GPT-4와 맞먹는 강력한 성능의 오픈소스 Evaluator
Abstract
최근에는 long-form response를 평가하기 위한 Evaluator로 GPT-4와 같은 강력한 LLM을 사용하는 것이 사실상 표준이 되었다. 그러나 GPT-4는 대규모 스케일의 평가를 진행하거나, 다양한 사용자 정의 기준 (ex. child-readability) 을 고려하려면 부적절한 선택지일 수 있다.
본 논문에서는 reference answer, score rubric 이 제공될 경우 GPT-4의 evaluate 성능과 동등한 수준을 보이는 open-source LLM Prometheus를 소개한다.
먼저 아래의 구성 요소들로 이루어진 Feedback Collection dataset을 구축한다.
- fine-grained score rubrics (1K)
- instructions (20K)
- responses and language feedback generated by GPT-4 (100K)
이를 사용해서 사용자가 제공한 rubrics를 기반으로 긴 형식의 텍스트를 평가할 수 있는 13B evaluator LLM Prometheus 를 훈련한다.
실험 결과 Prometheus는 Human Evaluator와 0.897의 피어슨 상관계수를 기록하였다. 이는 GPT-4 (0.882) 와 비슷한 수준이고, ChatGPT (0.392) 를 크게 능가하는 수치이다.
또한 4개의 벤치마크 (MT Bench, Vicuna Bench, Feedback Bench, Flask Eval) 에 걸쳐 1222개의 instances로 평가한 결과도 GPT-4의 평가 결과와 높은 상관관계를 보여, Evaluator로써 Prometheus의 성능을 입증할 수 있었다.
마지막으로 2개의 인간 선호도 밴치마크 (HHH Alignment, MT Bench Human Judgement) 에서 인간 선호도 데이터셋에 대해 명시적으로 학습된 open-sourced reward models와 비교해서 가장 높은 정확도를 달성함으로써 universal reward model로써의 잠재력을 강조했다.
1. Introduction
텍스트의 미묘한 문맥적 차이를 파악하고 신뢰도 있는 결과를 얻기 위해, 현재까지는 Human evaluation이 주로 쓰였다. 일반적인 자동 평가지표 (BLEU, ROUGE ..) 로는 Human evaluation만큼의 세분화되고 깊이 있는 평가를 얻을 수 없다.
최근에는 LLM, 특히 성능이 월등한 GPT-4를 evaluator로 적용하는 것이 상당한 주목을 받고 있다. 특히 적절한 프롬프트가 주어지면, 인간에 맞먹는 정교한 평가를 내릴 수 있는 것으로 나타났다.
GPT를 통한 Evaluation이 궁금하다면?
[논문 Review] 11. G-EVAL : NLG Evaluation using GPT-4 with Better Human Alignmen
GPT-4를 사용해서 NLG system을 정량적 평가해보자!AbstractNLG는 정량적으로 측정하기 어렵다. 특히 창의성이나 다양성이 요구되는 작업의 경우 BLEU, ROUGE와 같은 기존의 지표는 사람의 판단과 상대적
ll2ll.tistory.com
하지만 몇 가지 중요한 단점이 존재한다.
- Closed-source Nature
독점적인 특성으로 인해서 내부적인 동작 과정이 공개되지 않아 투명성 문제가 제기된다.
또한 학계의 핵심 원칙인 공정한 평가가 영리 단체의 통제 하에 놓이게 되며, 이는 중립성과 자율성에 대한 우려를 불러 일으킨다. - Uncontrolled Versioning
독점 모델은 사용자의 권한 및 통제를 벗어난 버전 업데이트를 거치기 때문에 재현성 문제가 발생한다. 특정 버전의 모델에 의존하게 된다면, 연구 결과의 신뢰성이 약화될 수 있다. - Prohibitive Costs
1000개의 instances를 GPT-4를 사용해서 4가지 크기 (7B ~ 65B 범위) 의 LLM 4개를 평가하는 데만 해도 2000달러 이상의 비용이 들 수 있다. 한정된 예산 안에서는 실험을 진행하기 매우 힘들 수 있다.

하지만 이러한 한계에도 불구하고 GPT-4는 상세한 사용자 정의 평가지표 (=User-defined score rubric) 를 바탕으로 점수를 평가할 수 있다는 너무나 큰 장점이 존재한다.

