LLM Evaluation에 특화된 Open-source LLM 개발
본 논문의 기본 패러다임과 사용 데이터셋은 대부분 선행 논문을 따르므로, 논문에 대한 이전 포스팅을 읽고 오시는 것을 강력히 권장 드립니다.
[논문 Review] 14. Prometheus: Inducing Fine-grained Evaluation Capability in Language Models
GPT-4와 맞먹는 강력한 성능의 오픈소스 EvaluatorAbstract최근에는 long-form response를 평가하기 위한 Evaluator로 GPT-4와 같은 강력한 LLM을 사용하는 것이 사실상 표준이 되었다. 그러나 GPT-4는 대규모 스케
ll2ll.tistory.com
Abstract
GPT-4는 다양한 언어 모델 평가에 사용될 수 있으나, 투명성, 제어 가능성, 경제성 등의 문제로 인해 Open-source evaluator의 필요성이 대두되었다.
그러나 기존의 오픈 소스 모델은 사람의 평가 경향과 다르거나, 유연성이 부족하다는 한계점이 존재했다. Prometheus는 인간과 GPT-4의 평가를 매우 유사하게 반영하며, 사용자가 정의한 평가 기준에 따라 유연한 평가가 가능하다.
Prometheus 2는 테스트된 모든 Open-source evaluator 중에서 인간 및 Proprietary LM 판정단과 가장 높은 상관관계와 일치도를 기록했다.
1. Introduction
GPT-4는 다양한 언어 모델 평가에 사용될 수 있으나, 투명성, 제어 가능성, 경제성 등의 문제가 존재한다.
기존 오픈 소스 모델은 사람 및 GPT-4의 판단과 상관관계가 떨어지고, 특정 분야에 대해서 훈련이 되었기 때문에 다양한 분야에 적용할 만큼 유연하지 못하다는 단점이 존재한다.
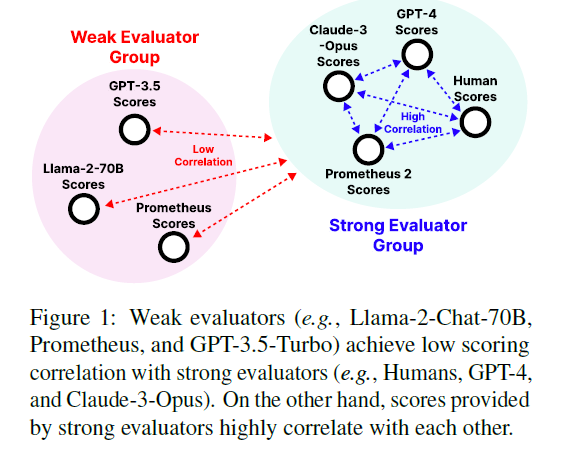
GPT-4와 같은 Proprietary LM과의 격차를 줄이기 위해, "direct assesment"와 "pairwise ranking" 라는 두 가지 평가 패러다임을 통합해 훈련하여 강력한 evaluator LM을 만든다.
본 논문에서는 각각 direct assesment, pairwise ranking 방식으로 훈련된 2개 LM의 가중치를 병합하는 방식으로 패러다임 통합을 제시했다. 이렇게 훈련할 경우, 두 방식 모두에서 잘 작동하며 단일 방식으로만 훈련된 Evaluator LM보다 성능이 뛰어나다고 한다.
- 학습 데이터셋
- direct assesment : 이전 논문에서 사용한 Feedback Collection을 사용
- pairwise ranking : Feedback Collection을 기반으로 하는 새로운 pairwise ranking feedback dataset인 Preference collection을 개발

- 사용 모델
- base model : Mistral-7B, Mixtral-8x7B
각각의 방식에서 학습을 마친 모델의 가중치를 병합하여 결과 모델인 Prometheus 2 생성
- base model : Mistral-7B, Mixtral-8x7B
- 평가 벤치마크
- direct assesment : Vicuna Bench, MT Bench, FLASK, Feedback Bench
- pairwise ranking : HHH Alignment, MT Bench Human Judgment, Auto-J Eval, Preference Bench
3. Methodology
3.1 Direct Assesment
direct assesment는 지시문 i와 응답 r을 스칼라 값 점수 s (1~5 사이의 정수) 로 매핑하는 것이다.
