포스팅을 시작하기 전에
글쓰는게 얼마나 고된 과정이었는지 실감했다... 글 잘쓰는 사람 정말 부럽습니다
최대한 이해하기 쉽게 쓰려고 노력은 하고 있지만 처음으로 써보는 글이다보니 부족한 부분이 스스로도 많이 보인다
피드백은 댓글로 자유롭게 :)
키워드
#실행시간 #의사코드 #데이터구조 #배열 #연결리스트
이번에는 본격적으로 자료구조의 세계를 탐험하기 전 복습 겸 쉬어가는 차원에서 기초 데이터구조에 대해 알아본다.
이미 잘 알고 있는 사람이라면 스킵해도 무관하지만 좀 더 세부적으로 살펴보고자 한 번 다루기로 했다.
1. 데이터구조
후에 다룰 스택, 큐 같은 고급 자료구조형태는 모두 기초 데이터구조를 통해 구현한다.
여기서 말하는 기초 데이터구조는
- 배열
- 연결리스트
아마 C언어나 JAVA와 같은 프로그래밍 언어를 다룬 사람이라면 익숙한 단어일 것이라고 생각한다.
(구현도 많이 해봤을 것이다)
하지만 어떤 일이든 기초가 중요하니까 다뤄봤던 사람이라도 복습차원에서, 다뤄보지 않은 사람은 반드시 알고가야 하는 내용이다!
배열 (array)
배열의 사전적 정의는 다음과 같다.
배열(array)은 번호(인덱스)와 번호에 대응하는 데이터들로 이루어진 자료 구조
인덱스가 붙은 원소들이 일렬로 나열되어 있는 형태이다.
번호는 인덱스(index), 번호에 대응하는 데이터들은 원소(element) 로 지칭한다.
인덱스는 일반적으로 0부터 시작하며 원소는 일반적으로 같은 종류의 데이터 (실수, 정수, 문자 ...) 이다.
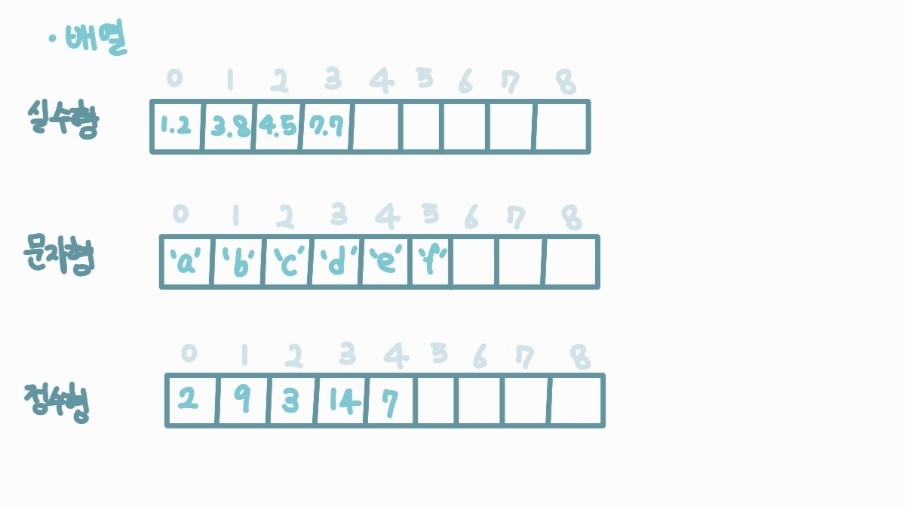
배열의 시간복잡도
- 찾고자 하는 원소의 인덱스를 알 때 : O(1)
- 찾고자 하는 원소의 인덱스를 모를 때 : O(N) // 순차탐색의 경우
- 자료 끝에 원소 추가 (append) : O(1)
- 자료 중간에 원소 추가 (insert) : O(N)
인덱스는 왜 0부터 시작해?
내가 프로그래밍 공부를 시작할 때 가졌던 의문이다.
난 이걸 이해하기 보다는 그냥 수긍(...)하는 방향으로 넘겼지만, 이번 포스팅을 계기로 찾아보았다.
이 부분에 대해서는 굉장히 깔끔하게 포스팅해놓으신 글이 있기에 링크로 대체한다.
글의 내용을 요약하자면, 수의 범위를 표현하기 위한 적절한 표현방법은 [a, b)이며 이 컨벤션을 쓸때는 인덱스를 0부터 시작해야 N으로 깔끔하게 끝난다는 것이다.
https://nanite.tistory.com/56
0부터 시작하는 이유와 마지막 수를 인덱스로 포함하지 않는 이유
"Why numbering should start at zero" 1. 인덱스 넘버링 보통 프로그래밍 언어에는 자료구조로 사상되는 어떤 집합을 순회하면서 그 집합에서 꺼내온 원소를 가지고 정해진 연산을 차례대로 수행하기 위
nanite.tistory.com
배열의 구성요소
- 배열명 (array name, V) : 배열 전체를 지칭
- 배열크기 (array size, N) : 원소를 저장하는 공간(셀)의 개수
- 배열첨자 (array index, i) : 셀의 순위 (상대적 위치)
- 시작첨자 (LB, lower bound) : 일반적으로 0
- 끝첨자 (UB, upper bound) : 일반적으로 크기가 N인 배열에서 N-1
- 배열원소 (array element, V[i]) : 배열 V의 첨자 i에 저장된 원소 (i번째 원소)
- 배열표시 : V[LB..UB]