특히 실제 사용자가 시나리오에서 사용할 때는, "어떤 LLM이 장난스럽고 유머러스한 답변을 생성하는지", "어떤 LLM이 문화적 민감성을 특별해서 답하는지" 등의 customized score rubric에 관심을 가질 수 있다.
그러나 가장 큰 open-source LLM (70B) 으로 테스트했을 때조차 GPT-4에 비해 성능이 많이 떨어졌다.
이를 개선하기 위해 재현 가능한 open-source LM인 Prometheus를 제안한다.
일반적인 평가 지표와 달리, 사용자 정의 점수를 사용해 실제적이고 다양한 평가 선호도에 유연하게 일반화할 수 있도록 모델을 훈련한다. 또한 세분화된 평가 능력을 효과적으로 유도하기 위해 다양한 참고 자료, 특히 "Reference Answers" 를 포함시키는 것이 중요하다.

위 그림대로 구성한 Feedback Collection을 사용해 LLaMA-2-Chat-13B를 Fine-tuning한다.
실험 결과 45개의 customized score rubric에서 Prometheus는 Human Evaluator와 높은 피어슨 상관관계를 얻었다.
또한 GPT-4의 평가와 상관관계를 측정한 결과, GPT-3.5-turbo나 LLaMA-2-Chat에 비해 높은 상관관계를 보였다. 마지막으로 인간 선호도 데이터셋에서도 SOTA reward model과 GPT-3.5-turbo를 앞지르며 잠재력을 입증했다.
3. The feedback collection dataset
이전 연구1에서 feedback에 대한 finetuning을 진행하는 것이 evaluator로써의 LM 성능을 개선하는 데 효과적이라는 것이 입증되었으나, 이 때 사용되었던 데이터셋은 LM을 fine-grained evaluator로 기능하는 데에 적용하기에는 적합하지 않다.
따라서 Open-source evaluator LLM을 fine-tuning하기 위한 목적으로만 사용되는 새로운 데이터셋 Feedback Collection을 구성했다.
구성 방식은 아래와 같다.
- 가능한 많은 참고자료 (reference answer, scoring rubric) 포함
- 길이 편향 방지를 위해 각 점수 (1~5점) 에 대한 reference answer의 길이를 균일하게 유지
- 의사 결정 편향 방지를 위해 균일한 점수 분포 유지
- 사용자가 LLM과 상호작용하는 현실적인 상황으로 instruction, response 범위를 제한
이를 고려해 Feedback Collection 내의 각 instance는 다음과 같이 구성된다.
- input
- instruction : 사용자가 답변을 얻기 위해 target LLM에 넣는 프롬프트
- response to evaluate : evaluator LLM이 평가해야 하는, target LLM이 출력한 instruction에 대한 응답
- customized score rubric : 사용자가 결정한 새로운 평가 기준. Evaluator는 평가 시 여기에 중점을 두어야 함
- a description of the criteria
- a description of each scoring decision (1~5)
- reference answer : 5점을 받을 수 있는 참조 답안. 평가자가 reference answer - response 사이의 상호 정보를 사용해서 채점할 수 있도록 함
- output
- feedback : 답변이 특정 점수를 받는 이유에 대한 근거
- score : 답변에 대한 1~5 사이의 정수 점수

1000개의 score rubric에 대해 20개의 instruction이 첨부되어 있으므로 전체 개수는 20K
또한 각 instruction에 대해 1~5점의 response, feedback이 있으므로 총 개수는 100K
Feedback collection 데이터셋에 대한 세부 분석
Score criteria가 충분히 다양한가?
전체 score rubrics 중 2개를 랜덤 추출하여, 추출된 instances score criteria 사이의 rouge-L 값을 측정하고 플롯팅했다.