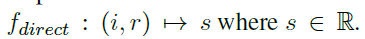
이전 연구에서 evaluator LM에게 reference answer를 추가적으로 제공해주는 것, s 앞에 feedback을 적도록 유도하는 등의 방법으로 사람과 LM의 평가 차이를 줄일 수 있다는 것을 보였다.
또한 다양한 태스크에 대한 평가 기준을 통합하는 것으로 모델의 유연성을 기를 수 있다고 주장했다.

여기서 a는 reference answer, e는 score rubric을 의미한다.
- score rubric : 평가 기준에 대한 설명, 점수 범위 사이의 각 점수에 대한 설명

- reference answer : 5점을 받을 수 있는 참조 답안. 평가자가 reference answer - response 사이의 상호 정보를 사용해서 채점할 수 있도록 함

3.2 Pairwise Ranking
pairwise ranking은 지시문 i와 답안 쌍 \(r_m, r_n\)을 s로 매핑하는 것이다.
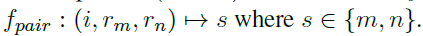
direct assesment와 유사하게, reference answer와 feedback을 평가 과정에 포함시키는 것이 중요하다는 게 선행연구에서 밝혀졌다.
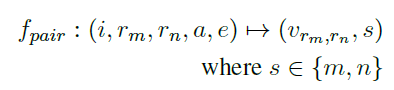
여기서 \(v_{r_m}, v_{r_n}\)은 각각 \(r_m, r_n\)에 대한 feedback을 의미한다.
- feedback : 답변이 특정 점수를 받는 이유에 대한 근거

이 때 pairwise ranking에서는 evaluation criteria e에 점수 범위 사이의 각 점수에 대한 설명은 따로 들어가지 않고 평가 기준 자체에 대한 설명만 포함된다.
또한 \(v_r_m, v_r_n\)에서 e에 대한 \(r_m, r_n\)의 공통점과 차이점을 비교하는 것도 주목할 만한 점이다.
3.3 The preference Collection
HH-RLHF나 Ultra Feedback과 같이 널리 사용되는 pairwise ranking 데이터셋에서는 evaluation criteria, feedback이 포함되어 있지 않다. 따라서 기존의 Feedback Collection 데이터셋을 기반으로 1K개의 evaluation criteria를 포함하고 있는 preference collection을 구축했다.
Construction Process
Feedback Collection에 다음과 같은 수정 사항을 적용해서 새로운 데이터셋인 Preference Collection을 구축했다.
- Feedback Collection에서는 각 Instruction에 대해 5개의 response가 포함되며, 각 응답은 1~5 사이의 점수에 해당된다.
- 5개의 응답 중 2개를 짝지어 총 10개의 조합을 생성하고, 어떤 응답이 더 나은지 결정해 pairwise ranking에 맞는 새로운 label ("응답 A가 좋음", "응답 B가 좋음") 을 할당
- 각 response pair에 대해 새로운 feedback을 생성하기 위해 GPT-4에 두 response 간의 공통점과 차이점을 찾아내라는 지시를 넣어줌
Feedback Collection dataset 예시
https://huggingface.co/datasets/prometheus-eval/Feedback-Collection
Instruction format
###Task Description:
An instruction (might include an Input inside it), a response to evaluate, a reference answer that gets a score of 5, and a score rubric representing a evaluation criteria are given.
1. Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general.
