A.get(a_idx) > self.B.get(b_idx):
self.C.addLast(self.B.get(b_idx))
self.Union(a_idx, b_idx+1)
else:
self.C.addLast(self.A.get(a_idx))
self.Union(a_idx+1, b_idx+1)
return self.C
def Intersect(self, a_idx=0, b_idx=0):
max_len = self.A.n if self.A.n > self.B.n else self.B.n
# 클래스 호출
if a_idx == 0 and b_idx == 0:
self.C = array_linked_list()
self.C.initialize(max_len)
if a_idx >= self.A.n or b_idx >= self.B.n:
return self.C
if self.A.get(a_idx) < self.B.get(b_idx):
self.Intersect(a_idx+1, b_idx)
elif self.A.get(a_idx) > self.B.get(b_idx):
self.Intersect(a_idx, b_idx+1)
else:
self.C.addLast(self.A.get(a_idx))
self.Intersect(a_idx+1, b_idx+1)
return self.C
# set.py
from set_list2 import Set_recursive
from array_linked_list import array_linked_list
# 집합 생성
A = array_linked_list()
A.initialize(6)
B = array_linked_list()
B.initialize(4)
A.addLast('a')
A.addLast('b')
A.addLast('d')
A.addLast('e')
A.addLast('f')
A.addLast('g')
B.addLast('b')
B.addLast('c')
B.addLast('e')
B.addLast('i')
# 클래스 호출 및 실행
U = Set_recursive(A, B)
# 비파괴적 방법으로 메서드 구현했으므로 동시 실행 가능
U.Union().traverse()
print()
print('#' * 10)
U.Intersect().traverse()
<실행 결과>

'알고리즘 > 자료구조_알고리즘' 카테고리의 다른 글
| [자료구조] 07. 큐 (Queue) & 덱 (Dequeue) (3) | 2022.08.29 |
|---|---|
| [자료구조] 06. 스택 (Stack) (1) | 2022.08.25 |
| [자료구조] 04(2). 연결리스트 확장 및 응용 (0) | 2022.08.20 |
| [자료구조] 04(1). 연결리스트 구현 (0) | 2022.08.11 |
| [자료구조] 03. 기초 데이터구조 - 배열, 연결리스트 (0) | 2022.08.05 |