결과적으로 많이 겹치지 않았기에, score criteria가 충분히 다양한 것을 알 수 있다.
Score descriptions가 잘 작성되어 있는가?
겉으로 보기에만 좋은 답변에 5점을 주거나, 사소한 사항을 빼먹어서 1점을 줘버리는 경우를 방지하고 찾아내기 위해 "왜 그렇게 점수를 매겼는지"를 설명하는 description도 굉장히 중요하다.
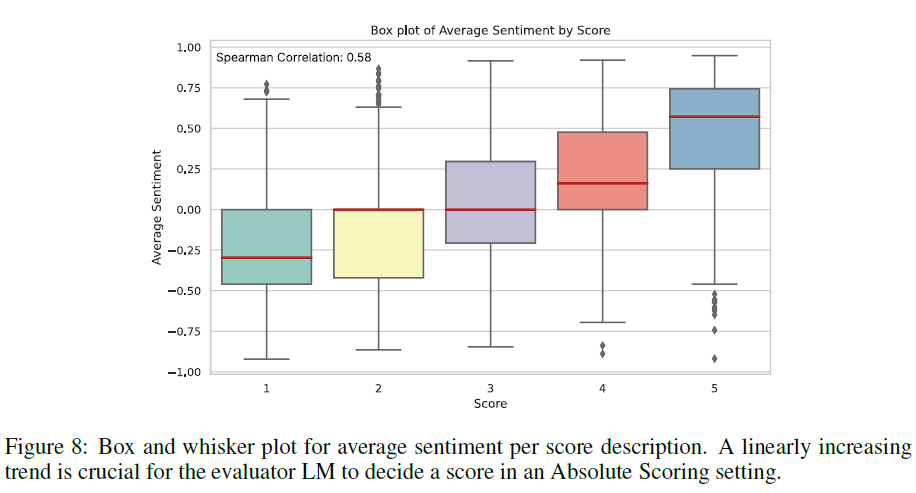
그림 8에서 점수 설명에 따른 average sentiment가 선형적으로 증가하는 것을 볼 수 있었다.
응답에 길이 편향이 있는가?
이전 연구에서 LM을 평가자로 사용할 경우 응답 길이가 길수록 더 높은 점수를 주는 경향이 있는 것으로 나타났다.
Prometheus를 Fine-tuning하는 동안 이러한 편향을 최소화하기 위해, 각 점수별 답변의 길이 분포를 동일하게 유지했다.

Feedback collection 내의 대부분 응답은 비슷한 길이를 유지했다.
또한 각 데이터셋 (Seen/Unseen rubric testset, Vicuna) 에서 답변 길이에 따른 GPT-4, Prometheus 의 선호도를 평가해서 플롯팅하기도 했다.


Instructions, Responses, Feedback도 다양한가?
score rubric과 responses 외에도 Instructions, Responses, Feedback이 다양한지 분석하기 위해, bi-gram과 tri-gram 비율을 조사한다.
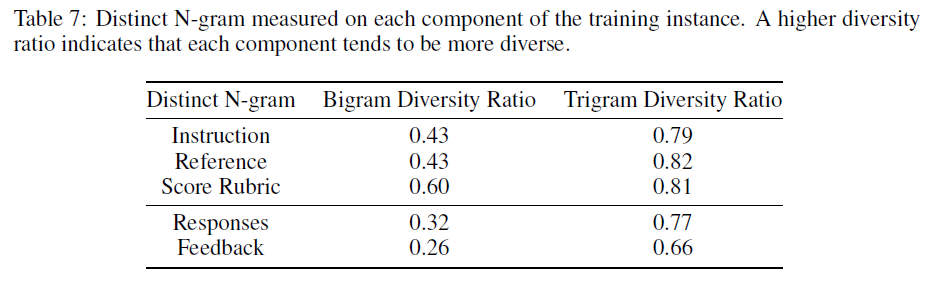
일부 용어가 반복되기는 하지만, 대부분의 경우 용어를 표현하는 방식이 다양한 것을 알 수 있었다.
3.1 Dataset construction process