2. After writing a feedback, write a score that is an integer between 1 and 5. You should refer to the score rubric.
3. The output format should look as follows: \"Feedback: (write a feedback for criteria) [RESULT] (an integer number between 1 and 5)\"
4. Please do not generate any other opening, closing, and explanations.
###The instruction to evaluate:
{orig_instruction}
###Response to evaluate:
{orig_response}
###Reference Answer (Score 5):
{orig_reference_answer}
###Score Rubrics:
[{orig_criteria}]
Score 1: {orig_score1_description}
Score 2: {orig_score2_description}
Score 3: {orig_score3_description}
Score 4: {orig_score4_description}
Score 5: {orig_score5_description}
###Feedback:
데이터셋 예시
- instruction: The input that is given to the evaluator LM. It includes the instruction & response to evaluate, the reference answer, the score rubric.
ex. ###Task Description: An instruction (might include an Input inside it), a response to evaluate, a reference answer that gets a score of 5, ... ###The instruction to evaluate: You are a well-known psychiatrist who has a reputation for being empathetic and understanding. ... How do you respond to them to make them feel heard and understood, as well as offering helpful advice? ###Response to evaluate: It's indeed challenging to deal with a difficult boss and to carry a large workload, ... ###Reference Answer (Score 5): I hear that you're dealing with quite a few challenging situations at once. ###Score Rubrics: [Is the model able to identify and react correctly to the emotional context of the user's input?] Score 1: The model utterly fails to grasp the user's emotional context and responds in an unfitting manner. Score 2: ... ###Feedback: - output: The output that the evaluator LM should generate. It includes the feedback and score decision divided by a phrase [RESULT].
ex. The response was generally on point with acknowledging the emotional context of the client's struggles. However, ...The advice provided about managing workload and dealing with loneliness was quite generic and could have been more personalized to the client's situation. So the overall score is 3. [RESULT] 3 - orig_instruction: The instruction to be evaluated. Note that this differs with the instruction that includes all the components.
ex. You are a well-known psychiatrist who has a reputation for being empathetic and understanding. - orig_response: The response to be evaluated.
ex. It's indeed challenging to deal with a difficult boss and to carry a large workload, - orig_reference_answer: A reference answer to the orig_instruction.
ex. I hear that you're dealing with quite a few challenging situations at once. It must be tough to have your ideas dismissed by your boss and to feel undervalued in your work environment. - orig_criteria: The score criteria used to evaluate the orig_ response.
ex. Is the model able to identify and react correctly to the emotional context of the user's input? - orig_score1_description: A description of when to give a score of 1 to the orig_response.
ex. The model utterly fails to grasp the user's emotional context and responds in an unfitting manner. - orig_score2_description: A description of when to give a score of 2 to the orig_response.
- orig_score3_description: A description of when to give a score of 3 to the orig_response.
ex. The model typically identifies the emotional context and reacts suitably, but occasionally misreads or misjudges the user's feelings. - orig_score4_description: A description of when to give a score of 4 to the orig_response.
- orig_score5_description: A description of when to give a score of 5 to the orig_response.
ex. The model flawlessly identifies the emotional context of the user's input and consistently responds in a considerate and empathetic manner. - orig_feedback: A feedback that critiques the orig_response.
ex. The response was generally on point with acknowledging the emotional context of the client's struggles. However, the therapist failed to express empathy towards the client's feelings of ... - orig_score: An integer between 1 and 5 given to the orig_response.
ex. 3
Preference Collection dataset 예시
https://huggingface.co/datasets/prometheus-eval/Preference-Collection
Prompt format
###Task Description:
An instruction (might include an Input inside it), a response to evaluate, and a score rubric representing a evaluation criteria are given.
1. Write a detailed feedback that assess the quality of two responses strictly based on the given score rubric, not evaluating in general.
2. After writing a feedback, choose a better response between Response A and Response B. You should refer to the score rubric.
3. The output format should look as follows: "Feedback: (write a feedback for criteria) [RESULT] (A or B)"
4. Please do not generate any other opening, closing, and explanations.
###Instruction:
{orig_instruction}
###Response A:
{orig_response_A}
###Response B:
{orig_response_B}
###Reference Answer:
{orig_reference_answer}
###Score Rubric:
{orig_criteria}
###Feedback:
데이터셋 예시
- orig_criteria : Is the answer well supported with evidence, including citations/attributions wherever relevant?\
- orig_feedback_A : The response given lacks relevant citations. ...
