논문의 핵심 내용 한줄 요약
CV에서 쓰이던 Contrastive Learning을 NLP 분야에도 적용해보자!
Abstract
- 비지도 학습 : 입력 문장을 가지고 표준 dropout만 사용하는 방식. 여기에서 dropout은 일종의 data augmentation으로 작용한다.
- 지도 학습 : NLI 데이터셋을 사용해 "entailment" 를 positive pair로, "contradiction" 을 hard negative pair로 사용하는 지도학습 접근 방식을 제안한다.
STS task에서 BERT-base 모델을 기준으로 SimCSE를 평가한 결과, 76.3% (비지도) / 81.6% (지도) spearman corr를 달성해서 이전 SOTA보다 크게 향상되었다.
1. Introduction
Unsupervised SimCSE

동일한 문장을 사전 훈련된 Encoder에 두 번 전달한다.
이 때 dropout이 적용되어 있기 때문에, 같은 문장에 대한 2개의 서로 다른 임베딩을 얻을 수 있으며 이를 "positive pair"로 지칭한다.
이후 동일한 mini-batch 내의 다른 문장을 "negatives"로 가져와서 모델이 negative 사이 positive 문장을 예측할 수 있게 한다.
세부 동작 방식
DSBA review semina에 좋은 자료가 있어서 이를 참조하였다.
1. 동일한 input에 대해 서로 다른 dropout mask를 적용해 encoder에 통과시킴
-> input이 완벽히 똑같지만 dropout이 다르므로, 동일한 의미의 문장이지만 다른 임베딩이 생성됨
-> positive pair로 사용
2. Negative pair 생성을 위해 첫 번째와 다른 문장을 batch 안에 넣어줌 (in-batch negative)
이러한 접근 방식으로 얻어낸 성능은 predicting next sentence, discrete data augmentation (word deletion, replacement)과 같은 훈련 목표를 큰 차이로 능가하고 심지어 이전의 지도 학습 성능과도 비슷했다.
- predicting next sentence
BERT에서 사용된 NSP와 동일
- discrete data augmentation
단어 삭제, 순서 재배치, 유의어 대체 등의 작업을 의미
Easy Data Augmentation
Supervised SimCSE
(entailment, neutral, contradiction) 3개의 문장 쌍으로 구성된 NLI dataset을 활용한다.


entailment로 분류된 hypothesis는 positive instance로 사용하고, contradiction을 hard negative로 추가하면 성능이 더욱 향상된다는 사실을 발견했다.
SimCSE의 성능을 더 잘 평가하기 위해 선행 연구1를 참조하여 의미적 관련성이 있는 positive pairs 사이의 alignment와 전체 representation space의 uniformity를 측정하여 학습한 임베딩의 성능을 측정한 결과, 비지도 방식의 SimCSE는 alignment 저하를 방지하면서도 전체 데이터의 uniformity를 향상시켜 표현력을 개선한다는 사실을 확인했다.
2. Background : contrastive Learning
Contrastive learning은 의미적으로 가까운 이웃을 서로 끌어당기고, 그렇지 않은 이웃을 밀어내면서 효율적인 표현 방식을 배우는 것을 목표로 한다.
선행 연구의 contrastive framework를 따랐고, in-batch negative와 함께 cross entropy objective를 사용해 모델 파라미터 튜닝을 진행했다.
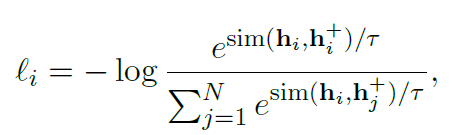
- hi,h+i : positive pair
- N : batch num
- τ : temperature hyperparameter
softmax에서 쓰는 그 temperature
-> 분포를 조금 더 뾰족하게 혹은 평평하게 만들 수 있는 파라미터
temperature 0 VS temperature 0.5 
- sim() : cosine similarity
Positive pair를 어떻게 구성할 것인가?
기존에 쓰이던 CV 분야에서는 동일한 이미지를 random transformation (cropping, flipping, distortion, rotation..) 해서 생성하는 방식으로 positive pair를 구성했다.
NLP 분야에서도 비슷한 방식의 접근 방식이 시도되었으나, 이러한 방식의 접근은 자연어 문장의 특성상 본질적 의미를 훼손할 수 있다. 따라서 이렇게 discrete operation을 적용하는 것보다 dropout을 적용하는 것이 실험에서 성능이 더 뛰어났다.
다른 접근 방식으로는 이미 생성된 supervised dataset을 활용하는 방법도 있다. 예를 들어 QA pair를 사용하는 경우, Qa 한 쌍을 자연스럽게 positive pair로 사용할 수 있다. 대신 x_i, x_i^+의 특성이 서로 다르기 때문에 이런 경우 dual-encoder framework를 사용해야 한다. sentence embedding 2 의 경우 이런 방식으로 contrastive learning을 사용한다.
Alignment and uniformity
이전 연구3에서 contrastive learning과 관련된 두 가지 핵심 속성 alignment, uniformity를 사용해 representation 품질 측정을 할 것을 제안했다.
- Alignment
주어진 positive pair의 분포인 p_pos에서, 2개의 paired instance embedding 사이의 distance를 계산한다.
(= 짧을수록 좋음)