- Creation of the Seed Rubrics
scroring rubrics의 초기 시드 데이터셋을 만드는 것부터 시작한다.
사람이 직접 담당자의 LLM 결과물을 평가하는 데 중추적인 역할을 하는 세분화된 scoring rubrics를 큐레이팅한다.
이렇게 하면 50개의 seed rubrics로 구성된 초기 배치가 생성된다. - GPT-4를 통해 1K개의 새로운 score rubric으로 확장
1에서 만든 50개의 seed rubrics를 GPT-4를 활용해 더욱 강력하고 다양한 1000개의 scoring rubrics로 확장한다.
특히 초기 시드에서 4개의 무작위 rubrics를 샘플링 해 ICL을 위한 데모로 사용하고, GPT-4가 새로운 score rubric을 브레인스토밍하도록 유도한다.
또한 Prometheus가 다른 어휘를 사용하는 유사한 score rubric으로 일반화할 수 있도록, 새로 생성된 rubric을 의역하게 GPT-4에 요청한다. 이러한 브레인스토밍 -> 의역 과정을 10회 반복한다.
ICL?
더보기= In-context learning
프롬프트 내의 맥락적인 의미를 모델이 이해하고, 이에 대한 답변을 생성하는 것을 의미함
자세한 건 GPT, GPT-2 포스팅에~
- GPT : https://ll2ll.tistory.com/24
- GPT-2 : https://ll2ll.tistory.com/30
사용된 프롬프트
- score rubrics와 관련된 instruction 만들기
1000개의 rubrics에 대해서 적절한 instances를 만드는 과정이다.
예를 들어, "상사에게 보낼 수 있을만큼 공식적인가?" 를 묻는 score rubric은 "수학 문제를 푸는 것" 과는 관련이 없다. 학습을 위해서는 score rubric과 관련성이 높은 instruction이 필요하기 때문에, GPT-4에 score rubric 을 제공하며 이와 관련성이 높은 고유한 instructions를 생성하도록 요청했다.
사용된 프롬프트
- 나머지 요소(responses including the reference answers, feedback, and scores) 증강
마지막으로 GPT-4에 1~5 점 사이 점수를 받을 각 구성 요소를 생성하라는 프롬프트를 넣어 각 score rubric에 대한 20개의 instructions와 5개의 responses & feedback을 생성한다.
Evaluator LM을 finetuning 할 때, 결정 편향을 제거하기 위해 각 score별로 동일한 응답 개수를 생성했다.
사용된 프롬프트
더보기
reference answer의 문장 길이를 프롬프트 내의 {SENT_NUM}에 추가해서 문장 길이를 일정하게 만든다.



3.2 Fine-tuning an Evaluator LM
Feedback collection을 사용해 Llama-2-Chat (7B&13B) 를 Fine-tuning해서 Prometheus를 얻어낸다.
이 때 CoT 기법과 같이, feedback을 순차적으로 생성한 다음 score를 생성하도록 finetuning한다.
훈련과 추론에는 Meta AI에서 공개한 공식 Llama2 코드를 사용했으며, 사용한 하이퍼파라미터는 아래와 같다.