- orig_feedback_B : The response is well-articulated and completely supported with ...
- orig_instruction : A group of historians are conducting a debate on the factors that led to the fall of the Roman Empire. ... How would the historian arguing for economic troubles and overreliance on slave labor present their case?
- orig_reference_answer : This argument focuses on the economic troubles and overreliance on slave labor as primary reasons for the fall of the Roman Empire. ...
- orig_response_A : The historian arguing that economic troubles and overreliance on slave labor led to the fall of the Roman Empire would say this:
- orig_response_B : The historian arguing for economic troubles and overreliance on slave labor ...
- orig_score_A : 2
- orig_score_B : 5
- orig_preference : B
- output : In evaluating the provided responses, both historians make the argument that economic factors such as currency devaluation, the overreliance on slave labor, and trade deficits played pivot ... [RESULT] B
Statistics
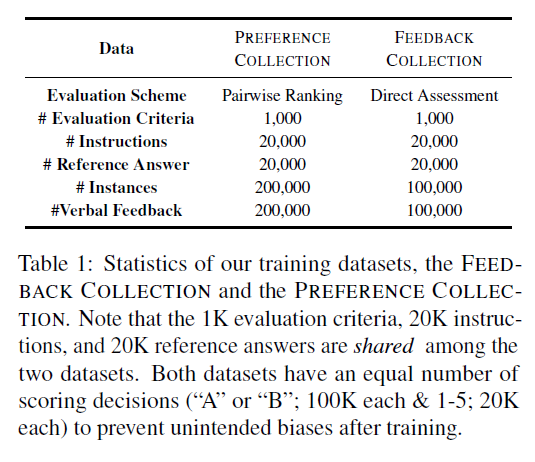
Quality verification process
생성된 feedback의 품질 검증을 위해 5명의 human annotator 고용
200개의 인스턴스를 무작위로 샘플링하고, 3단계로 구성된 검증 프로세스 수행
- \(v_{r_m}, v_{r_n}\)의 일관성과 점수 결정 (A가 낫다 / B가 낫다) 평가
- 평가 기준 e에 대한 \(v_{r_m}, v_{r_n}\)의 적합성 평가
- feedback의 중요도를 파악하기 위해 새로 생성된 \(v_{r_m}, v_{r_n}\)을 \(r_m,r_n\)의 concat과 비교. annotator는 \(v_{r_m}, v_{r_n}\)과 \(r_m,r_n\) concat 중 어떤 것이 더 중요한지 투표한다.

Prompts for augmentation process

3.4 Employing Evaluator Language Models
- Prompt : Feedback Collection에 대한 학습 없이 LM에게 지정된 평가 형식으로 판단을 내리도록 쿼리
- Single-Format Training : direct assesment dataset (=Feedback Collection = \(D_d\)) 또는 pairwise ranking dataset (= Preference Collection = \(D_p\)) 에 대한 기본 모델 \(\theta\)을 훈련
- Joint Training : \(D_d\) , \(D_p\) 을 통해 기본 모델 \(\theta\) 을 훈련
- Weight Merging : \(D_d\) , \(D_p\) 에 대해 두 모델 \(\theta_d\)와 \(\theta_p\)를 개별적으로 학습시킨 다음 linear merging을 통해 최종 모델인 \(\theta_{final}\) 을 구함

\(\alpha\)의 변화에 따른 성능 변화
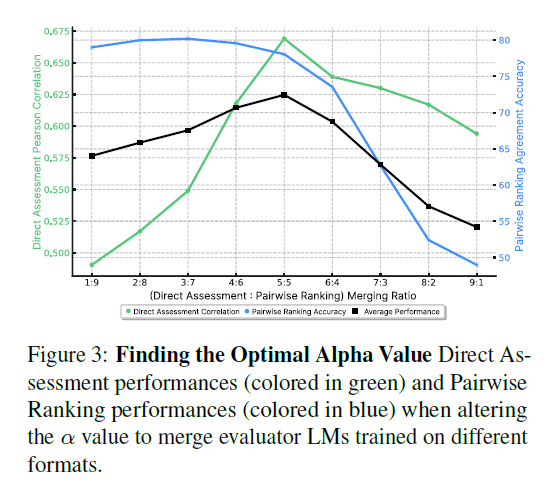
이후 실험에 쓰인 8가지 벤치마크를 모두 사용해 평균 성능을 측정한 결과 (\\alpha = 0.5\) 일 때 최고의 성능을 나타내고, 이는 각각의 학습 데이터가 성능에 동등하게 기여한다는 것을 나타낸다.