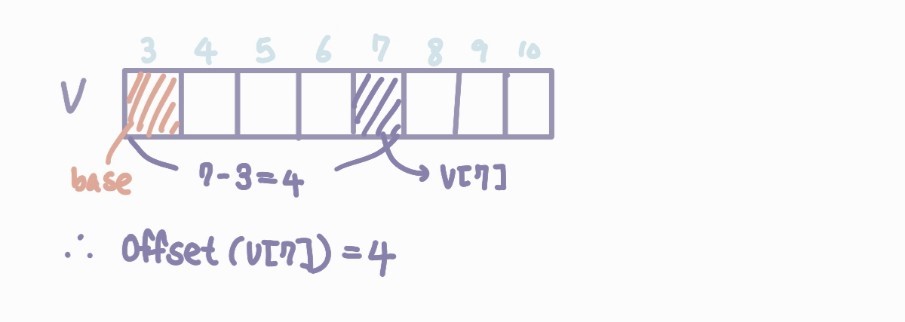
컴파일 시 배열의 셀들은 베이스(=배열의 첫째 셀 위치)부터 차례로 할당되고, 각 셀은 베이스로부터 오프셋만큼 떨어지게 된다.
따라서 V[LB..UB]의 베이스로부터 V[k]의 오프셋은 k-LB이다.
- 예제. V[3..10] 배열을 그리고 V[7]의 오프셋을 구하기
// 1차원 배열 선언 방법 (in C)
// 정적 배열 선언 방법
int arr[length];
// 동적 배열 선언 방법
arr = (int*)malloc(sizeof(int) * length);# 1차원 배열 구현 방법 (in Python)
arr = [0 for range(length)]
정적 배열과 동적 배열이 뭐야?
본인은 1학년 C언어 수업에서 처음 들었던 기억이 난다. 다른 사람들은 언제 어떻게 배웠는지 모르겠지만...
두 개념의 차이점을 알아야 후에 나올 배열과 연결리스트의 차이점을 알 수 있으므로, 개념은 확실히 알고가자!
정적 (static) 할당 : 프로그램 작성 단계에서 메모리 크기가 정해지며, 할당되는 메모리 크기는 프로그램을 실행할 때마다 달라지지 않음
- 작성 단계에서 메모리 크기를 미리 알아야 함
- 정확한 크기를 알 수 없는 경우 충분히 큰 크기를 가정해야 함 -> 메모리 낭비 가능성
- 필요에 따라 실행 단계에서 유연한 변경 불가능 -> 메모리 낭비 가능성
동적 (dynamic) 할당 : 프로그램 실행 단계에서 메모리 크기가 정해지며 상황에 따라 필요한 만큼의 메모리를 할당받을 수 있음
- 필요에 따른 변경 가능
- 사용하지 않는 메모리를 해제하지 않을 경우 댕글링 포인터 발생 가능
댕글링 포인터 :해제된 메모리 영역을 여전히 가리키는 포인터
메모리 접근 시 예측 불가능한 동작을 일으키거나, 잠재적인 보안 위험성이 존재
그러니까 정적 배열은 정적으로 할당한 배열, 동적 배열은 동적으로 할당한 배열이다!
다차원 배열
위에서는 1차원 배열에 대해 다뤄보았다. 그렇다면 다차원 배열은 무엇일까?
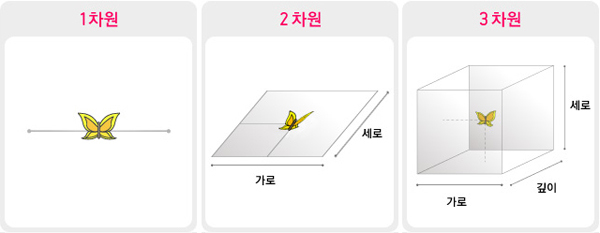
우리가 아는 그 '차원'의 개념 맞다. 이걸 배열 그림으로 다시 나타내면,