tempearture를 낮게 설정할 경우에는 Evaluator LM이 의미있는 피드백을 생성할 수 없었다.
4. Experimental Setting
4.1 List of experiments and metrics
Absolute Grading (절대 평가)
instruction, response to evaluate, reference가 주어지면 Evaluator LM은 1~5점 범위 내에서 feedback & score를 생성해야 한다.
절대 평가 세팅에서는 비교할 상대가 없고 오직 내부 인자로만 점수가 제공되어야 하기 때문에, 오히려 랭킹 평가보다 어렵다. 하지만 평가를 진행할 때 비교할 상대를 준비할 필요가 없기 때문에 사용자에게는 더 실용적이다.
절대 평가 세팅에서는 아래 3가지의 실험을 진행했다.
- Human evaluation을 사용한 feedback 품질 비교
- prometheus, gpt-3.5-turbo, gpt-4에서 생성된 Feedback을 한 쌍으로 묶어 Human evaluator가 어느 것이 더 품질이 좋은지를 평가하는 방식
- 총 9명의 작업자가 진행
- (prometheus, GPT-4), (prometheus, ChatGPT), (GPT-4, ChatGPT) 쌍으로 묶어서 진행
- Human Evaluator는 총 3가지의 질문에 답변을 진행
주어진 score rubric에 따라 응답에 몇 점을 줄 것인지 / 2개의 Feedback 중 주어진 응답을 평가하는 데 더 좋은 Feedback은 무엇인지 / 특정 feedback을 거부한 이유는 무엇인지
- Human evaluation와의 상관관계, GPT-4 Evaluation과의 상관관계 측정
- Pearson, Kdendall-Tau, Spearman 사용
- 아래 4개의 벤치마크를 사용하여 상관관계 측정
- Feedback bench : 1K개의 feedback collection instance (1 instruction / 1 score rubric)
- Seen rubric : feedback collection train set
- Unseen rubric : train set과 다른 50개의 score rubric으로 구성. instruction 및 하위 집합은 동일한 과정으로 생성됨
- Vicuna bench : Vicuna의 80개 test prompt set을 가져오고, 각 test prompt에 대한 맞춤형 score rubric을 제작한다. 만들어진 score rubric과 instruction을 concat해서 GPT-4에 프롬프트로 넣어 reference answer를 얻는 방식으로 데이터셋을 제작했다.
- MT Bench : multi-turn instruction dataset인 MT Bench의 80개 test prompt set을 가져와서 Vicuna bench와 같은 방식으로 데이터셋을 제작했다. evaluation을 위해서 이 데이터셋의 마지막 턴만 사용했고, 이전 대화는 Evaluator LM에게 입력으로 제공되었다.
- FLASK Eval : 기존의 여러 NLP 데이터셋과 instruction dataset을 포함하는 FLASK에서 200개 test prompt set을 가져왔고, Feedback collection score rubric에 비해 상대적으로 덜 세분화된 12개의 score rubrics (ex. Logical Thinking, Background Knowledge, Problem Handling, and User Alignment) 를 사용했다.
Ranking Grading
절대 평가 세팅에서만 훈련된 Evaluator LM이 보편적인 reward model로 활용될 수 있는지 테스트하기 위해 기존의 인간 선호도 벤치마크를 사용하고, accuracy를 측정 지표로 사용했다.
즉, Evaluator LM이 인간 평가자가 선호하는 응답에 더 높은 점수를 주는지 여부를 확인하는 것이다.
절대 평가 세팅에서는 두 후보에 대해 동일한 점수를 줄 수 있기 때문에, temperature 1.0으로 두고 승자가 나올 때까지 평가를 반복한다.
이는 다른 ranking model에 비해 공정하지 않을 수 있으나, 절대 평가 세팅에서 훈련된 LM이 랭킹 평가 세팅에서도 일반화할 수 있는지 확인하기 위한 목적으로만 수행된다.
- MT Bench Human Judgement: 앞에서 사용된 MT Bench의 또 다른 버전. 이 데이터셋은 동점 (무승부) 인 경우도 포함하고 있기 때문에 반복적인 추론을 필요로 하지 않음
- HHH Alignment : 2개의 응답 중 Helpfulness, Harmlessness, Honesty, and in General (Other) 의 preference accuracy를 측정하는 데이터셋
4.2 Baseline
실험에서 비교를 위해 사용한 모델 목록이다.
- LLAMA2-CHAT-{7,13,70}B : prometheus의 기본 모델
- LLAMA-2-CHAT-13B + COARSE: 선행 연구 데이터셋 (FLASK-EVAL) 의 덜 세분화된 rubric (12개) 만을 사용하여 훈련
- GPT-3.5-TURBO-0613
- GPT-4-{0314,0613, RECENT}
- Stanford NLP reward model2, Almost reward model3: SOTA reward model
5. Experimental Results
5.1 Can Prometheus closely simulate human evaluation?
Human Evaluation과의 상관관계 측정
앞에서 언급한 Feedback bench (unseen), MT bench, Vicuna bench를 각각 45개 (총 135개) 사용하여 human annotator와 모델의 상관관계를 비교했다.

Human evaluation을 사용한 feedback 품질 비교
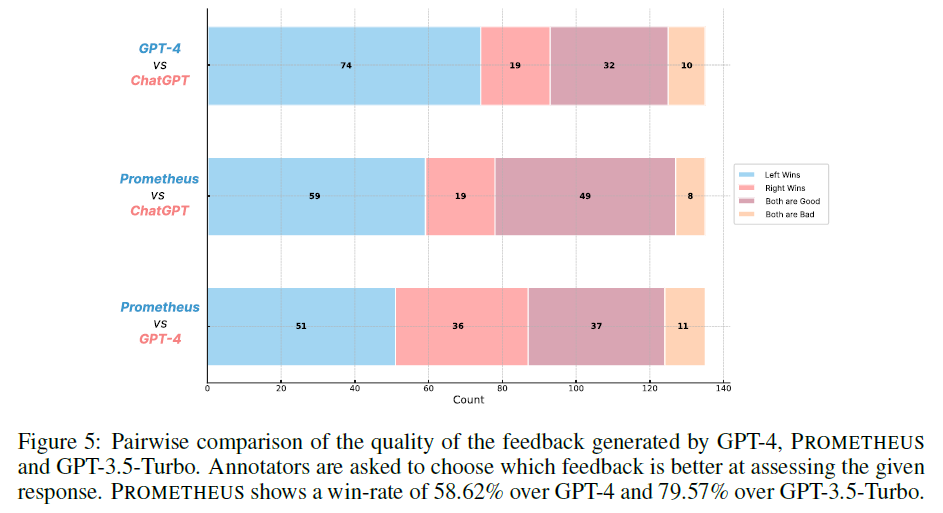
prometheus가 GPT-4보다 58.62%, GPT-3.5-Turbo 보다 79.57% 선호되는 것으로 나타났다.
Feedback 품질을 쌍으로 비교하는 것 이외에도, 아래의 6가지 옵션 중 하나 이상을 선택해 한 피드백을 다른 피드백보다 선호하지 않는 이유에 대해서도 설문을 진행했다.
Human annotator가 제공받은 설문지