pairwise 벤치마크의 경우 (\alpha=0.3\)일 때 성능이 최고인데, 이는 pairwise ranking에 대한 훈련이 direct assesment task에 대한 성능을 유의미하게 향상시키는 것을 의미한다.
linear merging 이외에도 다양한 merging 기법을 시도해보았다.
- Task Arithmetic merging1
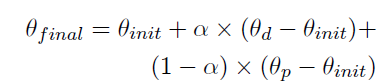
init은 기본 모델의 가중치
그러나 해당 기법을 사용한 모델은 종종 유효한 점수 결정을 내리지 못했음 - TIES merging2
Task merging과 유사하지만, \(\theta_d - \theta_{init}\)과 \(\theta_p - \theta_{init}\)에서 중복 가중치를 제거하는 trim 연산과 \(\theta_d - \theta_{init}\)과 \(\theta_p - \theta_{init}\) 사이의 불일치를 해결하기 위한 elect, disjoint 연산이 추가됨 - DARE merging3
Task merging, TIES merging과 유사하지만 random drop, rescaling 작업을 통해서 중복 가중치를 제거
-> 기본 모델로 Mixtral-8x7B를 사용할 때 가장 잘 작동하는 방식
4. Experimental setup
4.1 Benchmarks and Metrics

Direct Assesment benchmark
- Vicuna bench : single-turn chat benchmark
80개의 test prompts, score-rubrics / 각각의 LM (WizartLM-13B, Vicuna-13B, Llama2-chat=13b, GPT-3.5) 에서 얻은 320개의 response를 포함 - MT bench : Multi-turn chat benchmark
80개의 test prompts, score-rubrics / 각각의 LM (WizartLM-13B, Vicuna-13B, Llama2-chat=13b, GPT-3.5) 에서 얻은 320개의 response를 포함 - FLASK : fine-grained evaluation benchmark
200개의 test prompts, 12개의 score rubrics / 각각의 LM (Alpaca-7B, Vicuna-13B, Bard, GPT-3.5) 에서 얻은 2000개의 response, 사람 평가자의 response 포함 - Feedback bench
Feedback Collection의 test dataset
Pairwise Ranking benchmark
- HHH alignment : 221개의 prompts, 4개의 score rubrics (helpfulness, harmlessness, honesty,
and other), 인간 평가자가 평가한 221개의 response pairs (graded as ‘win’ or ‘lose’ ) - MT bench human judgement : MT-bench와 동일한 80개의 프롬프트를 공유하는 벤치마크
인간 평가자가 판단한 3360개의 response pairs (graded as ‘win’, ‘tie’, or ‘lose’) - Auto-J Eval : 58개의 prompts, 인간 평가자가 판단한 1392개의 response pairs (graded as ‘win’, ‘tie’, or ‘lose’)
- Preference bench
Preference Collection의 test dataset
평가 방식 차이?
