포스팅을 시작하기 전에
수업 내용에서 배운 내용을 바탕으로 복습하면서 추가적인 정보를 찾아보고, 관련 문제를 풀어보는 것이 이 포스팅 시리즈의 주 목적이다.
키워드
#실행시간 #의사코드 #원시작업 #빅오
1. 실행시간
대부분의 알고리즘은 입력을 출력으로 변환하며, 알고리즘의 실행시간(running time)은 대체로 입력의 크기와 함께 성장한다.
최상 실행시간 (best case running time)
프로그램 실행시간의 하한을 계산한다.
프로그램을 실행할 때 연산이 수행되는 횟수가 최소가 되는 경우 (= 알고리즘이 수행하는 가장 짧은 실행 시간)
하지만 실질적 사용에 있어서 실행시간의 하한 측정은 무의미하기에 거의 사용되지 않는다.
ex) 선형탐색에서 탐색할 요소가 목록의 첫 번째에 존재할 경우
평균 실행시간 (average case running time)
가능한 모든 입력에 대해 실행 시간을 계산해 총합을 구하고 입력 수로 나눈다.
일반적으로 효율적인 알고리즘 비교에는 최악 실행시간이 사용되지만, 다음과 같은 세 가지 경우 평균 실행시간이 사용된다.
- 일부 문제는 최악의 경우 처리하기 어려울 수 있지만, 이러한 동작을 유발하는 입력이 실제로 거의 발생하지 않으므로 평균 복잡성이 더 정확할 수 있음.
"작은" 수의 입력에 대해 비효율적인 알고리즘은 실제로 발생하는 "대부분"의 입력에 대해 효율적일 수 있다
- 암호화 및 무작위화 같은 영역에서 사용할 수 있는 어려운 문제 인스턴스를 생성하는 도구 및 기술 제공
- 동등한 최상 케이스 복잡성의 알고리즘 중 실제로 가장 효율적인 알고리즘을 구별할 수 있도록 함
그러나 종종 결정하기 어려울 수 있다.
ex) 선형탐색에서 탐색할 요소가 목록의 1~n-1번째에 존재할 경우
최악 실행시간 (worst case running time)
프로그램 실행 시간의 상한을 계산한다.
프로그램을 실행할 때 연산이 수행되는 횟수가 최대가 되는 경우 (= 알고리즘이 수행하는 가장 긴 실행 시간)
따라서 알고리즘이 지정된 시간 내에 완료됨을 보장하며, 일반적인 알고리즘 비교에 사용된다.
- 분석이 비교적 용이
- 게임, 재정, 로봇 등의 응용에서 결정적인 요소
ex) 선형탐색에서 탐색할 요소가 목록의 n번째에 존재할 경우
평균 실행시간 VS 최악 실행시간
- 최악 실행시간 분석은 "안전한" 분석을 제공하지만 지나치게 비관적일 수 있다. 최악의 입력이 들어가는 실질적인 경우가 거의 없을 수 있기 때문이다.
- 평균 실행시간 분석에서는 일반적인 입력이 무엇을 의미하는지 결정하기 어려울 수 있으며, 그 평균 입력에는 수학적으로 특성화하기 어려운 속성이 존재할 수 있다.
최악의 경우와 평균적인 경우의 분석 사이 간극을 메우기 위한 학술 이론인 평활 분석 (smoothed analysis) 도 존재한다.
평활분석 : 최악 분석과 평균 분석의 장점을 상속하는 혼합형. 보다 현실적인 분석을 제공한다.
https://arxiv.org/abs/1711.05667
그래서 실행시간을 어떻게 구하는데?
실험적 방법
알고리즘을 구현하는 프로그램을 작성하고, 시스템콜을 사용해 실제 실행시간을 정확히 측정해 결과를 도표로 작성한다.
[예제 1] 1부터 100까지의 정수 중 하나를 입력받아 1~100 정수가 저장된 리스트에서의 선형 탐색을 수행하고, 실행시간을 출력해라.