- Uniformity
embedding이 얼마나 균일하게 분포되어 있는지 측정한다. (=균일할수록 좋음)

Alignment, Uniformity distance 모두 값이 작을수록 좋다.

contrastive learning의 목표를 다시 한 번 떠올려보자.
"의미적으로 가까운 이웃을 서로 끌어당기고, 그렇지 않은 이웃을 밀어낸다"
따라서 positive pairs는 서로 가까이 있어야 하고, random instance는 전체 공간(hypersphere) 에 균일하게 흩뿌려져 있어야 한다.
추가 설명 (How Contextual are Contextualized Word Representations?)
동일한 단어가 다른 문맥에 등장한 경우 Context에 따라 거리가 가깝지만 다른 의미를 지니는 것은 좋지만, Random word를 넣어도 contextuality를 고려하느라 의미가 비슷해져 버리는 것은 문제가 된다.
따라서 Embedding space가 hypersphere 상에서 고르게 분포하여 각 단어가 고유한 의미를 보존하는 것이 중요하다.
3. Unsupervised SimCSE
문장의 집합인 ximi=1 를 가져온 다음, 독립적으로 샘플링된 dropout mask를 사용해 x_i를 통과시켜서 각각 x_i, x_i^+를 만든다.

- z : random mask for dropout (transformer에 사용된 것과 동일)
서로 다른 dropout mask z, z' 가 적용된 encoder에 동일한 input을 각각 넣고, 2개의 서로 다른 임베딩을 얻어낸다.

- N : mini-batch 내의 문장 개수
dropout을 적용해서 2개의 서로 다른 embedding을 얻어내는 과정을 일종의 data augmentation으로 간주하여, 현존하는 다른 text data augmentation 방식과 STS-B 성능을 비교해봤다.
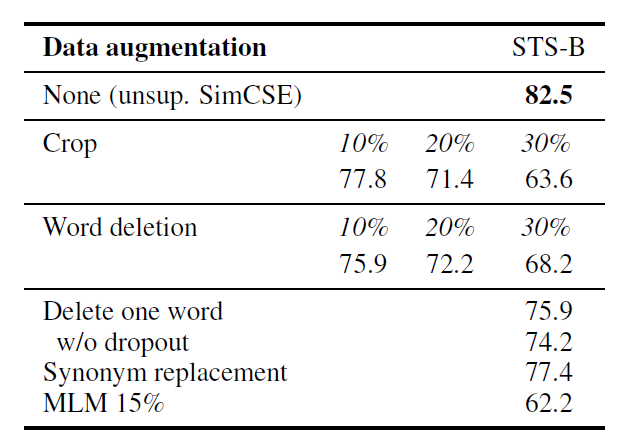
next-sentence objective와도 성능을 비교하였는데, 마찬가지로 더 우수한 성능을 보였고 SimCSE에서는 dual encoder보다 single encoder에서 더 좋은 성능을 보였다.