Direct assesment
- reference answer를 input에 추가해 평가를 수행
- 기준이 되는 평가자 (GPT-4, human) 와의 점수 상관관계 측정을 위해 pearson, spearman, kendall-tau 사용
Pairwise ranking
- reference 없이 평가를 진행
- human judgement를 바탕으로 accuracy를 측정
- 'tie' 는 모두 제거 ('w/o tie') / 'tie' 에 direct assesment를 시행한 이후 응답을 pairwise ranking 으로 평가
4.2 Baselines
사용 모델
Prompting Baselines
- Llama-2-chat-7,13,70B
- Mistral-7B-Instruct- v0.2
- Mixtral-8x7B-Instruct-v0.1
Feedback Collection data에 대해 학습되지 않은 모델은 종종 필요한 형식의 direct assesment를 생성하지 못했기에, 점수를 원하는 형식으로 출력할 때까지 무한 반복해서 비교를 수행
Single-format Trained Evaluator LMs
- direct assesment : Prometheus-7,13B, Mistral-7B-Instruct-v0.2, Mixtral-8x7B-Instruct-v0.1
- pairwise ranking : UltraRM-13B, PairRM-0.4B, Mistral-7B-Instruct-v0.2, Mixtral-8x7B-Instruct-v0.1
Jointly Trained Evaluator LMs
- Auto-J, Mistral-7B, Mixtral-8x7B
Weight Merging
- PROMETHEUS 2 (7B & 8x7B)
사용 하이퍼파라미터
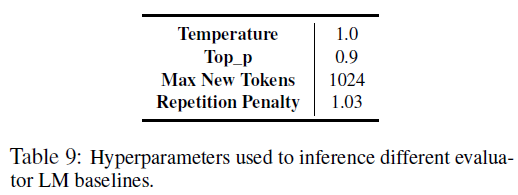

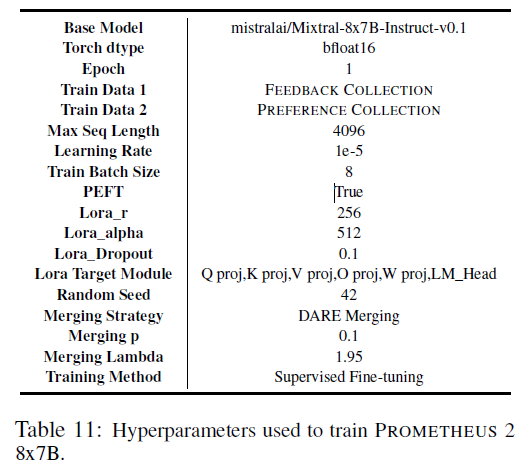
사용 프롬프트
Direct Assessment Prompt

Pairwise Ranking Prompt


5. Experimental Results