[Python 3]
import time
from datetime import timedelta
target = int(input()) # 목표 정수
numbers = [x for x in range(101)]
start = time.process_time()
for j in range(len(numbers)):
if numbers[j] == target:
print("target find")
break
if j >= len(numbers):
print("target not found")
end = time.process_time()
print("Time elapsed: ", end - start) # seconds
print("Time elapsed: ", timedelta(seconds=end-start))
[예제 2] 1~100사이의 정수 10개가 랜덤 순서로 들어있는 리스트를 삽입정렬하고 결과를 출력하라.
삽입정렬은 추후 알고리즘 포스팅에서 다룰 계획이다.
import time
from datetime import timedelta
import random
start = time.process_time()
#Insertion Sort
def Insertion_Sort(array):
for a in range(1, len(array)):
for b in range(a, 0, -1):
if array[b] < array[b-1]:
array[b], array[b-1] = array[b-1], array[b]
else:
break
return array
array = random.sample(range(100), 10)
print(array)
print(Insertion_Sort(array))
end = time.process_time()
print("Time elapsed: ", end - start) # seconds
print("Time elapsed: ", timedelta(seconds=end-start))
그러나 실험적 방법은 다음과 같은 한계점을 가지고 있다.
- 실험에 포함되지 않은 입력에 대한 실행시간이 반영되지 않을 수 있다
- 알고리즘 비교를 위해 반드시 동일한 하드웨어와 소프트웨어 환경이 사용되어야 한다
- 알고리즘을 완전한 프로그램으로 구현해야만 비교가 가능하다
이론적 방법
이론적 방법에서는 모든 입력 가능성을 고려하며, 하드웨어 & 소프트웨어와 무관하게 속도를 평가할 수 있다.
또한 실제 구현한 프로그램 대신 의사코드로 표현된 알고리즘을 사용한다.
2. 의사코드 (pseudo-code)
알고리즘을 설명하기 위한 고급 언어
인간에게 읽히기 위해 작성되었으며 컴퓨터 언어가 아니다!
실제로 컴퓨터에서 실행할 수 없으며, 알고리즘을 대략적으로 모델링하거나 설명할 때 쓰인다.
// C 스타일 의사코드
void function fizzbuzz
For (i = 1; i<=100; i++) {
set print_number to true;
If i is divisible by 3
print "Fizz";
set print_number to false;
If i is divisible by 5
print "Buzz";
set print_number to false;
If print_number, print i;
print a newline;
}출처 : https://ko.wikipedia.org/wiki/%EC%9D%98%EC%82%AC%EC%BD%94%EB%93%9C
Alg arrayMax(A, n)
input array A of n integers
output maximum element of A
currentMax <- A[0]
for i <- 1 to n-1
if (A[i] > currentMax)
currentMax <- A[i]
return currentMax자연어 문장보다 더 구조적이지만, 실제 프로그래밍 언어보다는 덜 상세하다는 특징을 가지고 있다.
의사코드 문법
의사코드 문법은 스타일에 따라 다름!
수업시간에 배운 내용만 간단히 정리해보자.
- 제어 (control fow)
// if 조건문
if (exp) ...
[else if (exp) ... ]
[else ...]
// for 반복문
for var <- exp_1 to exp2
...
for each var \in exp
...
// while 반복문
while (exp)
...
do
...
while (exp)들여쓰기로 범위를 정의하는 것에 주의할 것!
- 연산
<- : 치환
=, <, <=, >, >= : 관계 연산자
&, |, ! : 논리 연산자
- 메소드 정의, 반환, 호출
Alg method_name (arg)
...
return exp
method(arg)- 주석
input ... output ...
3. 원시작업
알고리즘에 의해 수행되는 기본적인 계산들
- 산술식/논리식 평가 (EXP)
- 변수에 특정값 치환 (ASS)
- 배열 원소 접근 (IND)
- 메소드 호출 (CAL)
- 메소드로부터 반환 (RET)
의사코드에서 쉽게 식별할 수 있으며 프로그래밍 언어와 대체로 독립적이다.
어떻게 쓰일까?
알고리즘에 의해 실행되는 기본 작업의 최대 수를 결정할 수 있다!