- 첫 번째 열 fθ 는 1개의 encoder 만 사용한 경우, 두 번째 열은 서로 다른 2개의 encoders를 사용한 경우를 나타냄
- next 3 sentences : next 3 sentences 중 1개를 랜덤 추출
- delete one word : 1개의 단어 랜덤 삭제
왜 잘 동작할까?
dropout noise가 미치는 영향을 더 자세히 이해하기 위해 다양한 dropout 비율을 시도해보았다.

- Fixed 0.1 : xi,x+i 에 동일한 dropout mask를 적용
transformer의 기본 dropout 확률인 0.1이 가장 성능이 좋았으며, dropout = 0이나 Fixed 0.1의 경우 생성된 임베딩이 동일하므로 증강 효과가 없기 때문에 성능이 매우 떨어진다.
10 training steps 마다 dot을 찍어서, 학습 경과에 따른 각 방식의 비교도 진행해보았다.

- Fixed 0.1, No dropout의 경우 alignment가 학습을 진행할수록 깨지는 것을 볼 수 있다
- delete one word 방식에서는 alignment는 지켜지지만 simCSE에 비해서 uniformity가 덜 나온다.
4. Supervised SimCSE
성능을 더욱 향상시키기 위해 기존의 supervised dataset을 활용하여 추가 학습을 진행한다.
어떤 데이터셋을 사용하는 게 positive pairs를 형성하는 데 적합할 지 평가하기 위해 총 4개의 데이터셋을 대상으로 실험을 진행했다.
- QQP : Quora question pairs
- Flickr30k : 각 이미지가 5개의 캡션으로 구성되어 있고, 그 중 2개의 캡션을 추출해서 positive pair로 사용
- ParaNMT : back translation paraphrase dataset
- NLI dataset : SNLI, MNLI

- sample : 실험에서 동등한 비교를 위해 동일하게 134k개의 positive pairs를 추출한 버전
- full : 모든 데이터셋을 사용한 버전
- 마지막 행에서는 entailment pairs를 positive로 사용하고, contradiction pairs를 hard negatives로 사용했다.
NLI 데이터셋의 성능이 sample, full 두 가지 조건 모두에서 성능이 가장 좋았으며, 그 이유는 아래와 같다.
- 고품질의 크라으두 소싱으로 구성됨
- annotator가 premise를 바탕으로 hypothesis를 수동으로 작성해야 하며, 두 문장은 어휘 중복이 적은 경향이 있기 때문
-> 실제로 2개의 BoW 사이 F1 score로 어휘 중첩도를 측정한 결과, QQP 60% / ParaNMT 55% 에 비해 SNLI + MNLI는 39%로 상대적으로 낮았음
또한 NLI가 1개의 premise에 대해 각각 entailment, neutral, contradiction인 hypothesis로 이뤄진다는 점에서 착안하여 hard negative pair를 새롭게 생성했다.
- 이전 방식 : (xi,x+i)
- 현재 방식 : (xi,x+i,x−i)
이 때 xi 는 premise, x+i는 entailment로 분류된 hypothesis, x−i는 contradiction으로 분류된 hypothesis 이다.
따라서 training objective는 다음과 같이 수정된다.
- 이전 objective
- 수정된 objective

이렇게 hard negative pair를 추가하는 것으로 의미 있는 성능 향상을 이끌어낼 수 있었다.
또한, hard negative에 가중치를 부여하는 방식도 적용해보았으나 α=1 일 때 (=가중치가 없을 때) 가 가장 성능이 좋았다.