5.1 Direct Assessment Results
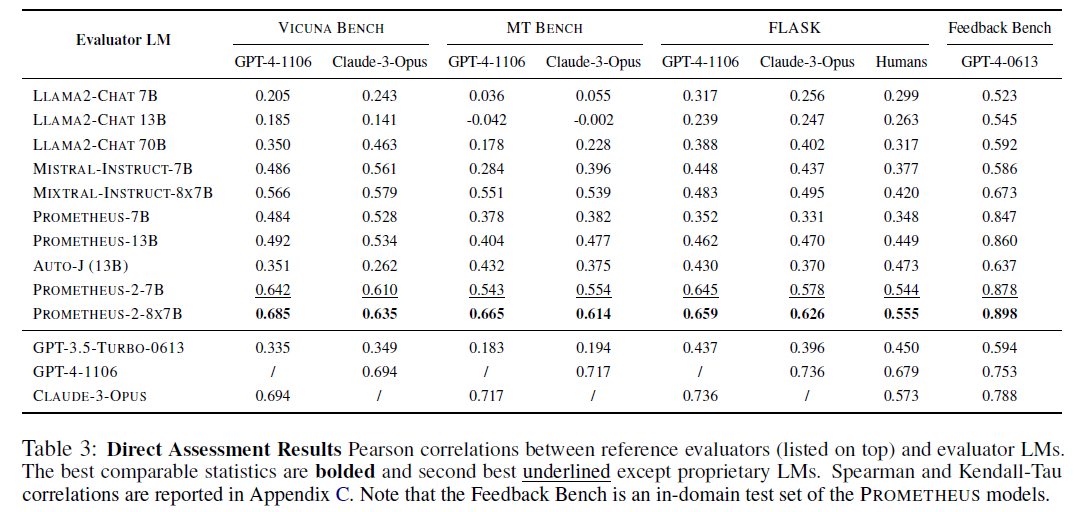
- PROMETHEUS-2 models (7B & 8x7B), GPT-4-1106, Claude-3-Opus, human evaluators는 모두 서로 강한 상관관계를 보이며, 기준 평가자와 벤치마크에 상관 없이 0.5 이상의 corr 보임
- 나머지는 GPT-4-1106, Claude-3-Opus, human evaluators와 낮은 상관관계를 보이며 대부분 0.5 미만의 corr 보임
- PROMETHEUS-2는 모든 벤치마크에서 Prometheus-1, Auto-J보다 0.2 이상 성능이 뛰어남
- 특히 PROMETHEUS-2-8x7B는 인간과의 격차를 0.555로 줄였음
5.2 Pairwise Ranking Results

- Pair RM, Ultra RM은 'tie' 옵션 제공이 불가능하므로 제외함
- HHH alignment는 pair RM을 위한 test set이고, auto-J는 auto-J 모델을 위한 test set임에도 불구하고 Prometheus-2-8x7B가 더 높은 점수를 획득함
5.3 Consistency Across Evaluation Formats
높은 상관관계, 정확도 달성 이외에도 일관적으로 점수를 평가할 수 있는지가 중요하다.
따라서 Evaluator LM이 다양한 평가 형식에 걸쳐 일관된 점수를 얻을 수 있는지 테스트한다.
pairwise ranking benchmark를 사용하고, direct assesment 형식과 pairwise ranking 형식을 제시했을 때 성능 차이를 측정한다.
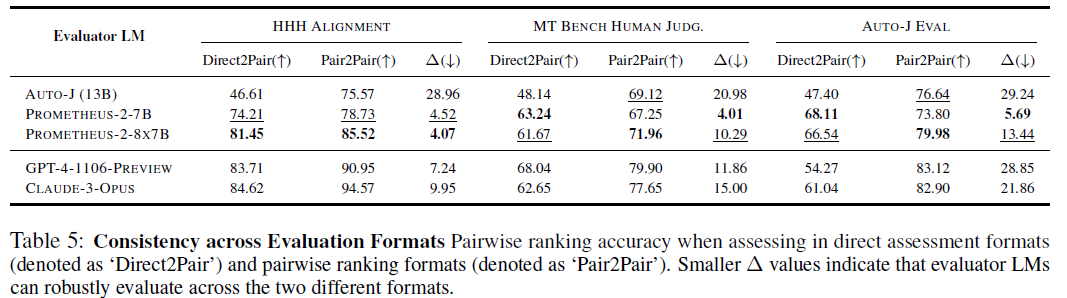
- PROMETHEUS-2는 평가 형식에 따른 성능 차이가 적다는 것을 보여주고, 이는 evaluator LM이 robust 하다는 것을 나타냄
6. Discuss
6.1 Weight Merging vs Joint Training
Weight Merging이 Joint Training에 비해 효과적인가?