따라서 n차원 배열은 n-1차원 배열을 원소로 가지는 배열이라고도 볼 수 있겠다!
3차원 배열은 2차원 배열을, 2차원 배열은 1차원 배열을 원소로 가지는 것을 확인할 수 있다.
2차원 배열 (table)
// 2차원 배열 선언 방법 (in C)
// 정적 할당
int arr[col_length][row_length];
// 동적 할당
/*
int col_length = 4, row_length = 7;
int arr[col_length][row_length];
이런 식으로는 선언할 수 없다!!
*/
int **arr;
arr = (int**) malloc (sizeof(int*) * col_length);
for (int i = 0; i < col_length; i++) {
arr[i] = (int*) malloc (sizeof(int) * row_length);
}# 2차원 배열 구현 (in Python)
arr = [[0]*col_length for i in range(row_length)]
# 2차원 배열 출력
for i in arr :
for j in i:
print(j,end=" ")
print()
행렬 표시 방법은 $$V[LB_1...UB_1, LB_2...UB_2]$$
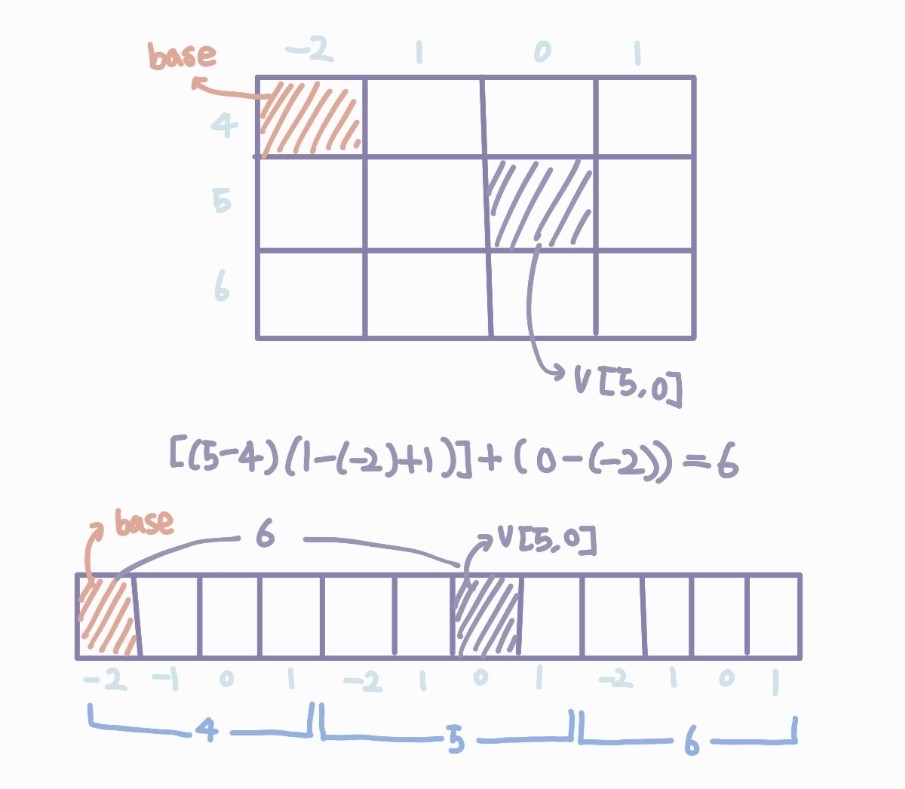
$$V[LB_1...UB_1, LB_2...UB_2]$$의 베이스로부터 V[k1, k2]의 오프셋은 아래와 같다.
$$[(k_1 - LB_1)(UB_2 - LB_2 + 1)] + (k_2 - LB_2) $$
- 예제. V[4..6, -2..1]의 베이스로부터 V[5,0]의 오프셋을 구하기
2차원 이상부터는 직관적인 파악이 힘들다. 이럴땐 1차원으로 펴서 생각하면 쉽게 이해 가능하다!
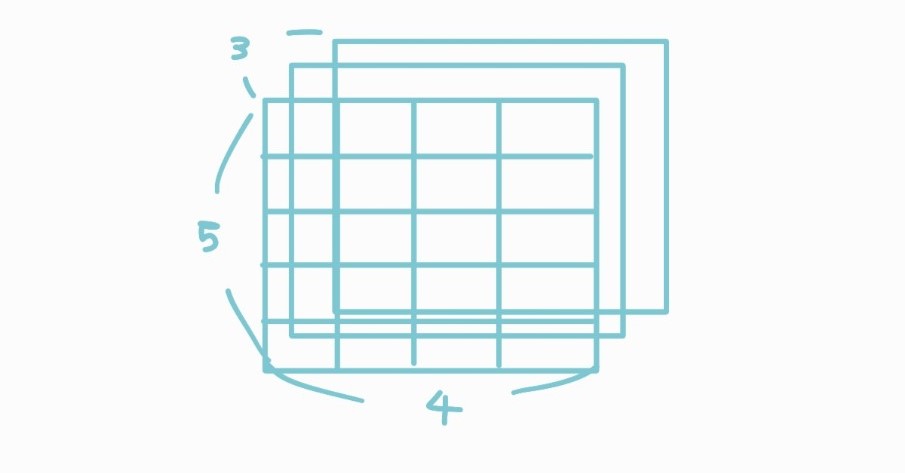
3차원 배열
행렬 표시 방법은 $$V[LB_1...UB_1, LB_2...UB_2, LB_3..UB_3]$$
위에서는 직육면체 형태로 나타냈지만, 2차원 배열을 요소로 가진 배열이라는 것을 강조하기 위해 2차원 배열 여러 개를 겹쳐놓은 형태로 표현하기도 한다.
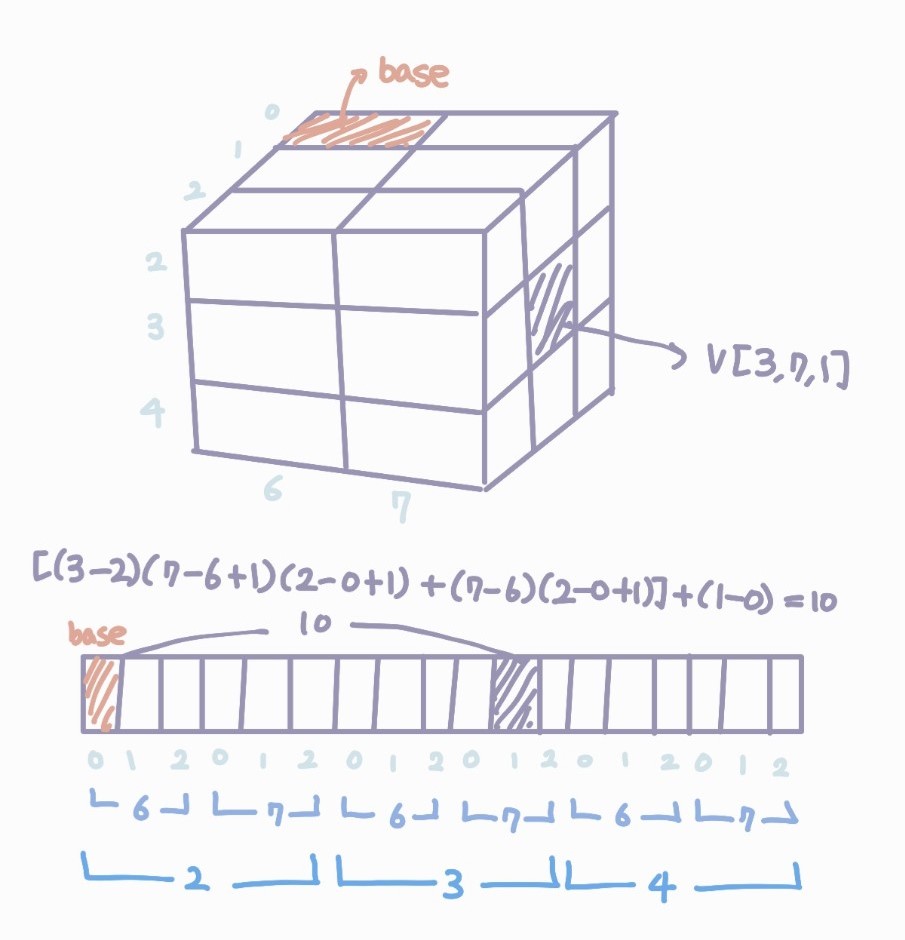