GPT-4는 일반적이거나 추상적인 피드백을 제공했기 때문에 선택되지 않았다면, prometheus는 주어진 답변에 대해 너무 비판적이기 때문에 선택되지 않았다.
앞선 결과로 prometheus는 GPT-4에 비해 주어진 응답에 대한 명확한 표현을 제시한다고 볼 수 있는데, 이는 보다 세분화된 평가를 수행할 수 있도록 직접 fine-tuning하여 "generator"가 아닌 "evaluator" 로서의 역할로 전환된 결과라고 생각한다.

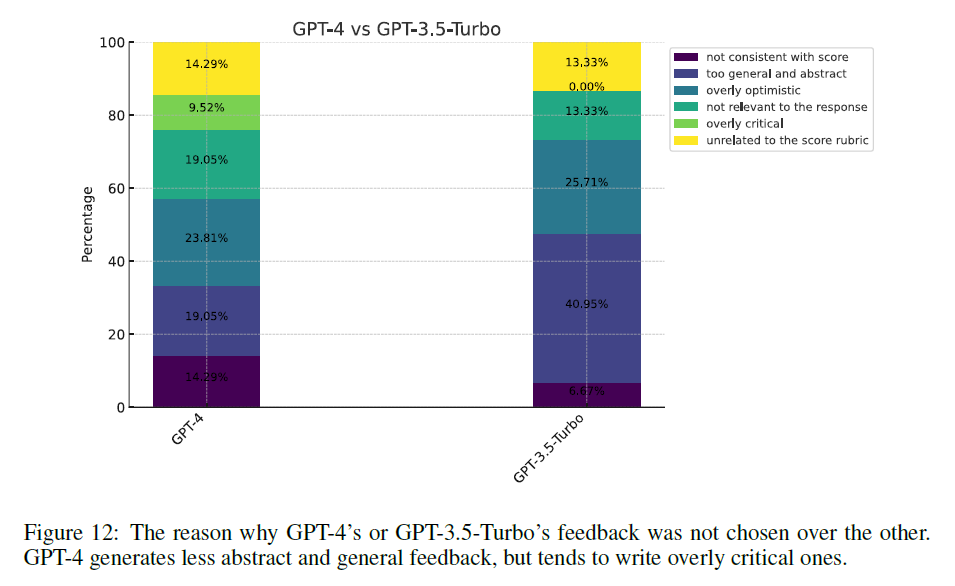
흥미롭게도 GPT-4 또한 GPT-3.5-turbo에 비해 더 비판적인 것으로 나타났고, prometheus와 gpt-3.5-turbo의 격차는 당연하게도 더욱 컸다. 이는 prometheus의 평가가 다소 비판적인 방향으로 편향되어 있을 가능성을 시사한다.
5.2 Can prometheus closely simulate GPT-4 evaluation?
GPT-4 Evaluation과의 상관관계 측정
절대 평가 세팅에서 Feedback bench (seen & unseen), vicuna bench, MT bench, Flask Eval 을 합한 총 2360개의 instance를 통해 GPT-4의 평가와 prometheus의 평가를 비교했다.
여기서 GPT-4는 자체 일관성 측정을 위해 총 6회 샘플링되었다.