즉 의사코드에서의 원시 작업 수행 과정을 살펴보면, 이론적인 실행 시간을 구할 수 있다.
그래서 예시를 살펴봤는데... 수업시간에 나온 예제랑 구글링한게 약간 다르다
하지만 이게 중요하지 않다는걸 밑 내용에서 살펴볼 수 있다!
Alg arrayMax(A, n)
input array A of n integers
output maximum element of AcurrentMax <- A[0]
for i <- 1 to n-1 do
if (A[i] > currentMax)
currentMax <- A[i]
{increment counter i}
return currentMax1. [IND, ASS] 2 // 배열 접근, 변수 할당
2. [ASS, EXP] 2 * n
for (i=1; i<n; i++)
// 배열 접근, i < n 비교
3. [IND, EXP] 2*(n-1) // 배열 접근, 비교식
4. [IND, ASS] 2*(n-1) // 배열 접근, 변수 할당
5. [EXP, ASS] 2*(n-1)
i = i + 1
// 연산식, 변수 할당
6. [RET] 1 // 숫자 반환
total : 2 + 2n + 6(n-1) + 1 = 8n - 3
https://www.cpp.edu/~ftang/courses/CS240/lectures/analysis.htm
여기서 나온 arrayMax 함수는 최악의 경우 8n-3의 원시작업을 실행한다.
| a | 가장 빠른 원시작업 실행에 걸리는 시간 |
| b | 가장 느린 원시작업 실행에 걸리는 시간 |
| T(n) | arrayMax의 최악실행시간 |
$$ a(8n-3) <= T(n) <= b(8n-3) $$
하드웨어, 소프트웨어 환경을 변경한다면?
T(n)에 상수배만큼의 영향을 주지만, 증가율을 변경하진 않는다.
즉 실행시간 T(n)이 arrayMax의 고유 속성이다!
4. 빅오 표기법
빅오 표기법은 함수 증가율의 상한(upper bound)을 나타낸다.
다시말해, $$f(n) = O(g(n))$$ 수식에서 f(n)의 증가율은 g(n)의 증가율을 넘지 않는다.
= f(n)의 성장률이 g(n)의 성장률 이하이다.
정의를 살펴보자.
| 주어진 두 개의 함수 f(n)과 g(n)에 관해, 만약 모든 정수 n >= n_0 에 대해 f(n) <= c*g(n)가 성립하는 실수의 상수 c>0 및 정수의 상수 n_0 >= 1가 존재하면 "f(n) = O(g(n))" 이라고 말한다. |
예시. f(n) = 2n+10 은 O(n)이다
모든 정수 n>=n_0 에 대해 2n+10 <= cn이 되도록 실수 상수 c>0 과 정수 상수 n_0>=1을 찾기
2n + 10 <= cn
(c-2)n >= 10
n >= 10/(c-2)
-> c = 3, n_0 = 10일 때 성립함, 따라서 f(n) = 2n+10 은 O(n)이다.
예시 2. f(n) = 8n-2 는 O(n)이다
모든 정수 n>=n_0 에 대해 8n-2 <= cn이 되도록 실수 상수 c>0 과 정수 상수 n_0>=1을 찾기
8n-2 <= cn
(c-8)n >= -2
n >= -2/(c-8)
-> c = 8, n_0 = 1일 때 성립함, 따라서 f(n) = 8n - 2는 O(n)이다.
예시 3. f(n) = n^2 는 O(n)이다
모든 정수 n>=n_0 에 대해 n^2 <= cn이 되도록 실수 상수 c>0 과 정수 상수 n_0>=1을 찾기
n^2 <= cn
n <= c
-> c가 상수여야 하므로 부등식이 성립할 수 없다.