$$V[LB_1...UB_1, LB_2...UB_2, LB_3..UB_3]]$$의 베이스로부터 V[k1, k2, k3]의 오프셋은 아래와 같다.
$$[(k_1 - LB_1)(UB_2 - LB_2 + 1)(UB_3-LB_3+1) + (k_2 - LB_2)(UB_3 - LB_3+1)] + (k_3 - LB_3) $$
- 예제. V[2..4,6..7,0..2]의 베이스로부터 V[3,7,1]의 오프셋을 구하기
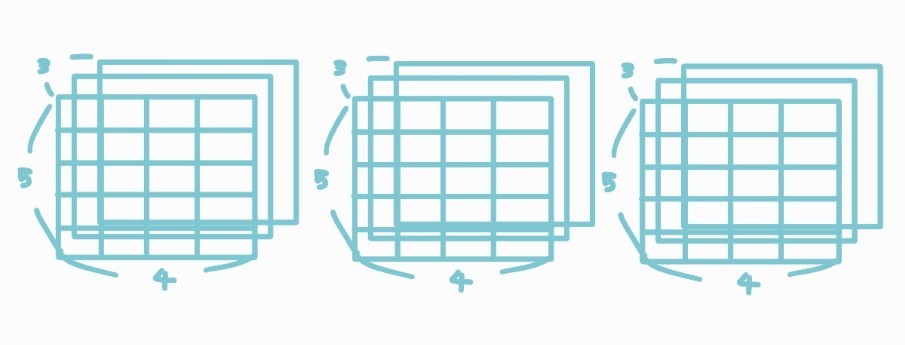
4차원 배열
슬슬 어지럽다.. 3차원 배열을 요소로 가지는 배열이라는 개념만 잡고 넘어가자 (실제로 구현할 일도 거의 없다)
연결리스트 (linked list)
연결리스트의 사전적 정의는 다음과 같다.
각 노드가 데이터와 포인터를 가지고 한 줄로 연결되어 있는 방식으로 데이터를 저장하는 자료 구조이다.
위에서 설명했듯, 정적 배열의 한계를 극복하기 위해 나온 것이 '동적 메모리 구성' 이다.
변수를 바구니라고 두고, 필요할 때마다 바구니에 물건 (데이터) 을 담아 연결한다고 생각해보자.