lji : i=j일 때만 1이 됨

다른 NLI dataset (ANLI) 을 추가하는 방법, 비지도학습 방식에 적용해보는 방법도 시도해보았지만 유의미한 성능 변화를 이끌어내지 못했고, dual encoder를 시도했을 때에는 오히려 성능 저하를 보였다.
dual encoder

2개의 encoder를 사용해 각각 premise, hypothesis 삽입
5. Connection to Anisotropy
최근 연구에서는 language representation의 anisotropy problem을 지적하고 있는데, 이는 학습된 임베딩이 전체 벡터 공간에서 좁은 원뿔 형태를 차지하고, 표현력이 심각하게 제한되는 문제점을 말한다.

서로 의미가 상이한 단어도 문맥화 과정을 통해 의미가 과도하게 유사해지고, 이는 embedding space uniformity에 악영향을 끼친다.
Contrastive objective를 사용한다면, negative instances간의 거리를 멀게 하기 때문에 이러한 문제점을 자연스럽게 해결할 수 있다.
6. Experiment
- 총 7개의 STS task (STS 2012-2016, STS benchmark, SICK-relatedness) 에 대해 평가를 진행
- BERT-base (uncased), RoBERTa-base, large (cased) 사용
- [CLS] representation을 sentence embedding으로 사용
지도/비지도 학습방식 모두 [CLS] representation 위에 MLP layer를 부착해서 학습을 진행하였고 (=BERT에서의 학습 방식), 비지도학습에서는 평가를 진행할 때 MLP layer를 버리고 오직 [CLS] output만 사용했다
다른 pooling 방법에 대한 실험?
더보기
[표 6] pooling 방식에 따른 성능 차이
w/MLP (train)은 학습할 때에만 MLP를 사용하고 평가를 진행할 때에는 사용하지 않았다는 것을 의미하며 비지도 학습에서는 해당 방식이 가장 성능이 좋았다 - unsupervised SimCSE : 영문 위키피디아에서 랜덤으로 샘플링된 10^6개의 문장들로 학습
- supervised SimCSE : MNLI + SNLI 데이터셋으로 학습
Main Results

- 평가 지표 : spearman's correlation
- 데이터셋 : "all" setting
- 검은색 클로버, 흰색 하트는 이전 연구 결과에서 성능 지표를 가져왔음을 의미
나머지는 전부 reproduced 했다고 한다(역시 돈 많은게 짱이다..) - 특히 RoBERTa 모델을 사용했을 때 눈에 띄는 성능 향상을 보였다
7. Analysis
Uniformity and Alignment
다양한 임베딩 모델의 Uniformity와 alignment를 평균 STS result와 함께 그림으로 나타내었다.

- 일반적으로 alignment, uniformity이 모두 우수한 모델이 더 나은 성능을 보임
- 사전 훈련된 임베딩은 alignment는 좋지만 uniformity가 좋지 않음 (= anisotropic함)
- BERT-flow, BERT-whitening과 같은 post-processing method는 uniformity 를 크게 개선하지만 alignment가 저하됨
- unsupervised SimCSE는 uniformity를 개선함과 동시에 alignment가 유지됨
- supervised 방식은 이를 더 잘 수행함
정성적 비교
작은 스케일의 retrieval 실험을 설계해, SBERT-base, SimCSE-BERT-base 사이의 성능을 비교하였다.
Flickr30k dataset에서 150k의 caption 문장을 사용해서, 무작위 문장에 대해 코사인 유사도를 기반으로 비슷한 문장을 retrieve 하는 실험을 고안했다.

참고 문헌
- Tongzhou Wang and Phillip Isola. 2020. Understanding
contrastive representation learning through alignment and uniformity on the hypersphere. In International Conference on Machine Learning (ICML), dpages 9929–9939. [본문으로] - An efficient framework for learning sentence representations, https://openreview.net/forum?id=rJvJXZb0W [본문으로]
- Understanding contrastive representation learning through alignment and uniformity on the hypersphere. [본문으로]