예시 4. f(n) = 5n^4 + 3n^3 + 2n^2 + 4n + 1 은 O(n^4)이다
(c = 15, n_0 = 1)
5n^4 + 3n^3 + 2n^2 + 4n + 1 <= (5+3+2+4+1)n^4 = cn^4
| f(n)이 차수 d의 다항식, 즉 f(n) = a_0 + a_1n + a_2(n^2) + ... + a_d (n^d) 이고 a_d > 0이면 f(n)은 O(n^d)이다. |
n >= 1의 경우 1 <= n <= n^2 ... <= n^d
따라서 f(n) = a_0 + a_1n + a_2(n^2) + ... + a_d (n^d) <= (a_0 + a_1 + ... a_d) n^d
f(n) = O(n^d)
정의로 보니까 어렵다...
쉽게 말해서, 최고차항만 남기고 최고차항 앞의 계수를 없애서 표기하면 된다!
- f(n)이 상수이면 f(n) = O(1)
- f(n)이 차수 d의 다항식이면, f(n) = O(n^d)
O(3n) = O(n)
O(7n^2) = O(n^2)
실행시간 : O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(2^n)
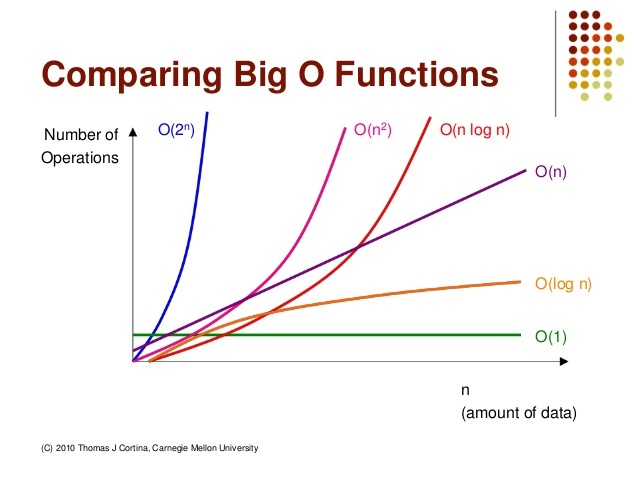
5. 점근분석 (asymptotic analysis)
- 최악의 원시작업 실행횟수를 입력 크기 함수로써 구한다
- 이 함수를 빅오 표기법으로 나타낸다
위에서 썼던 arrayMax 함수를 예시로 들어보자.
- arrayMax의 원시작업 횟수 8n - 3 을 구함
- f(n) = 8n - 3 = O(n)
상수 계수와 낮은 차수 항들은 결국 탈락되므로, 원시작업 수 계산할 때부터 무시 가능!
분석 예시
sum <- sum + (salary + bonus) * (1-tax) // O(1)
// O(n)
for i <- 1 to n
k <- k + 1
sum <- sum + i
// O(n^2)
for i <- 1 to n
for j <- 1 to n
k <- k + 1
// O(n)
if (k = 0)
return
else
for i <- 1 to n
j <- j + 1
6. 다른 점근표기법
- 빅오 (Big-Oh)
점근적으로 f(n) <= g(n), f(n) = O(g(n))
함수 증가율의 상한을 나타냄 [최악 실행시간]
- 빅오메가 (Big-Omega)
점근적으로 f(n) >= g(n), f(n) = Ω(g(n))
함수 증가율의 하한을 나타냄 [최상 실행시간]
- 빅세타 (Big-Theta)
점근적으로 f(n) = g(n), f(n) = Θ(g(n))
증가율의 상한과 하한을 모두 나타내므로 동일 함수를 나타냄 [평균 실행시간]
자주 쓰이는 점근 표기법은 빅오와 빅세타이다. (그 이유는 윗 문단을 살펴보면 알 수 있을 것이다)
'알고리즘 > 자료구조_알고리즘' 카테고리의 다른 글
| [자료구조] 05. 집합 (0) | 2022.08.25 |
|---|---|
| [자료구조] 04(2). 연결리스트 확장 및 응용 (0) | 2022.08.20 |
| [자료구조] 04(1). 연결리스트 구현 (0) | 2022.08.11 |
| [자료구조] 03. 기초 데이터구조 - 배열, 연결리스트 (0) | 2022.08.05 |
| [자료구조] 02. 재귀 (0) | 2022.08.04 |