이를 연결리스트의 사전적 정의로 바꾸면 다음과 같은 형태가 된다.

노드(Node) : 한 개의 데이터 원소를 저장하기 위해 동적 메모리에 할당된 메모리
포인터 (Pointer) : 다음 변수의 주소값을 저장하고 있음

프로그램 실행단계에서 필요할 때마다 변수에 메모리를 할당하고, 액세스가 가능하도록 연결해둔 것이다.
왜 맨 끝에 NULL이 있어?
아까 정적 배열에서는 미리 크기가 정해져있으므로 NULL값을 지정해줄 필요가 없었다.
하지만 동적 배열에서는 언제든 추가/삭제 될 수 있으므로 현재 요소가 몇 개 있는지 즉,
'현재 배열의 끝이 어디인지'를 컴퓨터에게 알려주어야 한다!
(만약 NULL로 지정해주지 않으면 포인터에 쓰레기값이 저장되어 의도한 작동이 이루어지지 않을 것이다)
연결리스트 구성요소
- 연결리스트명 (L) : 연결리스트의 시작 위치 (=첫 노드의 주소)
- 연결리스트 크기 (n) : 연결리스트 내 노드 수
여기서 노드를 연결할 때 쓰인 저 화살표에 주목해보자!
위 그림에서는 화살표가 한쪽 방향 (→)으로 되어있음을 볼 수 있는데, 이는 단방향으로만 순회가 가능하다는 것을 의미하며, 이러한 연결리스트를 단일연결리스트라고 한다.
연결리스트 종류
단일연결리스트, 단순연결리스트 (singly linked lists)

위의 그림처럼 단방향만 순회 가능한 리스트.
연속 노드로 구성된 가장 단순한 연결 데이터 구조이다.
- 원소 (element) : 데이터 원소 (= node)
- 링크 (link) : 다음 노드의 주소 (=pointer)
- 접근점 : 첫 노드 (=헤드노드)의 주소
이중연결리스트 (doubly linked lists)

추가 링크를 사용해 역방향 접근 및 순회가 가능
- 원소 (element) : 데이터 원소
- prev_link : 이전 노드의 주소
- next_link : 다음 노드의 주소
- 접근점 : 첫 노드, 마지막 노드(=테일 노드)의 주소
원형연결리스트 (circularly linked lists)

마지막 노드가 NULL을 가리키는 것이 아닌, 첫 번째 노드의 주소를 가리키게 하는 것
- 원소 (element) : 데이터 원소 (= node)
- 링크 (link) : 다음 노드의 주소 (=pointer)
- 접근점 : 첫 노드 (=헤드노드)의 주소
원형연결리스트의 장점?
원형연결리스트의 장점을 파악하기 위해서는 단일연결리스트에서의 삽입/삭제 방식을 이해해야 한다.
단일연결리스트에서는 리스트의 시작을 가리키는 포인터 변수 head와 리스트의 끝을 가리키는 포인터 변수 tail이 존재한다. 즉, 시작과 끝을 가리키기 위해 head, tail 두 개의 포인터 변수가 존재한다. 하지만 원형 연결리스트의 경우 tail->next == head 이므로 리스트의 시작과 끝에 보다 쉽게 접근할 수 있다.
헤더 및 트레일러 연결리스트 (linked lists with header and trailer)

첫 번째 노드 앞에 헤더 노드 추가, 마지막 노드 뒤에 트레일러 노드를 추가한 방식이다. 이렇게 하면 첫 번째 노드, 마지막 노드도 중간 노드와 추가/삭제방식이 같아져 일반화가 가능해진다.
- 원소 (element) : 데이터 원소 (= node)
- 헤더 노드 : 헤드 노드 앞에 추가되는 특별한 노드
- 트레일러 노드 : 테일 노드 뒤에 추가되는 특별한 노드
- 링크 (link) : 다음 노드의 주소 (=pointer)
- 접근점 : 첫 노드 (=헤드노드)의 주소
또한 이를 융합한 리스트 형태도 존재한다.
- 원형 헤더연결리스트 (circular header linked lists)

- 원형 이중연결리스트 (circular doubly linked lists)

- 헤더 및 트레일러 이중연결리스트

- 헤더 및 트레일러 원형이중연결리스트

자세한 구현 방법은 이후 고급 자료구조를 구현하면서 알아보도록 하겠다!
'알고리즘 > 자료구조_알고리즘' 카테고리의 다른 글
| [자료구조] 05. 집합 (0) | 2022.08.25 |
|---|---|
| [자료구조] 04(2). 연결리스트 확장 및 응용 (0) | 2022.08.20 |
| [자료구조] 04(1). 연결리스트 구현 (0) | 2022.08.11 |
| [자료구조] 02. 재귀 (0) | 2022.08.04 |
| [자료구조] 01. 알고리즘 분석 (1) | 2022.08.03 |