- LLaMA-2-Chat-13B의 성능은 7B 모델에 비해 오히려 저하되고, 70B에서는 향상되는 것으로 나타나 모델 크기를 무작정 늘린다고 해서 평가 기능이 향상되지는 않는다는 것을 보였다
- Prometheus의 경우 기본 모델인 LLaMA-2-Chat-13B보다 월등히 높은 점수를 보였다
- 다만 여기서의 압도적인 성능 차이는 Prometheus finetuning에서 사용한 train set의 데이터 분포와 test set의 데이터 분포가 유사하기 때문일 수도 있다
- Coarse에서의 결과를 통해, LLM 사용자 맞춤형 score rubric을 처리하기 위해서는 보다 세분화된 score rubric에 대한 훈련이 중요하다는 것을 알 수 있다
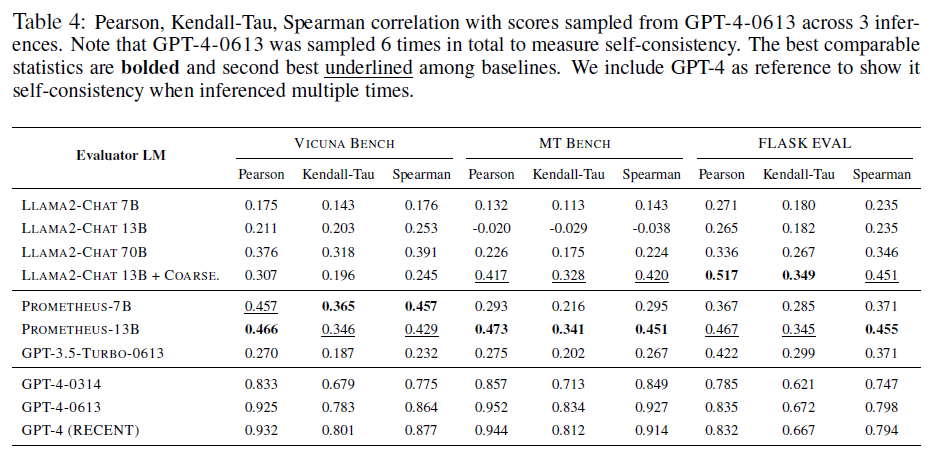
- 마찬가지로 LLaMA2-Chat에서는 용량에 따른 성능 차이가 크게 없었다
- Prometheus는 LLaMA2-Chat-70B와 GPT-3.5-turbo 보다는 성능이 뛰어나지면 GPT-4보다는 크게 떨어졌다
- 이는 Feedback collection의 instruction과 해당 평가 데이터셋들의 특성이 다르기 때문일 수도 있다.
- Feedback collection은 상대적으로 길고 상세함 (ex. I’m a city planner ... I’m looking for a novel and progressive
solution to handle traffic congestion and air problems derived from population increase) - 나머지 평가 데이터셋은 상대적으로 짧음 (ex. Can you explain about quantum mechanics?)
- Feedback collection은 상대적으로 길고 상세함 (ex. I’m a city planner ... I’m looking for a novel and progressive
- 반면 FLASK EVAL에서는 해당 데이터셋으로 훈련된 LLAMA2-Chat-13B + Coarse가 Prometheus보다 성능이 뛰어났고, 이는 해당 평가 데이터셋에서 직접 훈련하는 것이 태스크별 Evaluator LLM을 획득하는 가장 좋은 옵션일 수 있음을 나타낸다.
5.3 Can Prometheus function as a reward model?
Evaluator LM이 인간 평가자가 선호하는 응답에 더 높은 점수를 주는지 여부를 확인하기 위해 2개의 인간 선호도 데이터셋 (HHH alignment, MT Bench Human Judgement)에 대한 실험을 진행했다.

- LLaMA-2-Chat에 프롬프트를 넣는 것 만으로도 합리적인 성능을 얻을 수 있으며, 이는 기본 모델 자체가 RLHF로 훈련되었기 때문인 것으로 추측된다
- coarse로 훈련된 경우에는 오히려 성능이 저하되었다
- Prometheus는 llama2보다 좋은 성능을 보였으며, 이러한 결과는 랭킹 평가 세팅에서의 직접적인 훈련 없이도 성능 향상이 가능하다는 것을 보여주며 RLHF의 보상 모델로서 Prometheus의 사용 가능성을 시사한다
참고 문헌
- Selfee: Iterative self-revising llm empowered by self-feedback generation [본문으로]
- https://huggingface.co/stanfordnlp/SteamSHP-flan-t5-xl [본문으로]
- Aligning large language models through synthetic feedback. [본문으로]