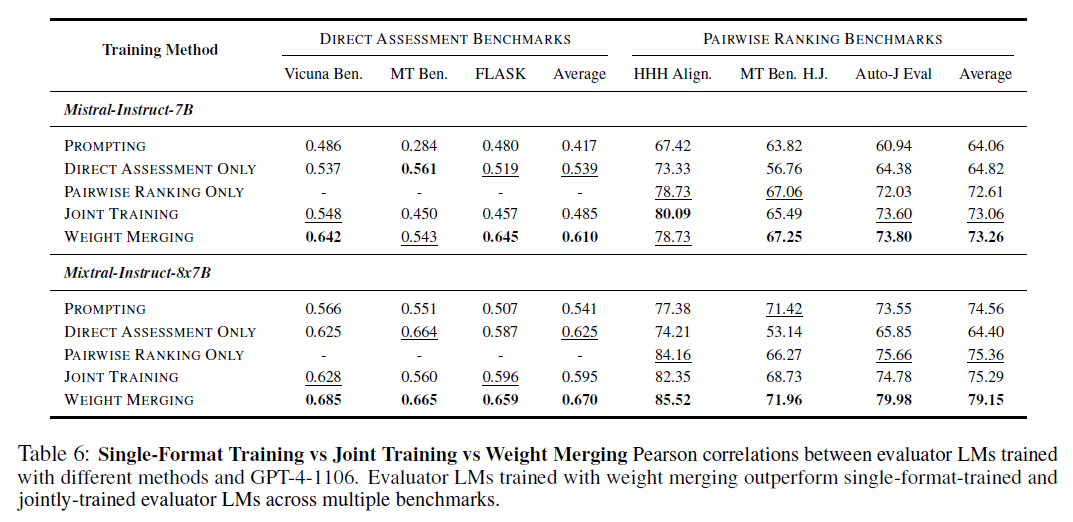
- Joint training이 single-format training보다도 낮은 정답률을 보이는 경우가 많음
- 반면, Weight merging 방식은 우수한 성능을 보임
6.2 Is the Effectiveness of Weight Merging due to Model Ensembling?
Weight merging 방식의 성능이 좋은 이유는 모델 앙상블때문인가?
- 경험적으로 weight merging이 효과적으로 작동하는 것이 밝혀졌으나, 그 이유는 명확하지 않음
- 한 가지 가정은 weight merging이 앙상블 효과를 낸다는 것
- 가설의 타당성을 확인하고자 evaluator LM (Mistral-7B-Instruct) 을 무작위 시드에 대해서 훈련하고 merging
- Direct Assessment & Direct Assessment : direct assesment format에서 학습된 2개의 evaluator LM merge
- Pairwise Ranking & Pairwise Ranking : pairwise ranking format에서 학습된 2개의 evaluator LM merge
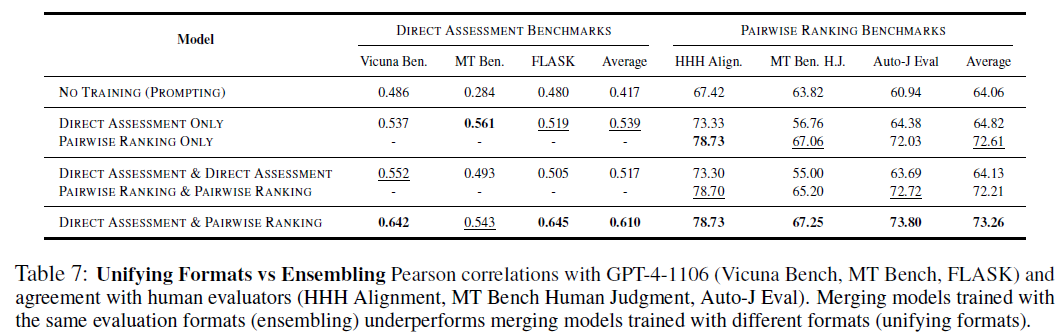
- 예상과 달리 대부분의 경우 동일한 평가 형식으로 훈련된 Evaluator LM을 병합해도 평가 성능이 향상되지 않음
- 특히 direct assesment 의 경우 성능이 저하됨
- Direct Assessment, Pairwise Ranking 에서 각각 훈련된 모델을 병합할 경우 우수한 성능을 보임
-> positive task trasnfer는 evaluation format을 통합하며 이루어지는 것이지, 앙상블을 통해 이루어지는 것이 아님
참고 문헌
- Gabriel Ilharco, Marco Tulio Ribeiro, Mitchell Wortsman, Suchin Gururangan, Ludwig Schmidt, Hannaneh Hajishirzi, and Ali Farhadi. 2022. Editing models with task arithmetic. arXiv preprint
arXiv:2212.04089. [본문으로] - Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. 2024. Ties-merging: Resolving interference when merging models. Advances in Neural Information Processing Systems, 36. [본문으로]
- Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. 2023. Language models are super mario: Absorbing abilities from homologous models as a free lunch. arXiv preprint arXiv:2311.03099. [본문으로]



